 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBirds have four legs?! NumerSense: Probing Numerical Commonsense Knowledge of Pre-trained Language Models
Paper and Code
May 02, 2020
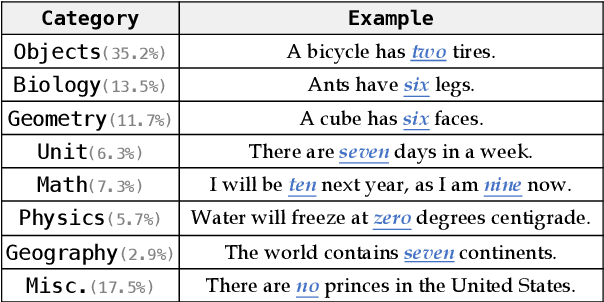
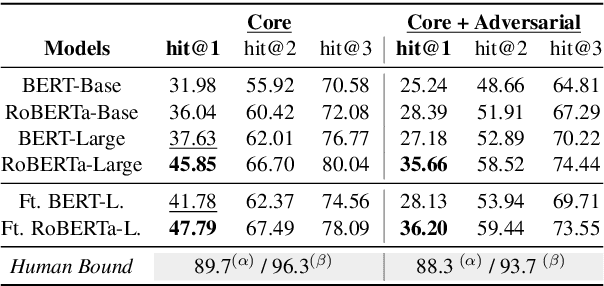
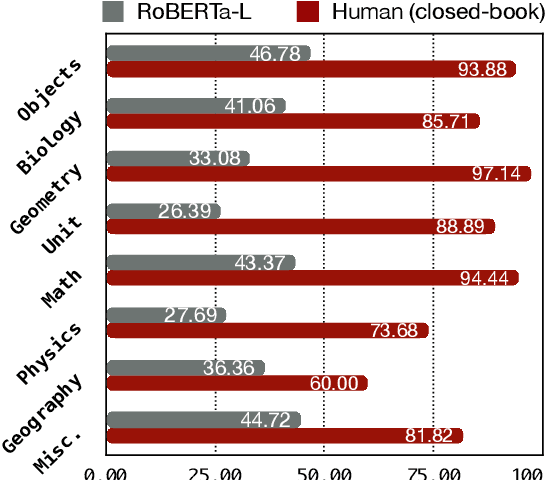
Recent works show that pre-trained masked language models, such as BERT, possess certain linguistic and commonsense knowledge. However, it remains to be seen what types of commonsense knowledge these models have access to. In this vein, we propose to study whether numerical commonsense knowledge -- commonsense knowledge that provides an understanding of the numeric relation between entities -- can be induced from pre-trained masked language models and to what extent is this access to knowledge robust against adversarial examples? To study this, we introduce a probing task with a diagnostic dataset, NumerSense, containing 3,145 masked-word-prediction probes. Surprisingly, our experiments and analysis reveal that: (1) BERT and its stronger variant RoBERTa perform poorly on our dataset prior to any fine-tuning; (2) fine-tuning with distant supervision does improve performance; (3) the best distantly supervised model still performs poorly when compared to humans (47.8% vs 96.3%).