 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Baseline for Shapley Values in MLPs: from Missingness to Neutrality
Paper and Code
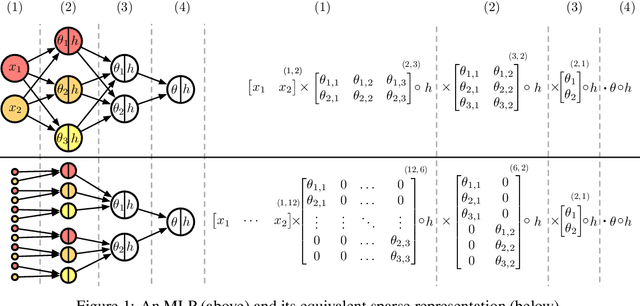

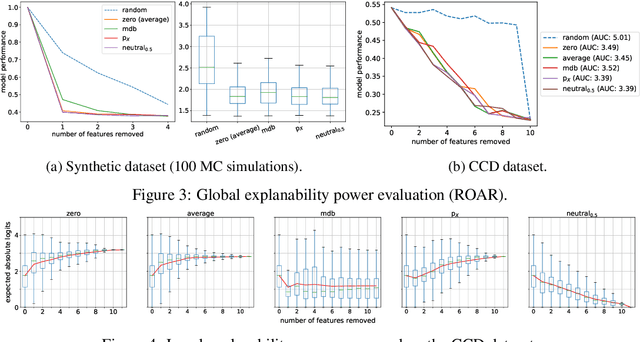
Being able to explain a prediction as well as having a model that performs well are paramount in many machine learning applications. Deep neural networks have gained momentum recently on the basis of their accuracy, however these are often criticised to be black-boxes. Many authors have focused on proposing methods to explain their predictions. Among these explainability methods, feature attribution methods have been favoured for their strong theoretical foundation: the Shapley value. A limitation of Shapley value is the need to define a baseline (aka reference point) representing the missingness of a feature. In this paper, we present a method to choose a baseline based on a neutrality value: a parameter defined by decision makers at which their choices are determined by the returned value of the model being either below or above it. Based on this concept, we theoretically justify these neutral baselines and find a way to identify them for MLPs. Then, we experimentally demonstrate that for a binary classification task, using a synthetic dataset and a dataset coming from the financial domain, the proposed baselines outperform, in terms of local explanability power, standard ways of choosing them.