 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePD-Loss: Proxy-Decidability for Efficient Metric Learning
Aug 23, 2025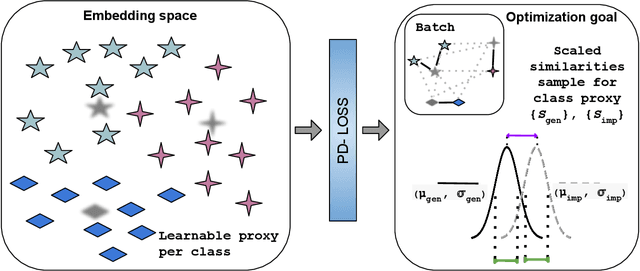

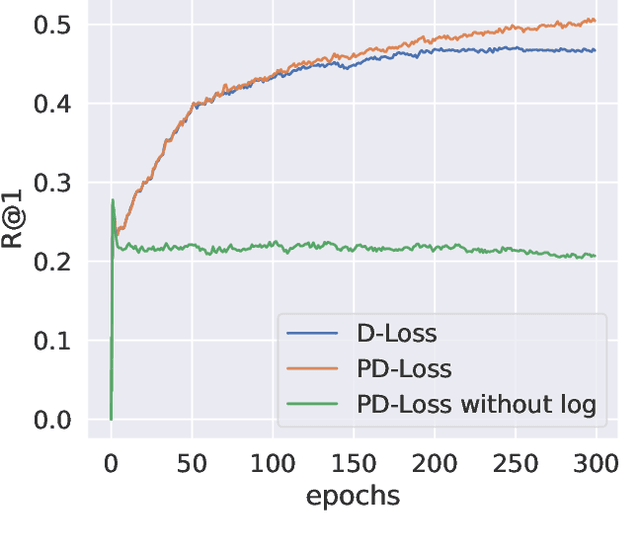
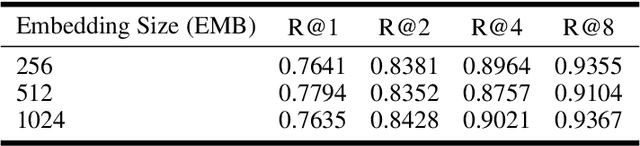
Deep Metric Learning (DML) aims to learn embedding functions that map semantically similar inputs to proximate points in a metric space while separating dissimilar ones. Existing methods, such as pairwise losses, are hindered by complex sampling requirements and slow convergence. In contrast, proxy-based losses, despite their improved scalability, often fail to optimize global distribution properties. The Decidability-based Loss (D-Loss) addresses this by targeting the decidability index (d') to enhance distribution separability, but its reliance on large mini-batches imposes significant computational constraints. We introduce Proxy-Decidability Loss (PD-Loss), a novel objective that integrates learnable proxies with the statistical framework of d' to optimize embedding spaces efficiently. By estimating genuine and impostor distributions through proxies, PD-Loss combines the computational efficiency of proxy-based methods with the principled separability of D-Loss, offering a scalable approach to distribution-aware DML. Experiments across various tasks, including fine-grained classification and face verification, demonstrate that PD-Loss achieves performance comparable to that of state-of-the-art methods while introducing a new perspective on embedding optimization, with potential for broader applications.
A Systematic Review of ECG Arrhythmia Classification: Adherence to Standards, Fair Evaluation, and Embedded Feasibility
Mar 10, 2025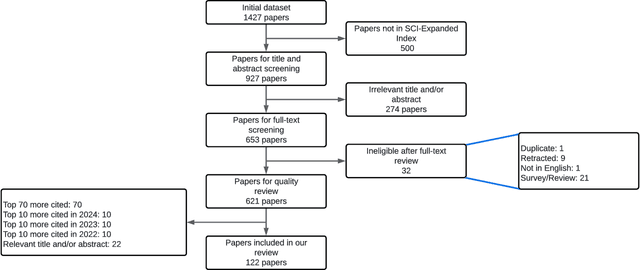

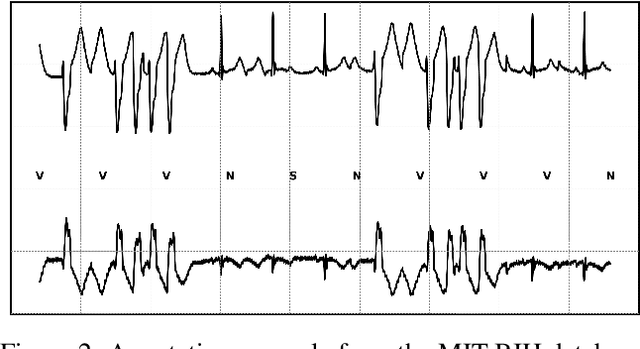
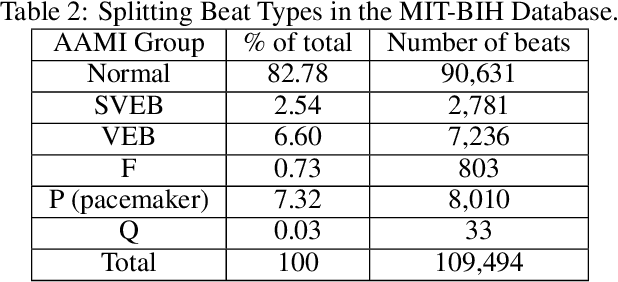
The classification of electrocardiogram (ECG) signals is crucial for early detection of arrhythmias and other cardiac conditions. However, despite advances in machine learning, many studies fail to follow standardization protocols, leading to inconsistencies in performance evaluation and real-world applicability. Additionally, hardware constraints essential for practical deployment, such as in pacemakers, Holter monitors, and wearable ECG patches, are often overlooked. Since real-world impact depends on feasibility in resource-constrained devices, ensuring efficient deployment is critical for continuous monitoring. This review systematically analyzes ECG classification studies published between 2017 and 2024, focusing on those adhering to the E3C (Embedded, Clinical, and Comparative Criteria), which include inter-patient paradigm implementation, compliance with Association for the Advancement of Medical Instrumentation (AAMI) recommendations, and model feasibility for embedded systems. While many studies report high accuracy, few properly consider patient-independent partitioning and hardware limitations. We identify state-of-the-art methods meeting E3C criteria and conduct a comparative analysis of accuracy, inference time, energy consumption, and memory usage. Finally, we propose standardized reporting practices to ensure fair comparisons and practical applicability of ECG classification models. By addressing these gaps, this study aims to guide future research toward more robust and clinically viable ECG classification systems.
A Decidability-Based Loss Function
Sep 12, 2021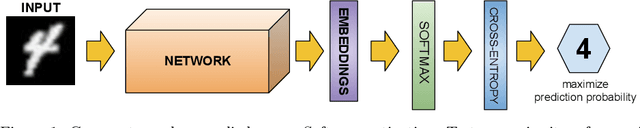
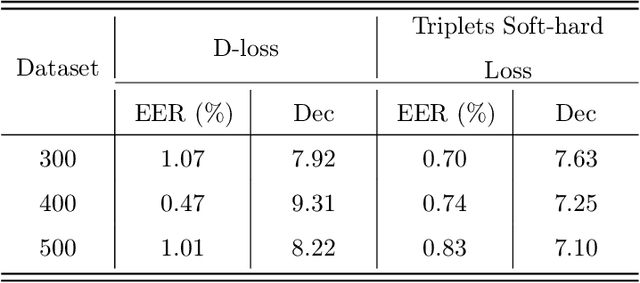
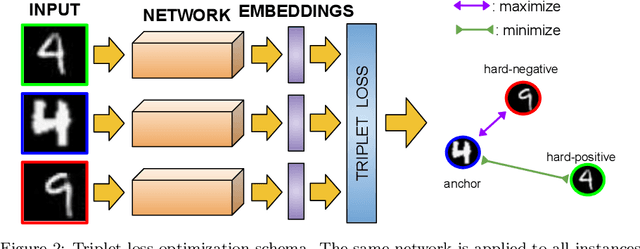

Nowadays, deep learning is the standard approach for a wide range of problems, including biometrics, such as face recognition and speech recognition, etc. Biometric problems often use deep learning models to extract features from images, also known as embeddings. Moreover, the loss function used during training strongly influences the quality of the generated embeddings. In this work, a loss function based on the decidability index is proposed to improve the quality of embeddings for the verification routine. Our proposal, the D-loss, avoids some Triplet-based loss disadvantages such as the use of hard samples and tricky parameter tuning, which can lead to slow convergence. The proposed approach is compared against the Softmax (cross-entropy), Triplets Soft-Hard, and the Multi Similarity losses in four different benchmarks: MNIST, Fashion-MNIST, CIFAR10 and CASIA-IrisV4. The achieved results show the efficacy of the proposal when compared to other popular metrics in the literature. The D-loss computation, besides being simple, non-parametric and easy to implement, favors both the inter-class and intra-class scenarios.