 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-based Deep Learning Architecture with Optimal Integration Layer for Image Parsing
Apr 13, 2022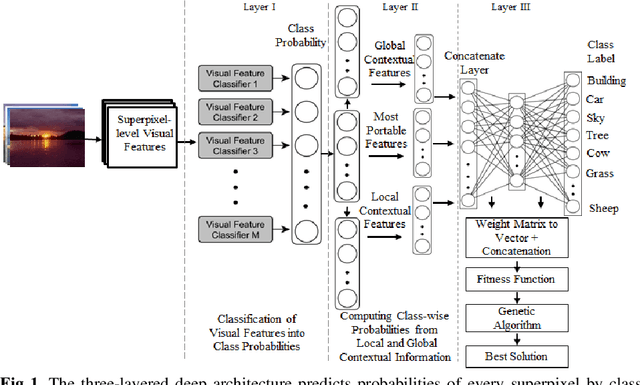
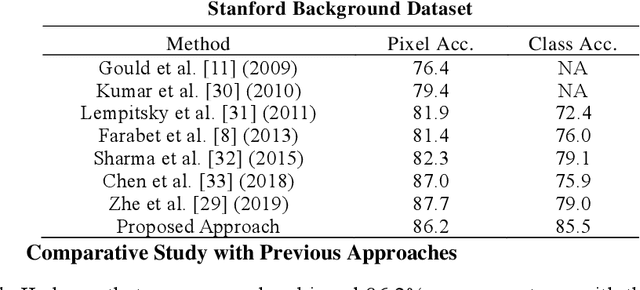
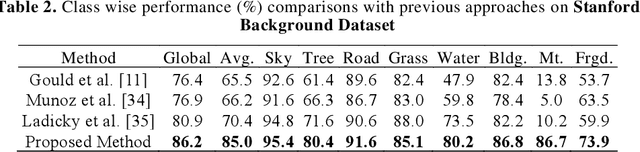
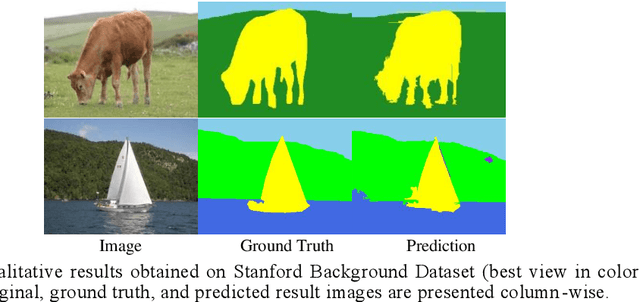
Deep learning models have been efficient lately on image parsing tasks. However, deep learning models are not fully capable of exploiting visual and contextual information simultaneously. The proposed three-layer context-based deep architecture is capable of integrating context explicitly with visual information. The novel idea here is to have a visual layer to learn visual characteristics from binary class-based learners, a contextual layer to learn context, and then an integration layer to learn from both via genetic algorithm-based optimal fusion to produce a final decision. The experimental outcomes when evaluated on benchmark datasets are promising. Further analysis shows that optimized network weights can improve performance and make stable predictions.
Deep Learning Model with GA based Feature Selection and Context Integration
Apr 13, 2022

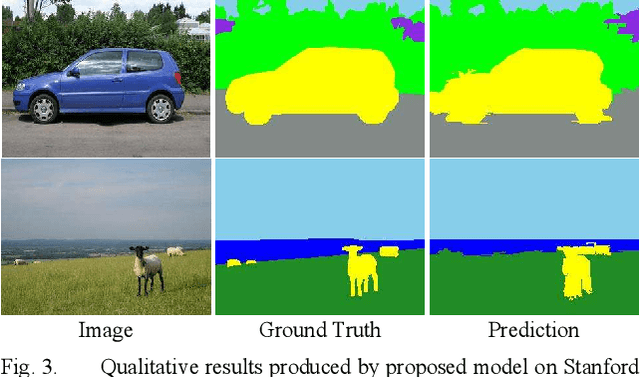

Deep learning models have been very successful in computer vision and image processing applications. Since its inception, Many top-performing methods for image segmentation are based on deep CNN models. However, deep CNN models fail to integrate global and local context alongside visual features despite having complex multi-layer architectures. We propose a novel three-layered deep learning model that assiminlate or learns independently global and local contextual information alongside visual features. The novelty of the proposed model is that One-vs-All binary class-based learners are introduced to learn Genetic Algorithm (GA) optimized features in the visual layer, followed by the contextual layer that learns global and local contexts of an image, and finally the third layer integrates all the information optimally to obtain the final class label. Stanford Background and CamVid benchmark image parsing datasets were used for our model evaluation, and our model shows promising results. The empirical analysis reveals that optimized visual features with global and local contextual information play a significant role to improve accuracy and produce stable predictions comparable to state-of-the-art deep CNN models.
Bag-of-Visual-Words for Signature-Based Multi-Script Document Retrieval
Jul 18, 2018



An end-to-end architecture for multi-script document retrieval using handwritten signatures is proposed in this paper. The user supplies a query signature sample and the system exclusively returns a set of documents that contain the query signature. In the first stage, a component-wise classification technique separates the potential signature components from all other components. A bag-of-visual-words powered by SIFT descriptors in a patch-based framework is proposed to compute the features and a Support Vector Machine (SVM)-based classifier was used to separate signatures from the documents. In the second stage, features from the foreground (i.e. signature strokes) and the background spatial information (i.e. background loops, reservoirs etc.) were combined to characterize the signature object to match with the query signature. Finally, three distance measures were used to match a query signature with the signature present in target documents for retrieval. The `Tobacco' document database and an Indian script database containing 560 documents of Devanagari (Hindi) and Bangla scripts were used for the performance evaluation. The proposed system was also tested on noisy documents and promising results were obtained. A comparative study shows that the proposed method outperforms the state-of-the-art approaches.
Assessing fish abundance from underwater video using deep neural networks
Jul 16, 2018
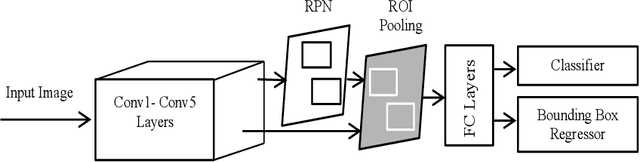
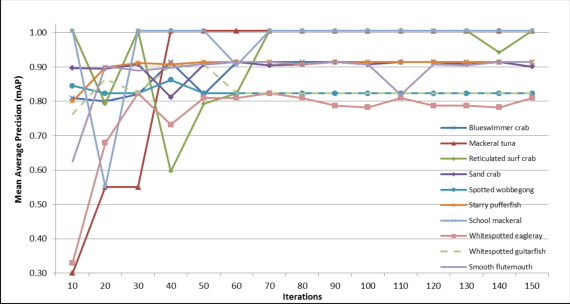
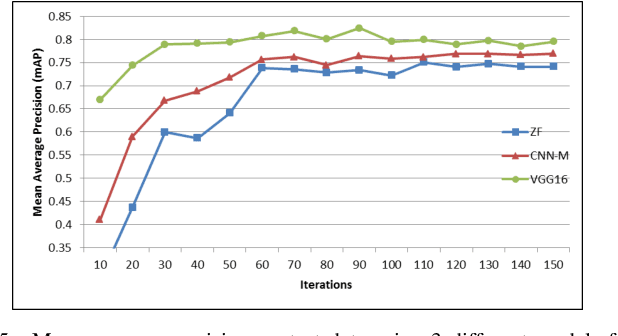
Uses of underwater videos to assess diversity and abundance of fish are being rapidly adopted by marine biologists. Manual processing of videos for quantification by human analysts is time and labour intensive. Automatic processing of videos can be employed to achieve the objectives in a cost and time-efficient way. The aim is to build an accurate and reliable fish detection and recognition system, which is important for an autonomous robotic platform. However, there are many challenges involved in this task (e.g. complex background, deformation, low resolution and light propagation). Recent advancement in the deep neural network has led to the development of object detection and recognition in real time scenarios. An end-to-end deep learning-based architecture is introduced which outperformed the state of the art methods and first of its kind on fish assessment task. A Region Proposal Network (RPN) introduced by an object detector termed as Faster R-CNN was combined with three classification networks for detection and recognition of fish species obtained from Remote Underwater Video Stations (RUVS). An accuracy of 82.4% (mAP) obtained from the experiments are much higher than previously proposed methods.