 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Forecasting Using Fuzzy Cognitive Maps: A Survey
Jan 10, 2022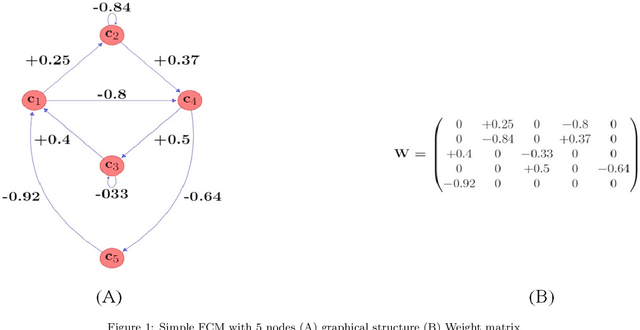
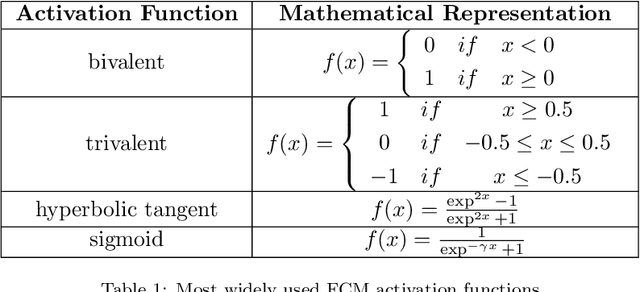

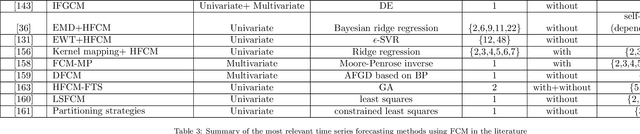
Among various soft computing approaches for time series forecasting, Fuzzy Cognitive Maps (FCM) have shown remarkable results as a tool to model and analyze the dynamics of complex systems. FCM have similarities to recurrent neural networks and can be classified as a neuro-fuzzy method. In other words, FCMs are a mixture of fuzzy logic, neural network, and expert system aspects, which act as a powerful tool for simulating and studying the dynamic behavior of complex systems. The most interesting features are knowledge interpretability, dynamic characteristics and learning capability. The goal of this survey paper is mainly to present an overview on the most relevant and recent FCM-based time series forecasting models proposed in the literature. In addition, this article considers an introduction on the fundamentals of FCM model and learning methodologies. Also, this survey provides some ideas for future research to enhance the capabilities of FCM in order to cover some challenges in the real-world experiments such as handling non-stationary data and scalability issues. Moreover, equipping FCMs with fast learning algorithms is one of the major concerns in this area.
Introducing Randomized High Order Fuzzy Cognitive Maps as Reservoir Computing Models: A Case Study in Solar Energy and Load Forecasting
Jan 07, 2022



Fuzzy Cognitive Maps (FCMs) have emerged as an interpretable signed weighted digraph method consisting of nodes (concepts) and weights which represent the dependencies among the concepts. Although FCMs have attained considerable achievements in various time series prediction applications, designing an FCM model with time-efficient training method is still an open challenge. Thus, this paper introduces a novel univariate time series forecasting technique, which is composed of a group of randomized high order FCM models labeled R-HFCM. The novelty of the proposed R-HFCM model is relevant to merging the concepts of FCM and Echo State Network (ESN) as an efficient and particular family of Reservoir Computing (RC) models, where the least squares algorithm is applied to train the model. From another perspective, the structure of R-HFCM consists of the input layer, reservoir layer, and output layer in which only the output layer is trainable while the weights of each sub-reservoir components are selected randomly and keep constant during the training process. As case studies, this model considers solar energy forecasting with public data for Brazilian solar stations as well as Malaysia dataset, which includes hourly electric load and temperature data of the power supply company of the city of Johor in Malaysia. The experiment also includes the effect of the map size, activation function, the presence of bias and the size of the reservoir on the accuracy of R-HFCM method. The obtained results confirm the outperformance of the proposed R-HFCM model in comparison to the other methods. This study provides evidence that FCM can be a new way to implement a reservoir of dynamics in time series modelling.
Combining Embeddings and Fuzzy Time Series for High-Dimensional Time Series Forecasting in Internet of Energy Applications
Dec 03, 2021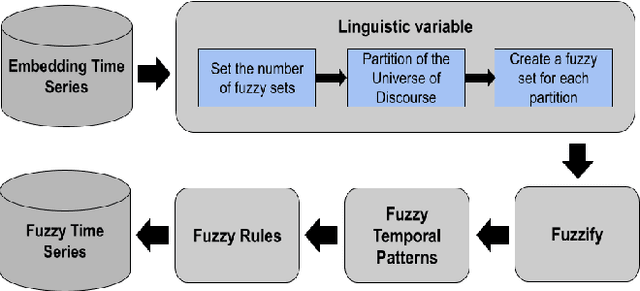



The prediction of residential power usage is essential in assisting a smart grid to manage and preserve energy to ensure efficient use. An accurate energy forecasting at the customer level will reflect directly into efficiency improvements across the power grid system, however forecasting building energy use is a complex task due to many influencing factors, such as meteorological and occupancy patterns. In addiction, high-dimensional time series increasingly arise in the Internet of Energy (IoE), given the emergence of multi-sensor environments and the two way communication between energy consumers and the smart grid. Therefore, methods that are capable of computing high-dimensional time series are of great value in smart building and IoE applications. Fuzzy Time Series (FTS) models stand out as data-driven non-parametric models of easy implementation and high accuracy. Unfortunately, the existing FTS models can be unfeasible if all features were used to train the model. We present a new methodology for handling high-dimensional time series, by projecting the original high-dimensional data into a low dimensional embedding space and using multivariate FTS approach in this low dimensional representation. Combining these techniques enables a better representation of the complex content of multivariate time series and more accurate forecasts.
High-dimensional Multivariate Time Series Forecasting in IoT Applications using Embedding Non-stationary Fuzzy Time Series
Jul 20, 2021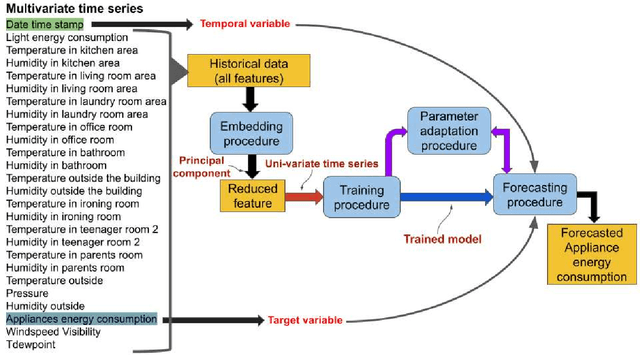

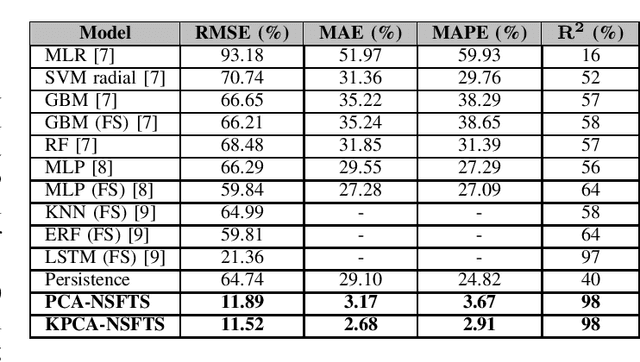
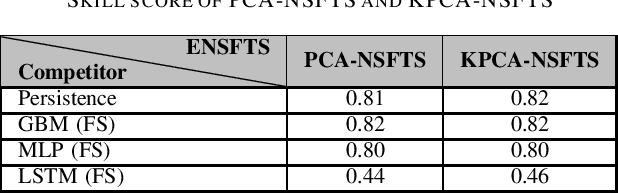
In Internet of things (IoT), data is continuously recorded from different data sources and devices can suffer faults in their embedded electronics, thus leading to a high-dimensional data sets and concept drift events. Therefore, methods that are capable of high-dimensional non-stationary time series are of great value in IoT applications. Fuzzy Time Series (FTS) models stand out as data-driven non-parametric models of easy implementation and high accuracy. Unfortunately, FTS encounters difficulties when dealing with data sets of many variables and scenarios with concept drift. We present a new approach to handle high-dimensional non-stationary time series, by projecting the original high-dimensional data into a low dimensional embedding space and using FTS approach. Combining these techniques enables a better representation of the complex content of non-stationary multivariate time series and accurate forecasts. Our model is able to explain 98% of the variance and reach 11.52% of RMSE, 2.68% of MAE and 2.91% of MAPE.
Applying Genetic Programming to Improve Interpretability in Machine Learning Models
May 18, 2020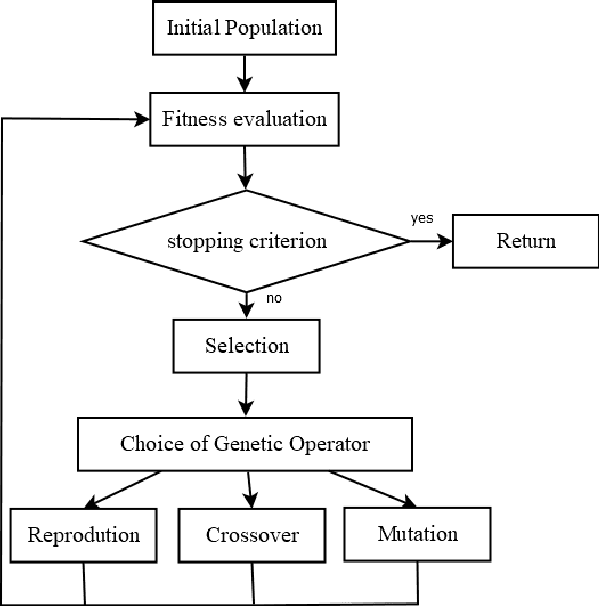
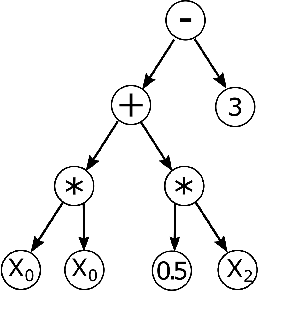
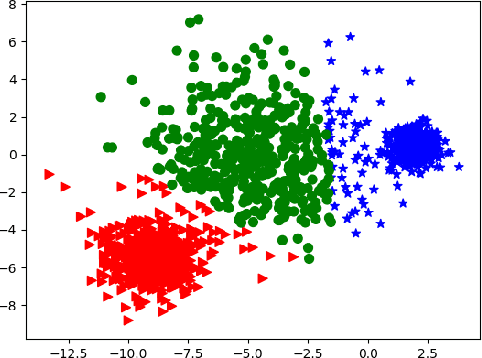
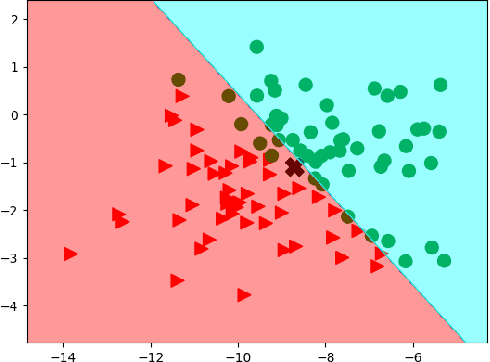
Explainable Artificial Intelligence (or xAI) has become an important research topic in the fields of Machine Learning and Deep Learning. In this paper, we propose a Genetic Programming (GP) based approach, named Genetic Programming Explainer (GPX), to the problem of explaining decisions computed by AI systems. The method generates a noise set located in the neighborhood of the point of interest, whose prediction should be explained, and fits a local explanation model for the analyzed sample. The tree structure generated by GPX provides a comprehensible analytical, possibly non-linear, symbolic expression which reflects the local behavior of the complex model. We considered three machine learning techniques that can be recognized as complex black-box models: Random Forest, Deep Neural Network and Support Vector Machine in twenty data sets for regression and classifications problems. Our results indicate that the GPX is able to produce more accurate understanding of complex models than the state of the art. The results validate the proposed approach as a novel way to deploy GP to improve interpretability.
Forecasting in Non-stationary Environments with Fuzzy Time Series
Apr 27, 2020
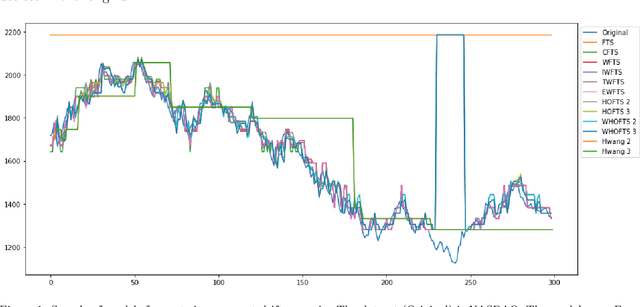
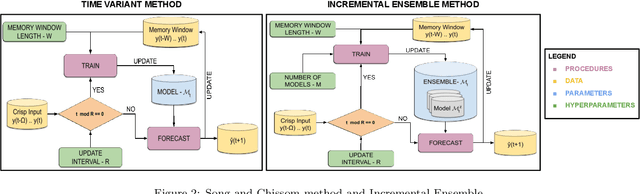

In this paper we introduce a Non-Stationary Fuzzy Time Series (NSFTS) method with time varying parameters adapted from the distribution of the data. In this approach, we employ Non-Stationary Fuzzy Sets, in which perturbation functions are used to adapt the membership function parameters in the knowledge base in response to statistical changes in the time series. The proposed method is capable of dynamically adapting its fuzzy sets to reflect the changes in the stochastic process based on the residual errors, without the need to retraining the model. This method can handle non-stationary and heteroskedastic data as well as scenarios with concept-drift. The proposed approach allows the model to be trained only once and remain useful long after while keeping reasonable accuracy. The flexibility of the method by means of computational experiments was tested with eight synthetic non-stationary time series data with several kinds of concept drifts, four real market indices (Dow Jones, NASDAQ, SP500 and TAIEX), three real FOREX pairs (EUR-USD, EUR-GBP, GBP-USD), and two real cryptocoins exchange rates (Bitcoin-USD and Ethereum-USD). As competitor models the Time Variant fuzzy time series and the Incremental Ensemble were used, these are two of the major approaches for handling non-stationary data sets. Non-parametric tests are employed to check the significance of the results. The proposed method shows resilience to concept drift, by adapting parameters of the model, while preserving the symbolic structure of the knowledge base.
Scalable and Customizable Benchmark Problems for Many-Objective Optimization
Feb 11, 2020



Solving many-objective problems (MaOPs) is still a significant challenge in the multi-objective optimization (MOO) field. One way to measure algorithm performance is through the use of benchmark functions (also called test functions or test suites), which are artificial problems with a well-defined mathematical formulation, known solutions and a variety of features and difficulties. In this paper we propose a parameterized generator of scalable and customizable benchmark problems for MaOPs. It is able to generate problems that reproduce features present in other benchmarks and also problems with some new features. We propose here the concept of generative benchmarking, in which one can generate an infinite number of MOO problems, by varying parameters that control specific features that the problem should have: scalability in the number of variables and objectives, bias, deceptiveness, multimodality, robust and non-robust solutions, shape of the Pareto front, and constraints. The proposed Generalized Position-Distance (GPD) tunable benchmark generator uses the position-distance paradigm, a basic approach to building test functions, used in other benchmarks such as Deb, Thiele, Laumanns and Zitzler (DTLZ), Walking Fish Group (WFG) and others. It includes scalable problems in any number of variables and objectives and it presents Pareto fronts with different characteristics. The resulting functions are easy to understand and visualize, easy to implement, fast to compute and their Pareto optimal solutions are known.
* 24 pages, 23 figures, to be published in Applied Soft computing