 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Introduction to Machine Unlearning
Sep 02, 2022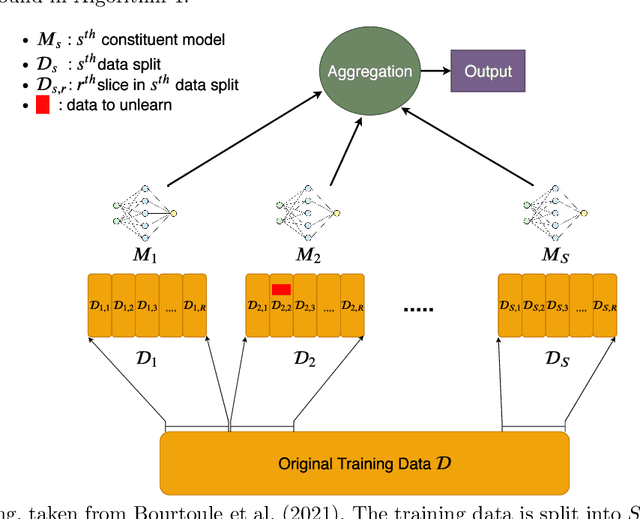
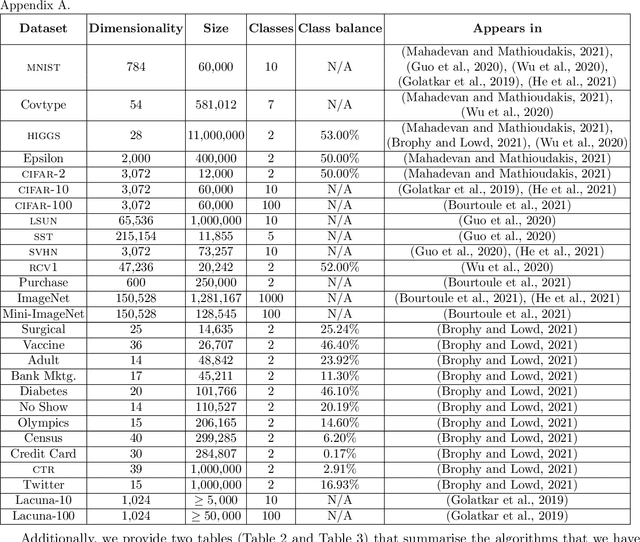
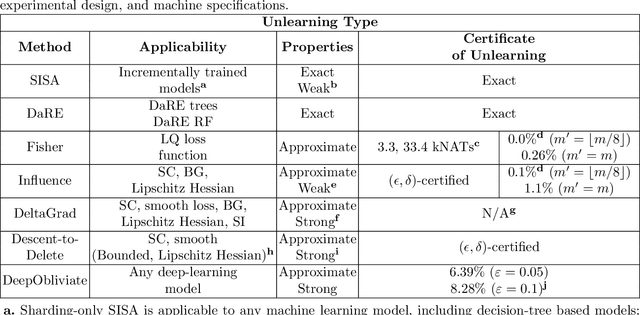
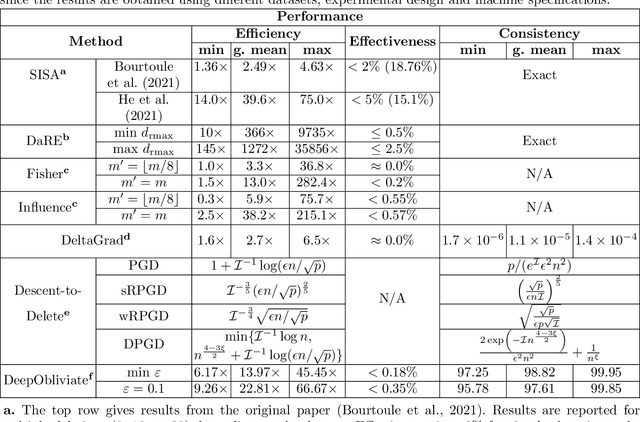
Removing the influence of a specified subset of training data from a machine learning model may be required to address issues such as privacy, fairness, and data quality. Retraining the model from scratch on the remaining data after removal of the subset is an effective but often infeasible option, due to its computational expense. The past few years have therefore seen several novel approaches towards efficient removal, forming the field of "machine unlearning", however, many aspects of the literature published thus far are disparate and lack consensus. In this paper, we summarise and compare seven state-of-the-art machine unlearning algorithms, consolidate definitions of core concepts used in the field, reconcile different approaches for evaluating algorithms, and discuss issues related to applying machine unlearning in practice.