 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA machine learning approach to support decision in insider trading detection
Dec 06, 2022



Identifying market abuse activity from data on investors' trading activity is very challenging both for the data volume and for the low signal to noise ratio. Here we propose two complementary unsupervised machine learning methods to support market surveillance aimed at identifying potential insider trading activities. The first one uses clustering to identify, in the vicinity of a price sensitive event such as a takeover bid, discontinuities in the trading activity of an investor with respect to his/her own past trading history and on the present trading activity of his/her peers. The second unsupervised approach aims at identifying (small) groups of investors that act coherently around price sensitive events, pointing to potential insider rings, i.e. a group of synchronised traders displaying strong directional trading in rewarding position in a period before the price sensitive event. As a case study, we apply our methods to investor resolved data of Italian stocks around takeover bids.
Information Extraction through AI techniques: The KIDs use case at CONSOB
Jan 29, 2022In this paper we report on the initial activities carried out within a collaboration between Consob and Sapienza University. We focus on Information Extraction from documents describing financial instruments. We discuss how we automate this task, via both rule-based and machine learning-based methods and provide our first results.
A Baseline for Shapley Values in MLPs: from Missingness to Neutrality
Jun 14, 2020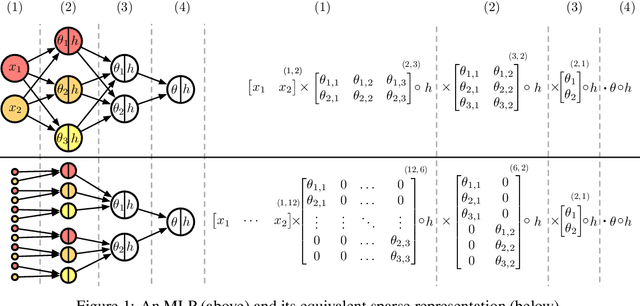

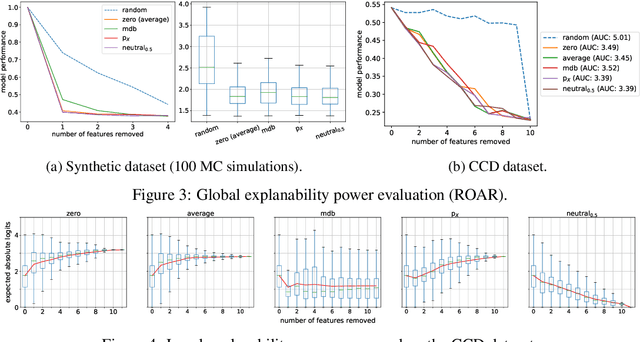
Being able to explain a prediction as well as having a model that performs well are paramount in many machine learning applications. Deep neural networks have gained momentum recently on the basis of their accuracy, however these are often criticised to be black-boxes. Many authors have focused on proposing methods to explain their predictions. Among these explainability methods, feature attribution methods have been favoured for their strong theoretical foundation: the Shapley value. A limitation of Shapley value is the need to define a baseline (aka reference point) representing the missingness of a feature. In this paper, we present a method to choose a baseline based on a neutrality value: a parameter defined by decision makers at which their choices are determined by the returned value of the model being either below or above it. Based on this concept, we theoretically justify these neutral baselines and find a way to identify them for MLPs. Then, we experimentally demonstrate that for a binary classification task, using a synthetic dataset and a dataset coming from the financial domain, the proposed baselines outperform, in terms of local explanability power, standard ways of choosing them.