 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher-Order LaSDI: Reduced Order Modeling with Multiple Time Derivatives
Dec 17, 2025Solving complex partial differential equations is vital in the physical sciences, but often requires computationally expensive numerical methods. Reduced-order models (ROMs) address this by exploiting dimensionality reduction to create fast approximations. While modern ROMs can solve parameterized families of PDEs, their predictive power degrades over long time horizons. We address this by (1) introducing a flexible, high-order, yet inexpensive finite-difference scheme and (2) proposing a Rollout loss that trains ROMs to make accurate predictions over arbitrary time horizons. We demonstrate our approach on the 2D Burgers equation.
Rollout-LaSDI: Enhancing the long-term accuracy of Latent Space Dynamics
Sep 09, 2025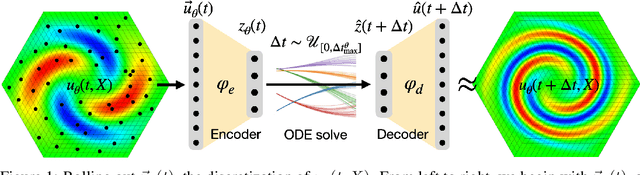
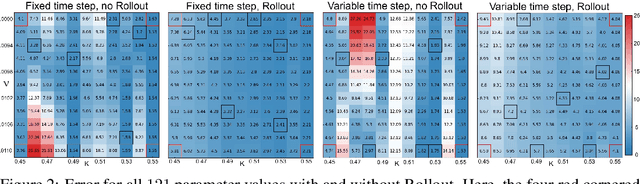
Solving complex partial differential equations is vital in the physical sciences, but often requires computationally expensive numerical methods. Reduced-order models (ROMs) address this by exploiting dimensionality reduction to create fast approximations. While modern ROMs can solve parameterized families of PDEs, their predictive power degrades over long time horizons. We address this by (1) introducing a flexible, high-order, yet inexpensive finite-difference scheme and (2) proposing a Rollout loss that trains ROMs to make accurate predictions over arbitrary time horizons. We demonstrate our approach on the 2D Burgers equation.
DDE-Find: Learning Delay Differential Equations from Data
May 04, 2024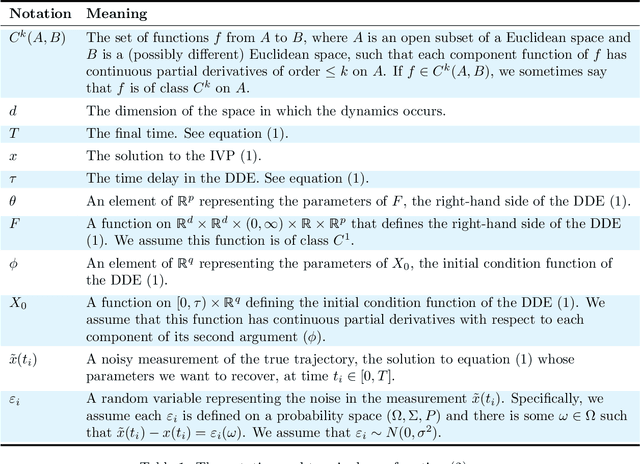
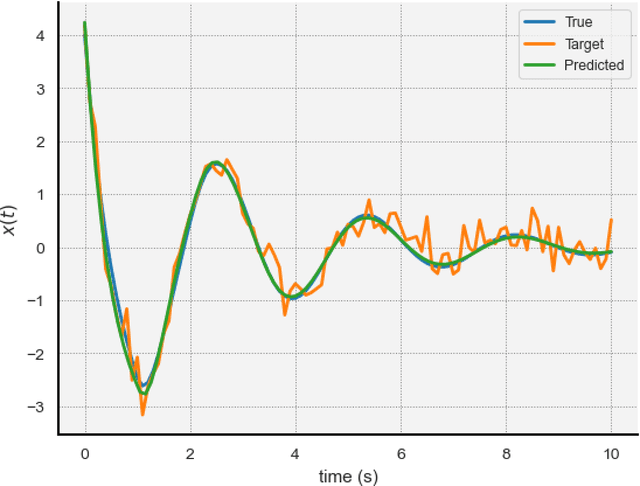

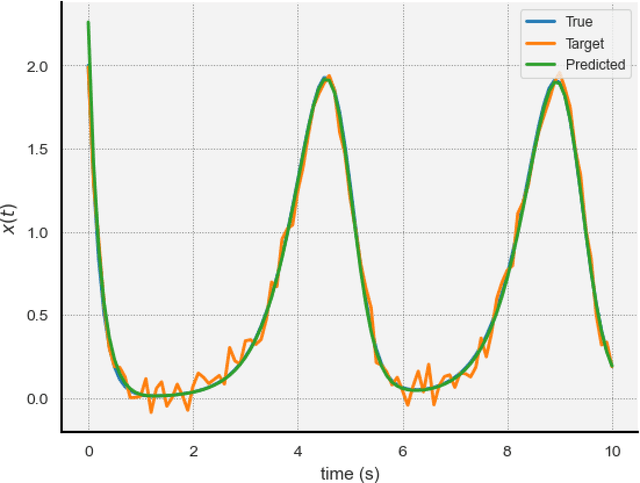
Delay Differential Equations (DDEs) are a class of differential equations that can model diverse scientific phenomena. However, identifying the parameters, especially the time delay, that make a DDE's predictions match experimental results can be challenging. We introduce DDE-Find, a data-driven framework for learning a DDE's parameters, time delay, and initial condition function. DDE-Find uses an adjoint-based approach to efficiently compute the gradient of a loss function with respect to the model parameters. We motivate and rigorously prove an expression for the gradients of the loss using the adjoint. DDE-Find builds upon recent developments in learning DDEs from data and delivers the first complete framework for learning DDEs from data. Through a series of numerical experiments, we demonstrate that DDE-Find can learn DDEs from noisy, limited data.
Weak-PDE-LEARN: A Weak Form Based Approach to Discovering PDEs From Noisy, Limited Data
Sep 09, 2023



We introduce Weak-PDE-LEARN, a Partial Differential Equation (PDE) discovery algorithm that can identify non-linear PDEs from noisy, limited measurements of their solutions. Weak-PDE-LEARN uses an adaptive loss function based on weak forms to train a neural network, $U$, to approximate the PDE solution while simultaneously identifying the governing PDE. This approach yields an algorithm that is robust to noise and can discover a range of PDEs directly from noisy, limited measurements of their solutions. We demonstrate the efficacy of Weak-PDE-LEARN by learning several benchmark PDEs.
Learning the Delay Using Neural Delay Differential Equations
Apr 03, 2023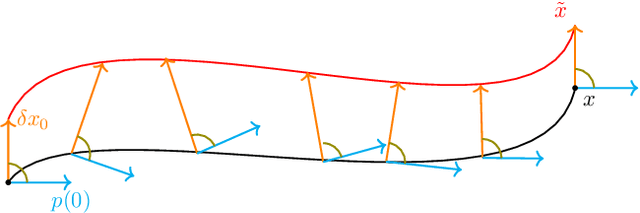
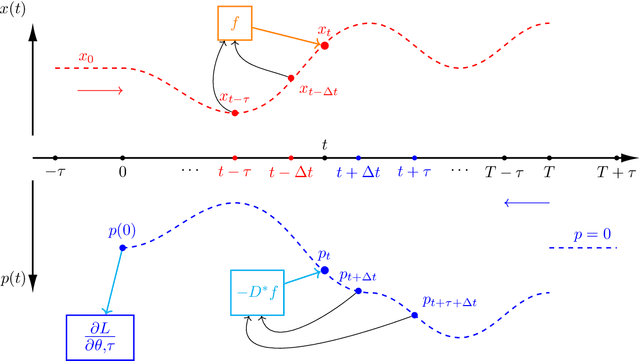
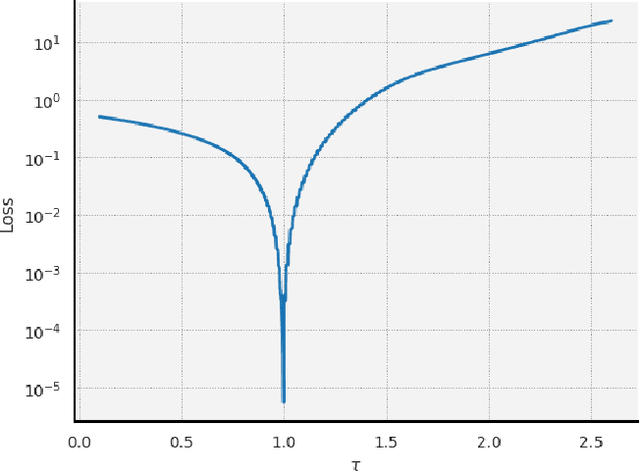
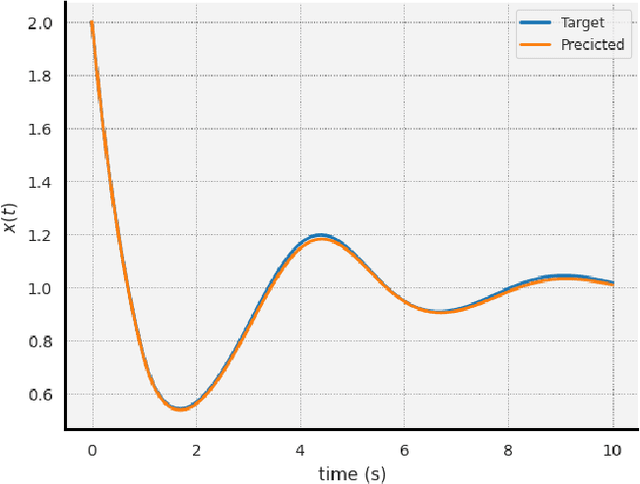
The intersection of machine learning and dynamical systems has generated considerable interest recently. Neural Ordinary Differential Equations (NODEs) represent a rich overlap between these fields. In this paper, we develop a continuous time neural network approach based on Delay Differential Equations (DDEs). Our model uses the adjoint sensitivity method to learn the model parameters and delay directly from data. Our approach is inspired by that of NODEs and extends earlier neural DDE models, which have assumed that the value of the delay is known a priori. We perform a sensitivity analysis on our proposed approach and demonstrate its ability to learn DDE parameters from benchmark systems. We conclude our discussion with potential future directions and applications.
PDE-LEARN: Using Deep Learning to Discover Partial Differential Equations from Noisy, Limited Data
Dec 09, 2022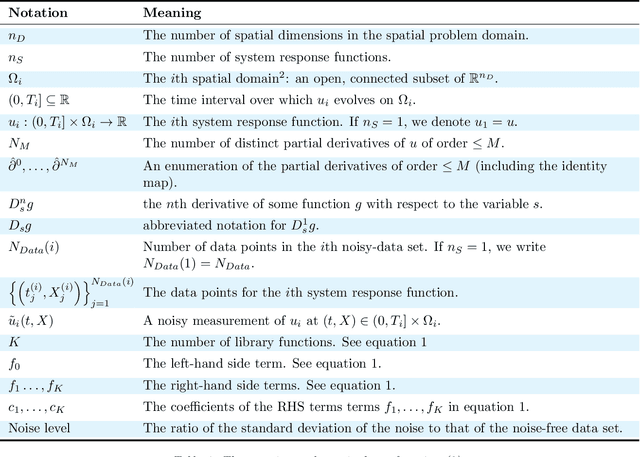
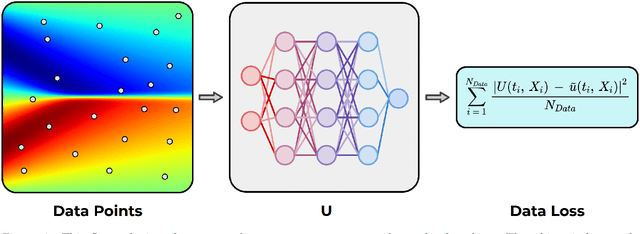
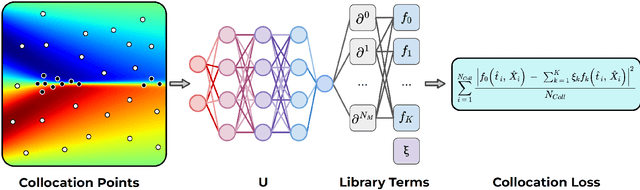
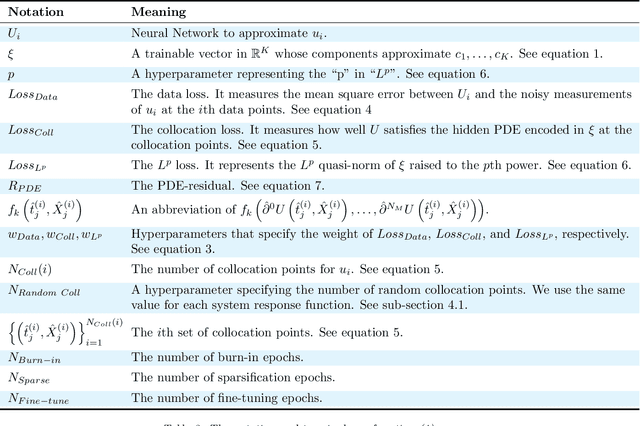
In this paper, we introduce PDE-LEARN, a novel PDE discovery algorithm that can identify governing partial differential equations (PDEs) directly from noisy, limited measurements of a physical system of interest. PDE-LEARN uses a Rational Neural Network, $U$, to approximate the system response function and a sparse, trainable vector, $\xi$, to characterize the hidden PDE that the system response function satisfies. Our approach couples the training of $U$ and $\xi$ using a loss function that (1) makes $U$ approximate the system response function, (2) encapsulates the fact that $U$ satisfies a hidden PDE that $\xi$ characterizes, and (3) promotes sparsity in $\xi$ using ideas from iteratively reweighted least-squares. Further, PDE-LEARN can simultaneously learn from several data sets, allowing it to incorporate results from multiple experiments. This approach yields a robust algorithm to discover PDEs directly from realistic scientific data. We demonstrate the efficacy of PDE-LEARN by identifying several PDEs from noisy and limited measurements.
PDE-READ: Human-readable Partial Differential Equation Discovery using Deep Learning
Nov 04, 2021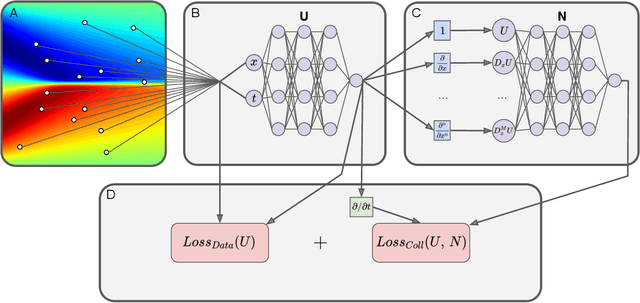
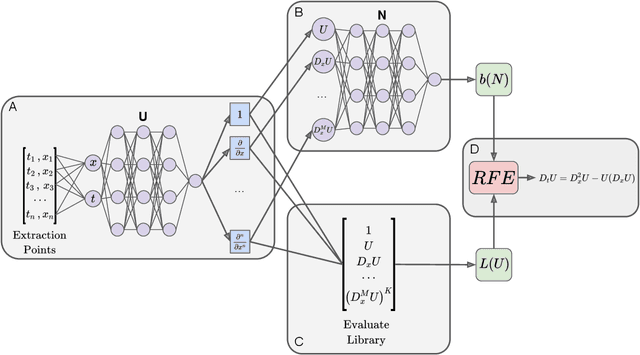
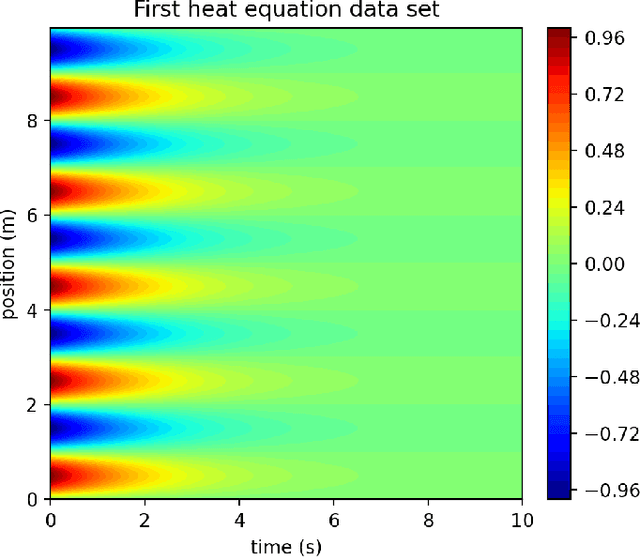
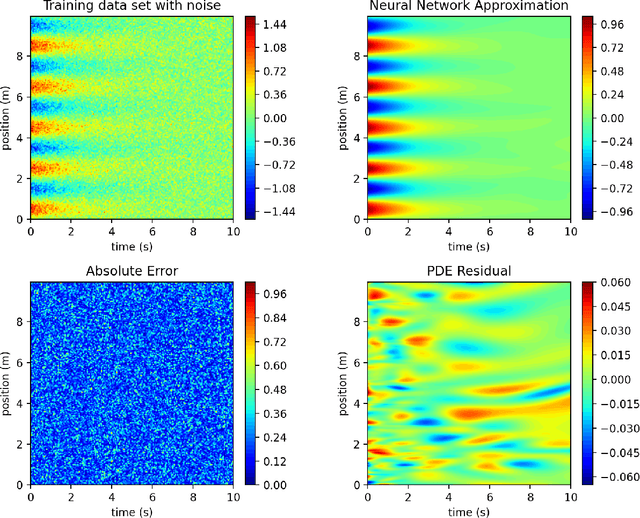
PDE discovery shows promise for uncovering predictive models for complex physical systems but has difficulty when measurements are sparse and noisy. We introduce a new approach for PDE discovery that uses two Rational Neural Networks and a principled sparse regression algorithm to identify the hidden dynamics that govern a system's response. The first network learns the system response function, while the second learns a hidden PDE which drives the system's evolution. We then use a parameter-free sparse regression algorithm to extract a human-readable form of the hidden PDE from the second network. We implement our approach in an open-source library called PDE-READ. Our approach successfully identifies the Heat, Burgers, and Korteweg-De Vries equations with remarkable consistency. We demonstrate that our approach is unprecedentedly robust to both sparsity and noise and is, therefore, applicable to real-world observational data.