 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan BERT Reason? Logically Equivalent Probes for Evaluating the Inference Capabilities of Language Models
May 02, 2020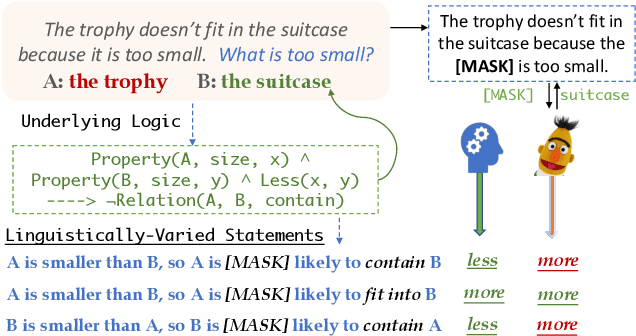



Pre-trained language models (PTLM) have greatly improved performance on commonsense inference benchmarks, however, it remains unclear whether they share a human's ability to consistently make correct inferences under perturbations. Prior studies of PTLMs have found inference deficits, but have failed to provide a systematic means of understanding whether these deficits are due to low inference abilities or poor inference robustness. In this work, we address this gap by developing a procedure that allows for the systematized probing of both PTLMs' inference abilities and robustness. Our procedure centers around the methodical creation of logically-equivalent, but syntactically-different sets of probes, of which we create a corpus of 14,400 probes coming from 60 logically-equivalent sets that can be used to probe PTLMs in three task settings. We find that despite the recent success of large PTLMs on commonsense benchmarks, their performances on our probes are no better than random guessing (even with fine-tuning) and are heavily dependent on biases--the poor overall performance, unfortunately, inhibits us from studying robustness. We hope our approach and initial probe set will assist future work in improving PTLMs' inference abilities, while also providing a probing set to test robustness under several linguistic variations--code and data will be released.
Birds have four legs?! NumerSense: Probing Numerical Commonsense Knowledge of Pre-trained Language Models
May 02, 2020
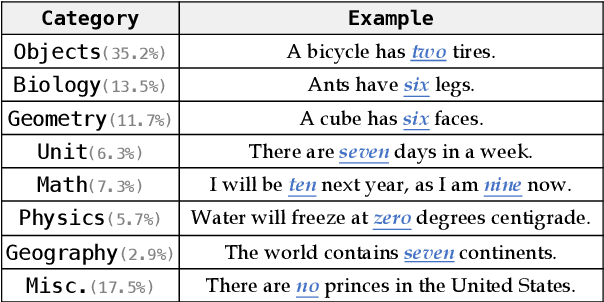
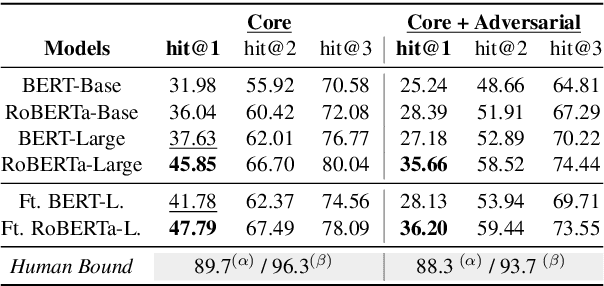
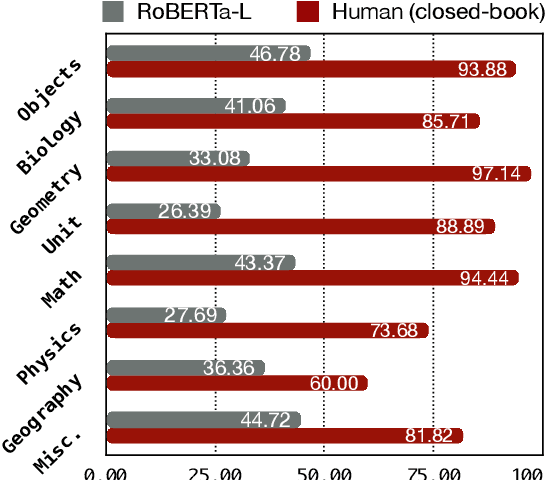
Recent works show that pre-trained masked language models, such as BERT, possess certain linguistic and commonsense knowledge. However, it remains to be seen what types of commonsense knowledge these models have access to. In this vein, we propose to study whether numerical commonsense knowledge -- commonsense knowledge that provides an understanding of the numeric relation between entities -- can be induced from pre-trained masked language models and to what extent is this access to knowledge robust against adversarial examples? To study this, we introduce a probing task with a diagnostic dataset, NumerSense, containing 3,145 masked-word-prediction probes. Surprisingly, our experiments and analysis reveal that: (1) BERT and its stronger variant RoBERTa perform poorly on our dataset prior to any fine-tuning; (2) fine-tuning with distant supervision does improve performance; (3) the best distantly supervised model still performs poorly when compared to humans (47.8% vs 96.3%).
LEAN-LIFE: A Label-Efficient Annotation Framework Towards Learning from Explanation
Apr 16, 2020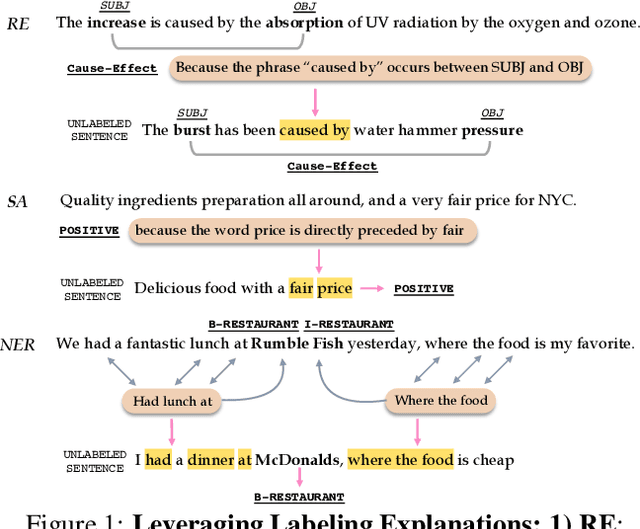
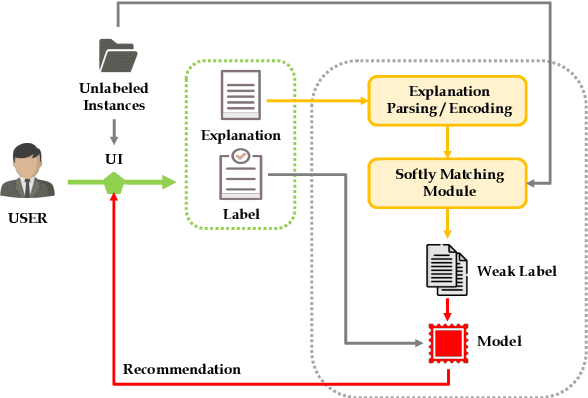

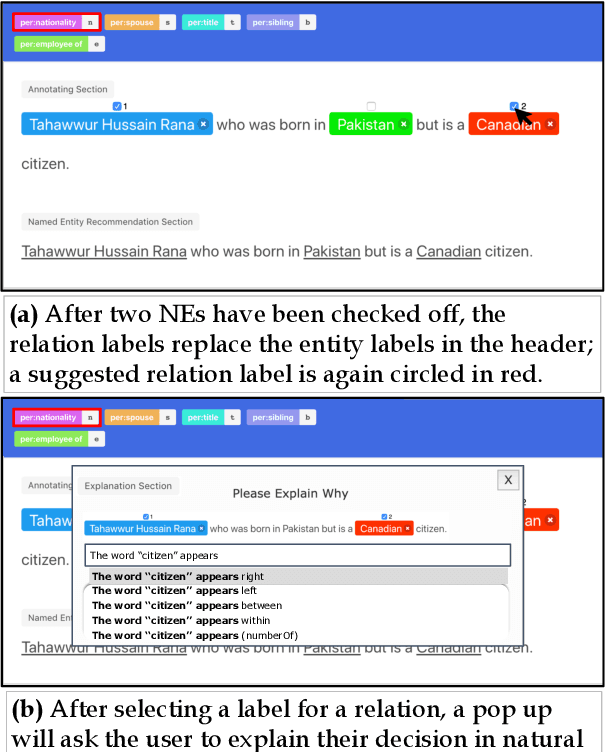
Successfully training a deep neural network demands a huge corpus of labeled data. However, each label only provides limited information to learn from and collecting the requisite number of labels involves massive human effort. In this work, we introduce LEAN-LIFE, a web-based, Label-Efficient AnnotatioN framework for sequence labeling and classification tasks, with an easy-to-use UI that not only allows an annotator to provide the needed labels for a task, but also enables LearnIng From Explanations for each labeling decision. Such explanations enable us to generate useful additional labeled data from unlabeled instances, bolstering the pool of available training data. On three popular NLP tasks (named entity recognition, relation extraction, sentiment analysis), we find that using this enhanced supervision allows our models to surpass competitive baseline F1 scores by more than 5-10 percentage points, while using 2X times fewer labeled instances. Our framework is the first to utilize this enhanced supervision technique and does so for three important tasks -- thus providing improved annotation recommendations to users and an ability to build datasets of (data, label, explanation) triples instead of the regular (data, label) pair.