 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-based Deep Learning Architecture with Optimal Integration Layer for Image Parsing
Paper and Code
Apr 13, 2022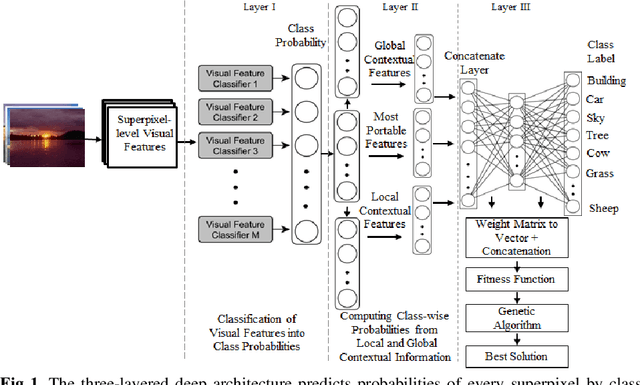
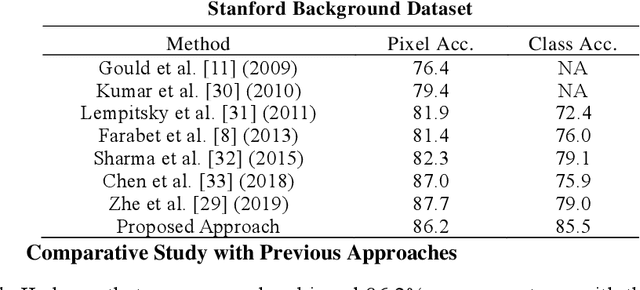
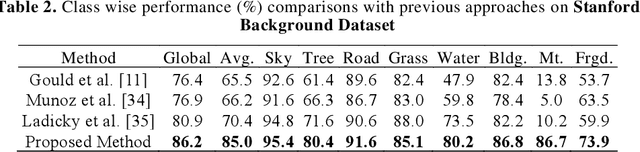
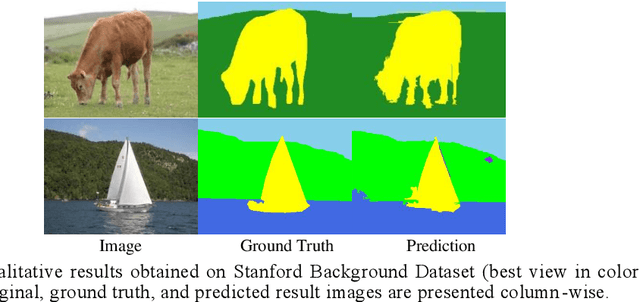
Deep learning models have been efficient lately on image parsing tasks. However, deep learning models are not fully capable of exploiting visual and contextual information simultaneously. The proposed three-layer context-based deep architecture is capable of integrating context explicitly with visual information. The novel idea here is to have a visual layer to learn visual characteristics from binary class-based learners, a contextual layer to learn context, and then an integration layer to learn from both via genetic algorithm-based optimal fusion to produce a final decision. The experimental outcomes when evaluated on benchmark datasets are promising. Further analysis shows that optimized network weights can improve performance and make stable predictions.