 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Model with GA based Feature Selection and Context Integration
Paper and Code
Apr 13, 2022

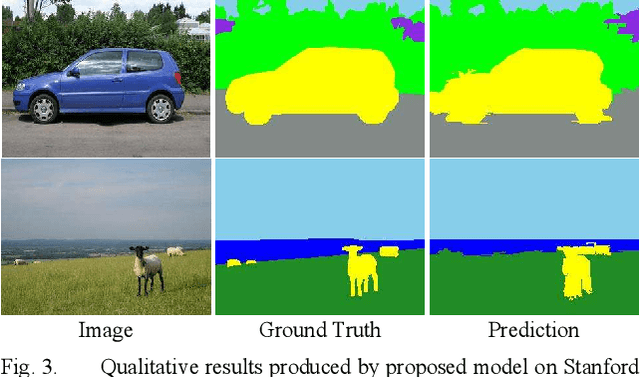

Deep learning models have been very successful in computer vision and image processing applications. Since its inception, Many top-performing methods for image segmentation are based on deep CNN models. However, deep CNN models fail to integrate global and local context alongside visual features despite having complex multi-layer architectures. We propose a novel three-layered deep learning model that assiminlate or learns independently global and local contextual information alongside visual features. The novelty of the proposed model is that One-vs-All binary class-based learners are introduced to learn Genetic Algorithm (GA) optimized features in the visual layer, followed by the contextual layer that learns global and local contexts of an image, and finally the third layer integrates all the information optimally to obtain the final class label. Stanford Background and CamVid benchmark image parsing datasets were used for our model evaluation, and our model shows promising results. The empirical analysis reveals that optimized visual features with global and local contextual information play a significant role to improve accuracy and produce stable predictions comparable to state-of-the-art deep CNN models.