 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Estimation of Learning Rates Using a Non-Linear Autoregressive Model
Oct 13, 2024We introduce a new class of adaptive non-linear autoregressive (Nlar) models incorporating the concept of momentum, which dynamically estimate both the learning rates and momentum as the number of iterations increases. In our method, the growth of the gradients is controlled using a scaling (clipping) function, leading to stable convergence. Within this framework, we propose three distinct estimators for learning rates and provide theoretical proof of their convergence. We further demonstrate how these estimators underpin the development of effective Nlar optimizers. The performance of the proposed estimators and optimizers is rigorously evaluated through extensive experiments across several datasets and a reinforcement learning environment. The results highlight two key features of the Nlar optimizers: robust convergence despite variations in underlying parameters, including large initial learning rates, and strong adaptability with rapid convergence during the initial epochs.
Simple Noisy Environment Augmentation for Reinforcement Learning
May 04, 2023Data augmentation is a widely used technique for improving model performance in machine learning, particularly in computer vision and natural language processing. Recently, there has been increasing interest in applying augmentation techniques to reinforcement learning (RL) problems, with a focus on image-based augmentation. In this paper, we explore a set of generic wrappers designed to augment RL environments with noise and encourage agent exploration and improve training data diversity which are applicable to a broad spectrum of RL algorithms and environments. Specifically, we concentrate on augmentations concerning states, rewards, and transition dynamics and introduce two novel augmentation techniques. In addition, we introduce a noise rate hyperparameter for control over the frequency of noise injection. We present experimental results on the impact of these wrappers on return using three popular RL algorithms, Soft Actor-Critic (SAC), Twin Delayed DDPG (TD3), and Proximal Policy Optimization (PPO), across five MuJoCo environments. To support the choice of augmentation technique in practice, we also present analysis that explores the performance these techniques across environments. Lastly, we publish the wrappers in our noisyenv repository for use with gym environments.
An Introduction to Machine Unlearning
Sep 02, 2022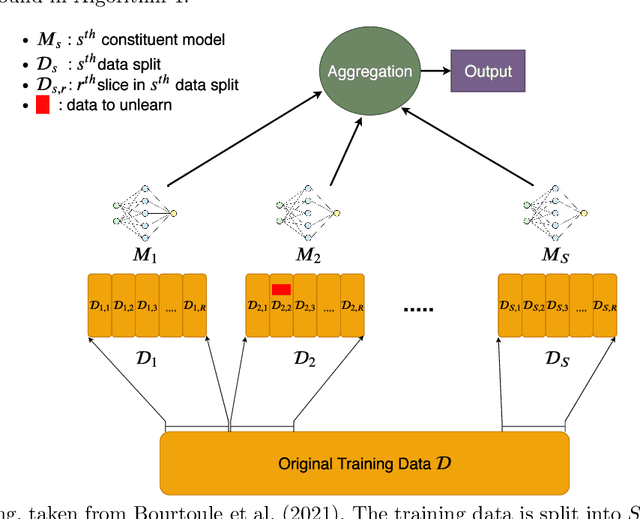
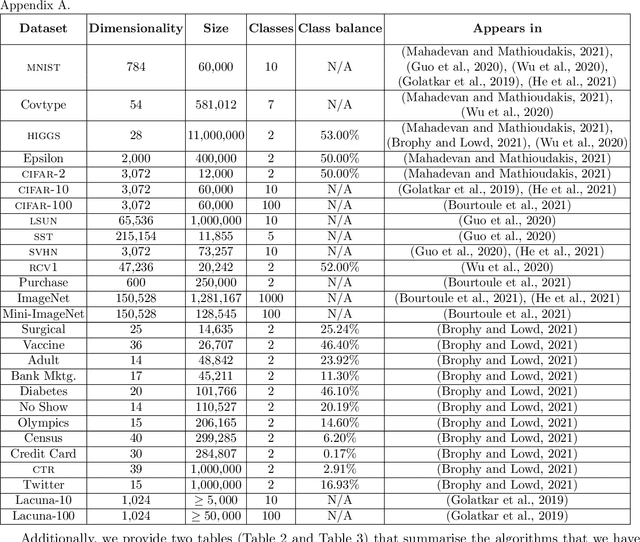
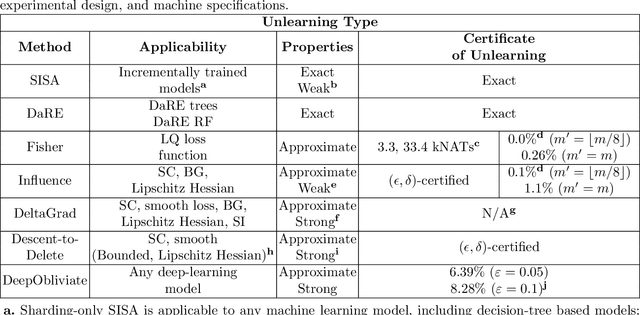
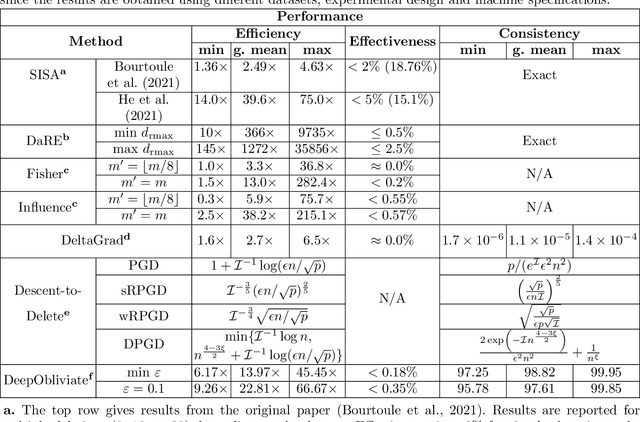
Removing the influence of a specified subset of training data from a machine learning model may be required to address issues such as privacy, fairness, and data quality. Retraining the model from scratch on the remaining data after removal of the subset is an effective but often infeasible option, due to its computational expense. The past few years have therefore seen several novel approaches towards efficient removal, forming the field of "machine unlearning", however, many aspects of the literature published thus far are disparate and lack consensus. In this paper, we summarise and compare seven state-of-the-art machine unlearning algorithms, consolidate definitions of core concepts used in the field, reconcile different approaches for evaluating algorithms, and discuss issues related to applying machine unlearning in practice.
Offline Deep Reinforcement Learning for Dynamic Pricing of Consumer Credit
Mar 06, 2022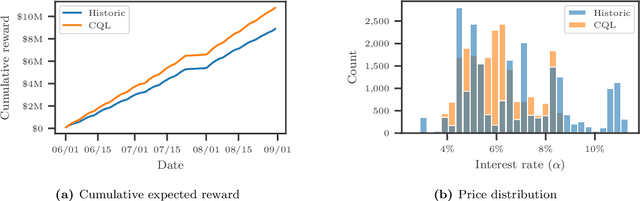
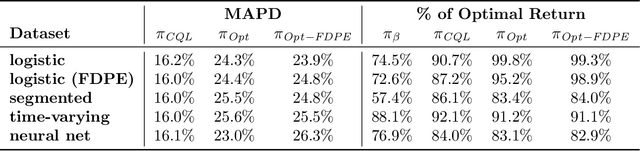
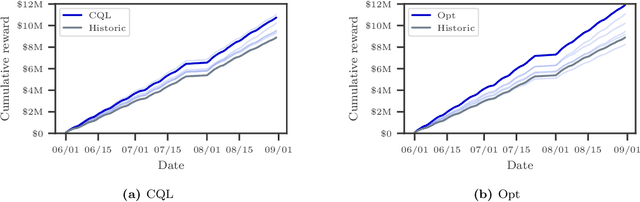
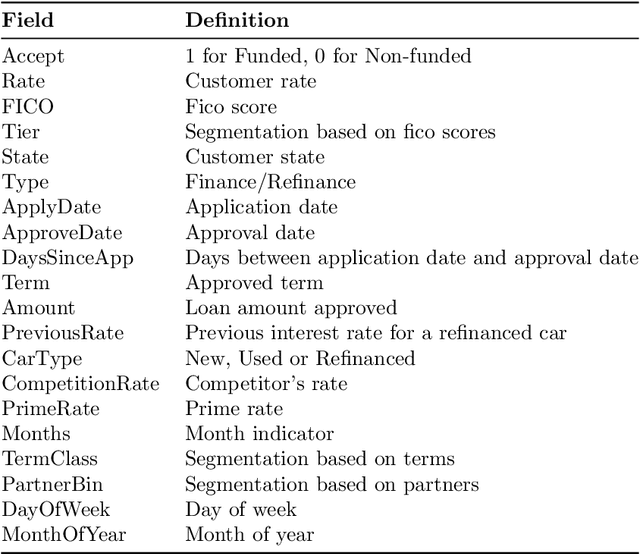
We introduce a method for pricing consumer credit using recent advances in offline deep reinforcement learning. This approach relies on a static dataset and requires no assumptions on the functional form of demand. Using both real and synthetic data on consumer credit applications, we demonstrate that our approach using the conservative Q-Learning algorithm is capable of learning an effective personalized pricing policy without any online interaction or price experimentation.
A Multilinear Sampling Algorithm to Estimate Shapley Values
Oct 22, 2020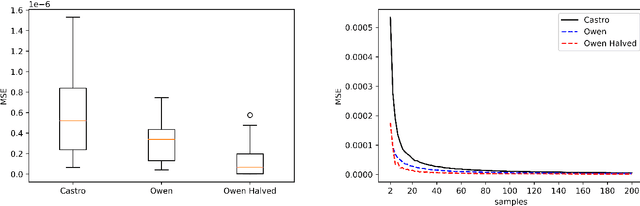
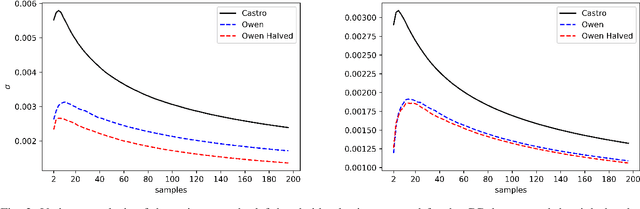
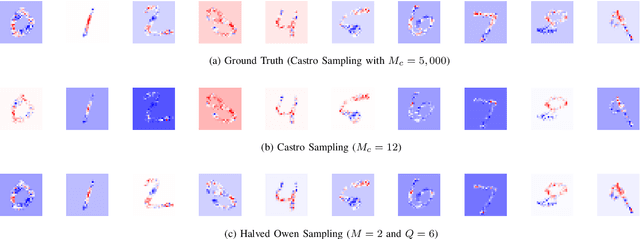
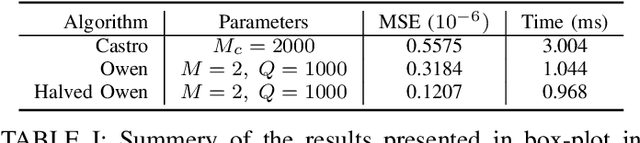
Shapley values are great analytical tools in game theory to measure the importance of a player in a game. Due to their axiomatic and desirable properties such as efficiency, they have become popular for feature importance analysis in data science and machine learning. However, the time complexity to compute Shapley values based on the original formula is exponential, and as the number of features increases, this becomes infeasible. Castro et al. [1] developed a sampling algorithm, to estimate Shapley values. In this work, we propose a new sampling method based on a multilinear extension technique as applied in game theory. The aim is to provide a more efficient (sampling) method for estimating Shapley values. Our method is applicable to any machine learning model, in particular for either multi-class classifications or regression problems. We apply the method to estimate Shapley values for multilayer perceptrons (MLPs) and through experimentation on two datasets, we demonstrate that our method provides more accurate estimations of the Shapley values by reducing the variance of the sampling statistics.
A Baseline for Shapley Values in MLPs: from Missingness to Neutrality
Jun 14, 2020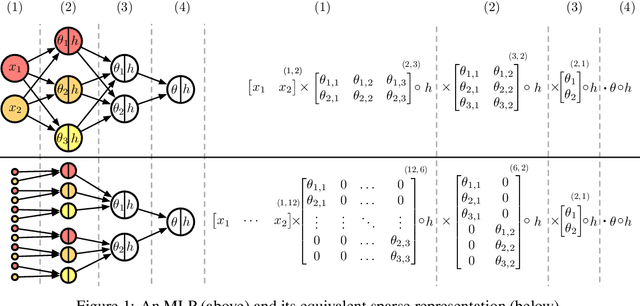

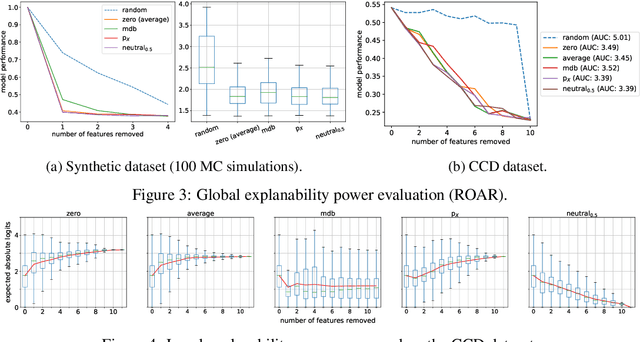
Being able to explain a prediction as well as having a model that performs well are paramount in many machine learning applications. Deep neural networks have gained momentum recently on the basis of their accuracy, however these are often criticised to be black-boxes. Many authors have focused on proposing methods to explain their predictions. Among these explainability methods, feature attribution methods have been favoured for their strong theoretical foundation: the Shapley value. A limitation of Shapley value is the need to define a baseline (aka reference point) representing the missingness of a feature. In this paper, we present a method to choose a baseline based on a neutrality value: a parameter defined by decision makers at which their choices are determined by the returned value of the model being either below or above it. Based on this concept, we theoretically justify these neutral baselines and find a way to identify them for MLPs. Then, we experimentally demonstrate that for a binary classification task, using a synthetic dataset and a dataset coming from the financial domain, the proposed baselines outperform, in terms of local explanability power, standard ways of choosing them.