 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGravityGraphSAGE: Link Prediction in Directed Attributed Graphs
May 10, 2026Link prediction (inferring missing or future connections between nodes in a graph) is a fundamental problem in network science with widespread applications in, e.g., biological systems, recommender systems, finance and cybersecurity. The ability to accurately predict links has significant real-world applications, such as detecting fraudulent financial transactions or identifying drug-target interactions in biomedicine. Despite a rich literature, link prediction is still challenging, especially for graphs enriched with information on edges (direction) and nodes (attributes). In fact, research on link prediction, especially the one based on Graph Deep Learning (GDL), has mostly focused on undirected graphs, without fully leveraging node attributes. Here, we fill this gap by proposing Gravity-GraphSAGE (GG-SAGE), a modified version of GraphSAGE, a GDL model for node embeddings, composed of a gravity-inspired decoder. This implementation is the first example in the literature of a GraphSAGE backbone adopted for directed link prediction. Using the benchmark datasets Cora, Citeseer, PubMed and 16 real-world graphs from the online Netzschleuder repository, we show that our proposed model outperforms state-of-the-art GDL link prediction techniques. Using further experimental evidence, we relate the quality of the output of our model with various characteristics of the graph, suggesting that our framework scales well when applied to data of increasing complexity.
Reinforcement Learning in Queue-Reactive Models: Application to Optimal Execution
Nov 19, 2025We investigate the use of Reinforcement Learning for the optimal execution of meta-orders, where the objective is to execute incrementally large orders while minimizing implementation shortfall and market impact over an extended period of time. Departing from traditional parametric approaches to price dynamics and impact modeling, we adopt a model-free, data-driven framework. Since policy optimization requires counterfactual feedback that historical data cannot provide, we employ the Queue-Reactive Model to generate realistic and tractable limit order book simulations that encompass transient price impact, and nonlinear and dynamic order flow responses. Methodologically, we train a Double Deep Q-Network agent on a state space comprising time, inventory, price, and depth variables, and evaluate its performance against established benchmarks. Numerical simulation results show that the agent learns a policy that is both strategic and tactical, adapting effectively to order book conditions and outperforming standard approaches across multiple training configurations. These findings provide strong evidence that model-free Reinforcement Learning can yield adaptive and robust solutions to the optimal execution problem.
Why is the estimation of metaorder impact with public market data so challenging?
Jan 28, 2025Estimating market impact and transaction costs of large trades (metaorders) is a very important topic in finance. However, using models of price and trade based on public market data provide average price trajectories which are qualitatively different from what is observed during real metaorder executions: the price increases linearly, rather than in a concave way, during the execution and the amount of reversion after its end is very limited. We claim that this is a generic phenomenon due to the fact that even sophisticated statistical models are unable to correctly describe the origin of the autocorrelation of the order flow. We propose a modified Transient Impact Model which provides more realistic trajectories by assuming that only a fraction of the metaorder trading triggers market order flow. Interestingly, in our model there is a critical condition on the kernels of the price and order flow equations in which market impact becomes permanent.
Deviations from the Nash equilibrium and emergence of tacit collusion in a two-player optimal execution game with reinforcement learning
Aug 21, 2024
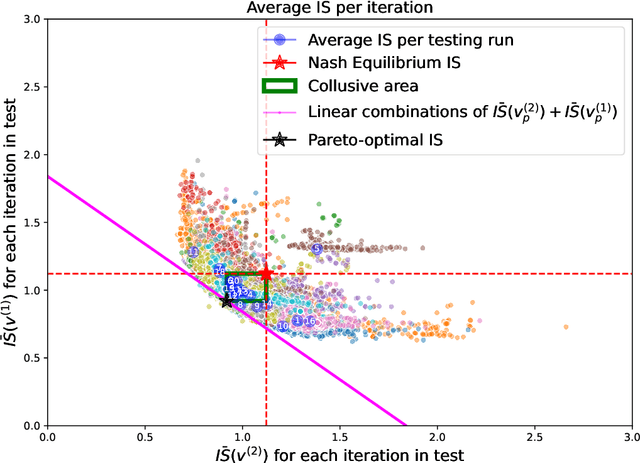
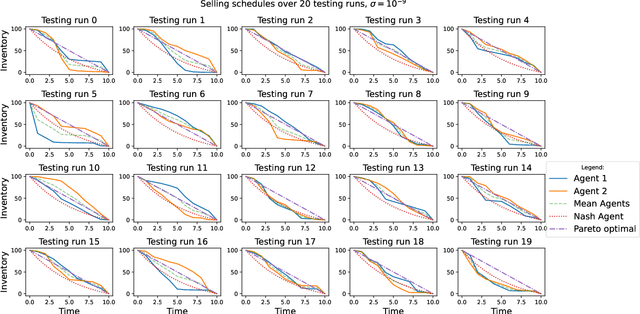
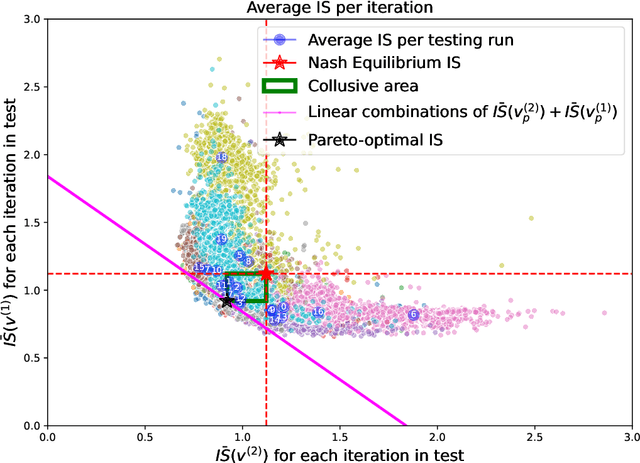
The use of reinforcement learning algorithms in financial trading is becoming increasingly prevalent. However, the autonomous nature of these algorithms can lead to unexpected outcomes that deviate from traditional game-theoretical predictions and may even destabilize markets. In this study, we examine a scenario in which two autonomous agents, modeled with Double Deep Q-Learning, learn to liquidate the same asset optimally in the presence of market impact, using the Almgren-Chriss (2000) framework. Our results show that the strategies learned by the agents deviate significantly from the Nash equilibrium of the corresponding market impact game. Notably, the learned strategies exhibit tacit collusion, closely aligning with the Pareto-optimal solution. We further explore how different levels of market volatility influence the agents' performance and the equilibria they discover, including scenarios where volatility differs between the training and testing phases.
Bayesian Autoregressive Online Change-Point Detection with Time-Varying Parameters
Jul 23, 2024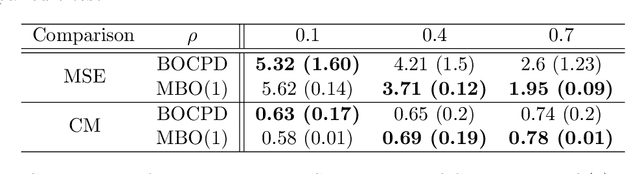
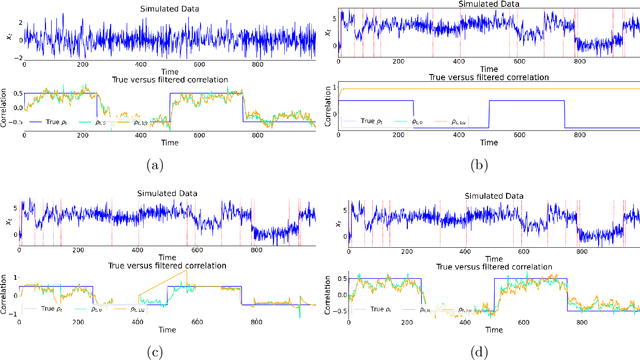
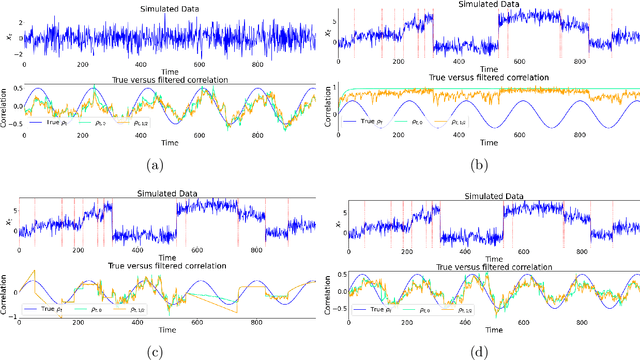
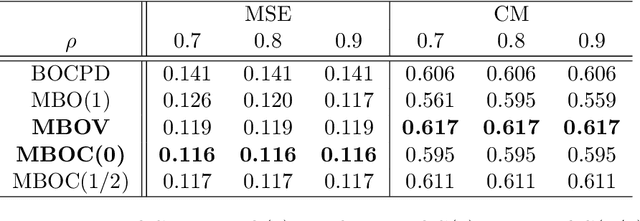
Change points in real-world systems mark significant regime shifts in system dynamics, possibly triggered by exogenous or endogenous factors. These points define regimes for the time evolution of the system and are crucial for understanding transitions in financial, economic, social, environmental, and technological contexts. Building upon the Bayesian approach introduced in \cite{c:07}, we devise a new method for online change point detection in the mean of a univariate time series, which is well suited for real-time applications and is able to handle the general temporal patterns displayed by data in many empirical contexts. We first describe time series as an autoregressive process of an arbitrary order. Second, the variance and correlation of the data are allowed to vary within each regime driven by a scoring rule that updates the value of the parameters for a better fit of the observations. Finally, a change point is detected in a probabilistic framework via the posterior distribution of the current regime length. By modeling temporal dependencies and time-varying parameters, the proposed approach enhances both the estimate accuracy and the forecasting power. Empirical validations using various datasets demonstrate the method's effectiveness in capturing memory and dynamic patterns, offering deeper insights into the non-stationary dynamics of real-world systems.
A machine learning approach to support decision in insider trading detection
Dec 06, 2022



Identifying market abuse activity from data on investors' trading activity is very challenging both for the data volume and for the low signal to noise ratio. Here we propose two complementary unsupervised machine learning methods to support market surveillance aimed at identifying potential insider trading activities. The first one uses clustering to identify, in the vicinity of a price sensitive event such as a takeover bid, discontinuities in the trading activity of an investor with respect to his/her own past trading history and on the present trading activity of his/her peers. The second unsupervised approach aims at identifying (small) groups of investors that act coherently around price sensitive events, pointing to potential insider rings, i.e. a group of synchronised traders displaying strong directional trading in rewarding position in a period before the price sensitive event. As a case study, we apply our methods to investor resolved data of Italian stocks around takeover bids.
Estimating the Total Volume of Queries to a Search Engine
Jan 24, 2021



We study the problem of estimating the total number of searches (volume) of queries in a specific domain, which were submitted to a search engine in a given time period. Our statistical model assumes that the distribution of searches follows a Zipf's law, and that the observed sample volumes are biased accordingly to three possible scenarios. These assumptions are consistent with empirical data, with keyword research practices, and with approximate algorithms used to take counts of query frequencies. A few estimators of the parameters of the distribution are devised and experimented, based on the nature of the empirical/simulated data. For continuous data, we recommend using nonlinear least square regression (NLS) on the top-volume queries, where the bound on the volume is obtained from the well-known Clauset, Shalizi and Newman (CSN) estimation of power-law parameters. For binned data, we propose using a Chi-square minimization approach restricted to the top-volume queries, where the bound is obtained by the binned version of the CSN method. Estimations are then derived for the total number of queries and for the total volume of the population, including statistical error bounds. We apply the methods on the domain of recipes and cooking queries searched in Italian in 2017. The observed volumes of sample queries are collected from Google Trends (continuous data) and SearchVolume (binned data). The estimated total number of queries and total volume are computed for the two cases, and the results are compared and discussed.
A dynamic network model with persistent links and node-specific latent variables, with an application to the interbank market
Dec 30, 2017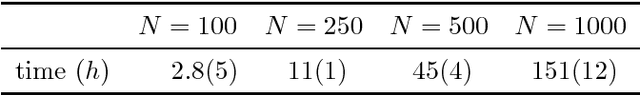

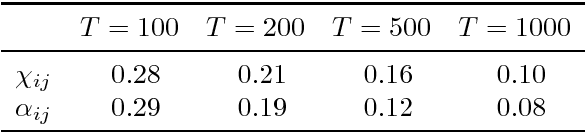
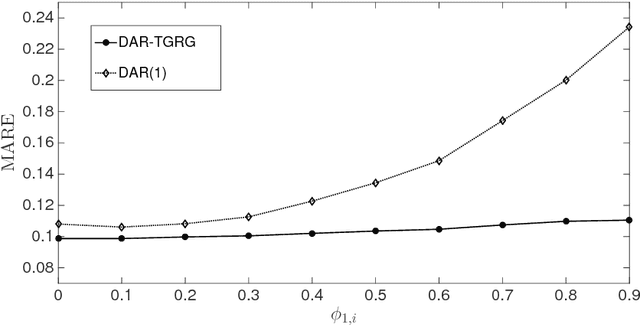
We propose a dynamic network model where two mechanisms control the probability of a link between two nodes: (i) the existence or absence of this link in the past, and (ii) node-specific latent variables (dynamic fitnesses) describing the propensity of each node to create links. Assuming a Markov dynamics for both mechanisms, we propose an Expectation-Maximization algorithm for model estimation and inference of the latent variables. The estimated parameters and fitnesses can be used to forecast the presence of a link in the future. We apply our methodology to the e-MID interbank network for which the two linkage mechanisms are associated with two different trading behaviors in the process of network formation, namely preferential trading and trading driven by node-specific characteristics. The empirical results allow to recognise preferential lending in the interbank market and indicate how a method that does not account for time-varying network topologies tends to overestimate preferential linkage.
Disentangling group and link persistence in Dynamic Stochastic Block models
Nov 10, 2017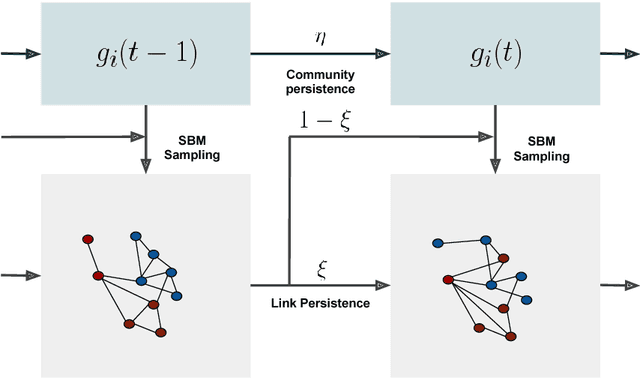
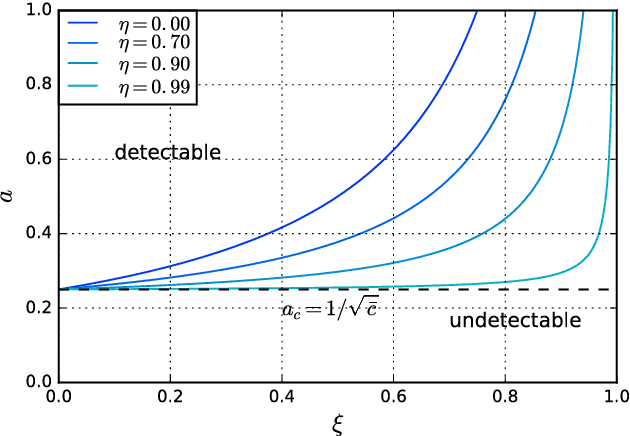
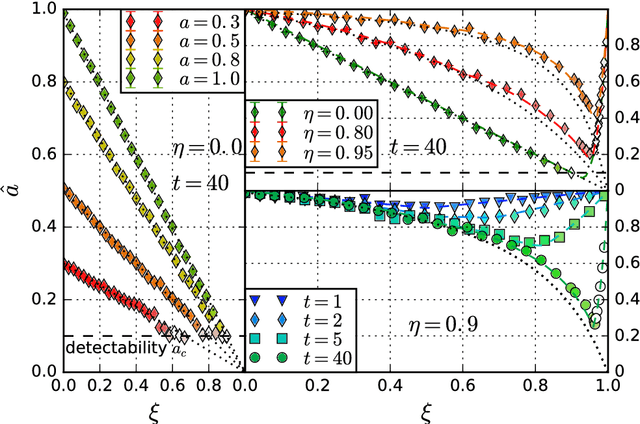

We study the inference of a model of dynamic networks in which both communities and links keep memory of previous network states. By considering maximum likelihood inference from single snapshot observations of the network, we show that link persistence makes the inference of communities harder, decreasing the detectability threshold, while community persistence tends to make it easier. We analytically show that communities inferred from single network snapshot can share a maximum overlap with the underlying communities of a specific previous instant in time. This leads to time-lagged inference: the identification of past communities rather than present ones. Finally we compute the time lag and propose a corrected algorithm, the Lagged Snapshot Dynamic (LSD) algorithm, for community detection in dynamic networks. We analytically and numerically characterize the detectability transitions of such algorithm as a function of the memory parameters of the model.