 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormal Conjectures: An Open and Evolving Benchmark for Verified Discovery in Mathematics
May 13, 2026As automated reasoning systems advance rapidly, there is a growing need for research-level formal mathematical problems to accurately evaluate their capabilities. To address this, we present Formal Conjectures, an evolving benchmark of currently 2615 mathematical problem statements formalized in Lean 4. Sourced from areas of active mathematical research, the dataset features 1029 open research conjectures providing a zero-contamination benchmark for mathematical proof discovery, and 836 solved problems for proof autoformalization. Notably, the repository provides a structured interface connecting mathematicians who formalize and clarify problems with the AI systems and humans attempting to solve them. Demonstrating its immediate utility, the benchmark has already been leveraged to make new mathematical discoveries, including the resolution of open research conjectures. We describe our approach to ensuring the correctness of these formalizations in a collaborative open-source project where contributions stem from an active community. In this framework, AI-generated proofs and disproofs serve as a valuable auditing mechanism to iteratively improve the fidelity of the benchmark. Finally, we provide a standardized evaluation setup and report baseline results on frozen evaluation subsets, demonstrating a climbable signal that measures the current frontier of automated reasoning on research-level mathematics.
Conformal Predictions for Longitudinal Data
Oct 04, 2023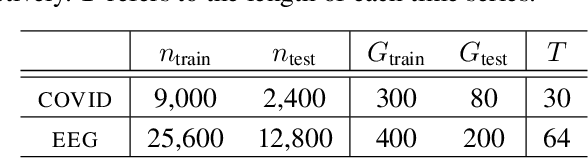
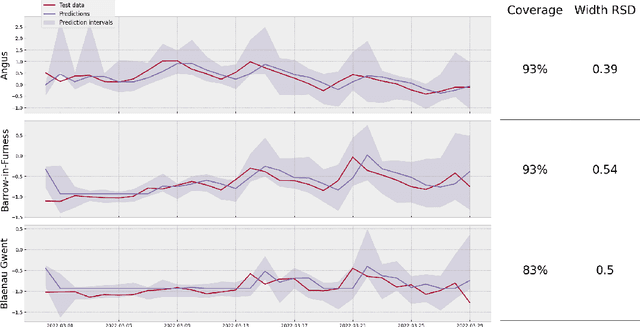

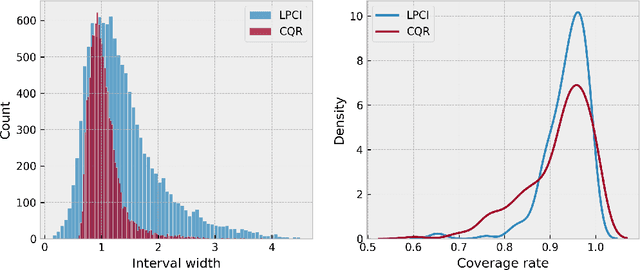
We introduce Longitudinal Predictive Conformal Inference (LPCI), a novel distribution-free conformal prediction algorithm for longitudinal data. Current conformal prediction approaches for time series data predominantly focus on the univariate setting, and thus lack cross-sectional coverage when applied individually to each time series in a longitudinal dataset. The current state-of-the-art for longitudinal data relies on creating infinitely-wide prediction intervals to guarantee both cross-sectional and asymptotic longitudinal coverage. The proposed LPCI method addresses this by ensuring that both longitudinal and cross-sectional coverages are guaranteed without resorting to infinitely wide intervals. In our approach, we model the residual data as a quantile fixed-effects regression problem, constructing prediction intervals with a trained quantile regressor. Our extensive experiments demonstrate that LPCI achieves valid cross-sectional coverage and outperforms existing benchmarks in terms of longitudinal coverage rates. Theoretically, we establish LPCI's asymptotic coverage guarantees for both dimensions, with finite-width intervals. The robust performance of LPCI in generating reliable prediction intervals for longitudinal data underscores its potential for broad applications, including in medicine, finance, and supply chain management.
Modelling customer lifetime-value in the retail banking industry
Apr 06, 2023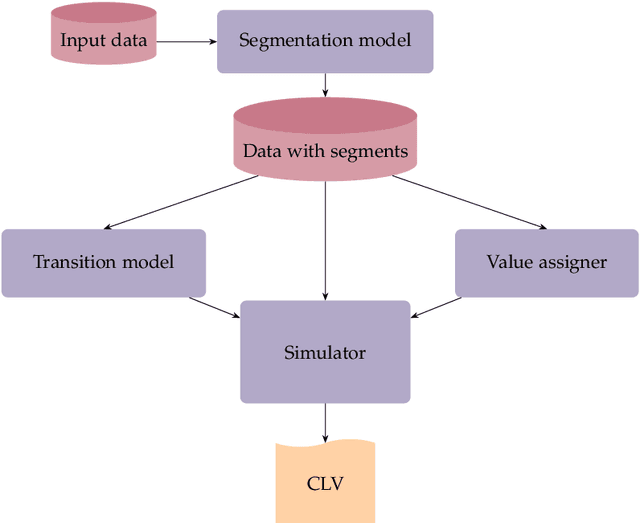
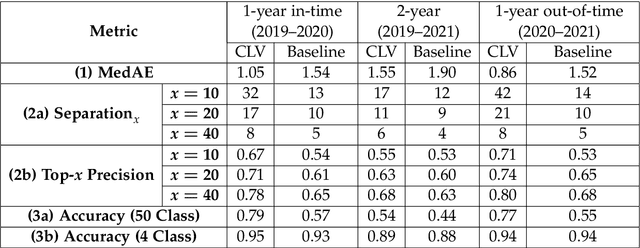
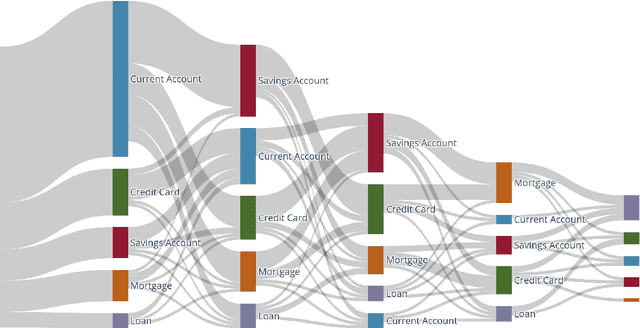
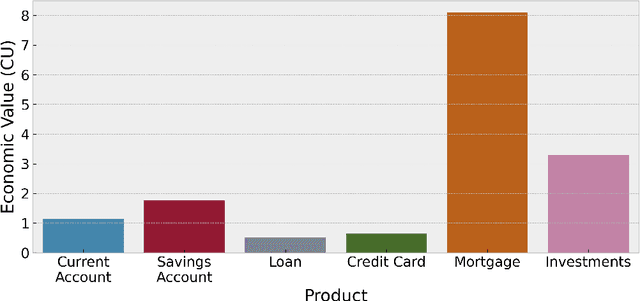
Understanding customer lifetime value is key to nurturing long-term customer relationships, however, estimating it is far from straightforward. In the retail banking industry, commonly used approaches rely on simple heuristics and do not take advantage of the high predictive ability of modern machine learning techniques. We present a general framework for modelling customer lifetime value which may be applied to industries with long-lasting contractual and product-centric customer relationships, of which retail banking is an example. This framework is novel in facilitating CLV predictions over arbitrary time horizons and product-based propensity models. We also detail an implementation of this model which is currently in production at a large UK lender. In testing, we estimate an 43% improvement in out-of-time CLV prediction error relative to a popular baseline approach. Propensity models derived from our CLV model have been used to support customer contact marketing campaigns. In testing, we saw that the top 10% of customers ranked by their propensity to take up investment products were 3.2 times more likely to take up an investment product in the next year than a customer chosen at random.
An Introduction to Machine Unlearning
Sep 02, 2022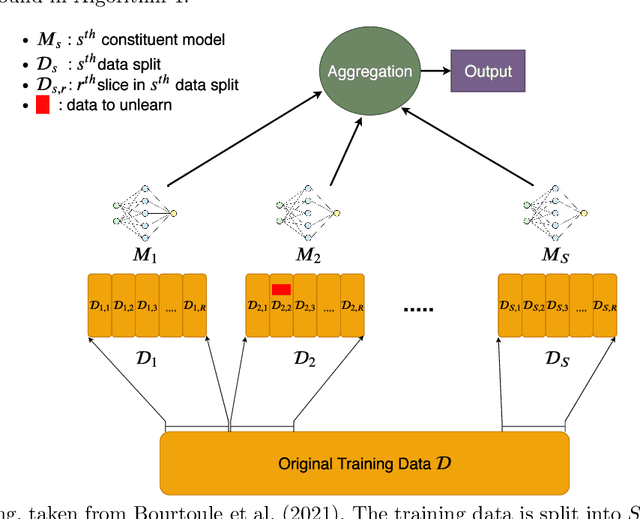
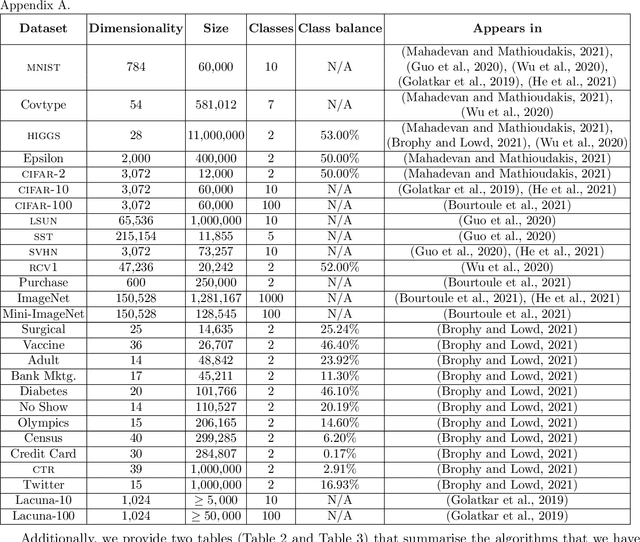
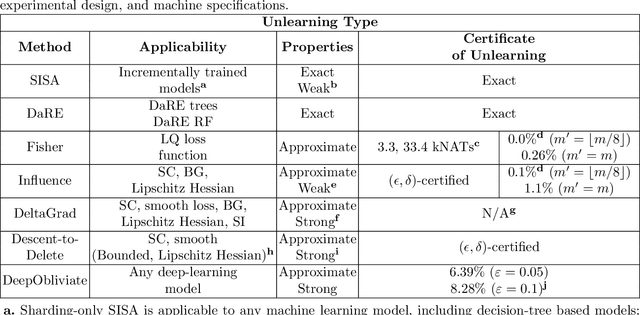
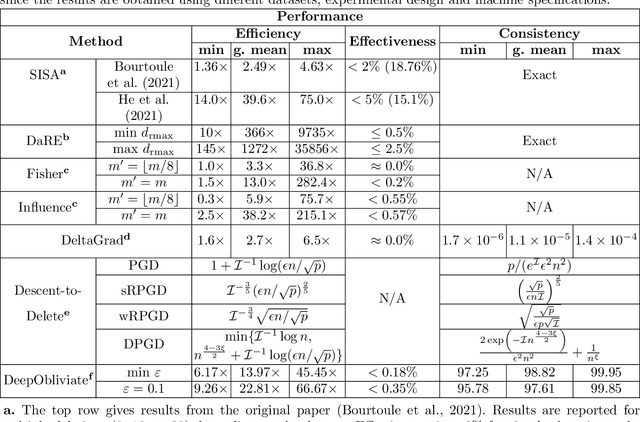
Removing the influence of a specified subset of training data from a machine learning model may be required to address issues such as privacy, fairness, and data quality. Retraining the model from scratch on the remaining data after removal of the subset is an effective but often infeasible option, due to its computational expense. The past few years have therefore seen several novel approaches towards efficient removal, forming the field of "machine unlearning", however, many aspects of the literature published thus far are disparate and lack consensus. In this paper, we summarise and compare seven state-of-the-art machine unlearning algorithms, consolidate definitions of core concepts used in the field, reconcile different approaches for evaluating algorithms, and discuss issues related to applying machine unlearning in practice.