 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Free Calibration of Statistical Confidence Sets
Nov 28, 2024

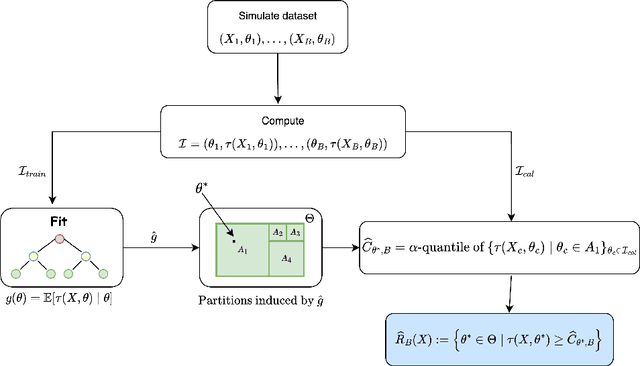
Constructing valid confidence sets is a crucial task in statistical inference, yet traditional methods often face challenges when dealing with complex models or limited observed sample sizes. These challenges are frequently encountered in modern applications, such as Likelihood-Free Inference (LFI). In these settings, confidence sets may fail to maintain a confidence level close to the nominal value. In this paper, we introduce two novel methods, TRUST and TRUST++, for calibrating confidence sets to achieve distribution-free conditional coverage. These methods rely entirely on simulated data from the statistical model to perform calibration. Leveraging insights from conformal prediction techniques adapted to the statistical inference context, our methods ensure both finite-sample local coverage and asymptotic conditional coverage as the number of simulations increases, even if n is small. They effectively handle nuisance parameters and provide computationally efficient uncertainty quantification for the estimated confidence sets. This allows users to assess whether additional simulations are necessary for robust inference. Through theoretical analysis and experiments on models with both tractable and intractable likelihoods, we demonstrate that our methods outperform existing approaches, particularly in small-sample regimes. This work bridges the gap between conformal prediction and statistical inference, offering practical tools for constructing valid confidence sets in complex models.
Regression Trees for Fast and Adaptive Prediction Intervals
Feb 13, 2024
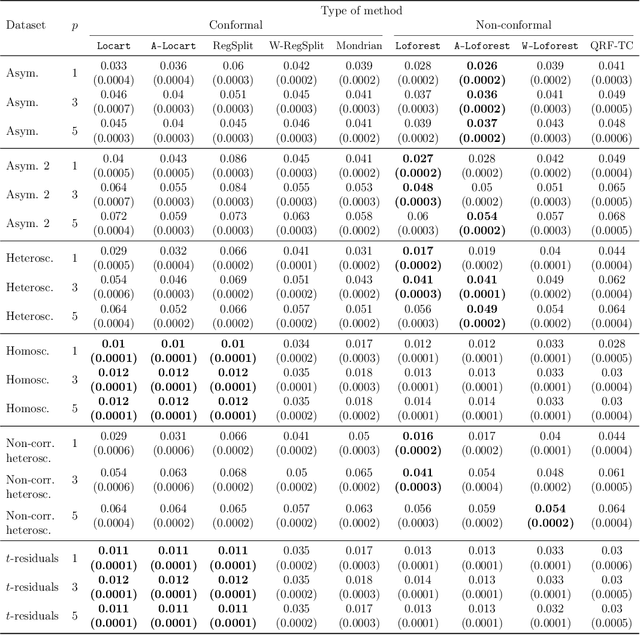


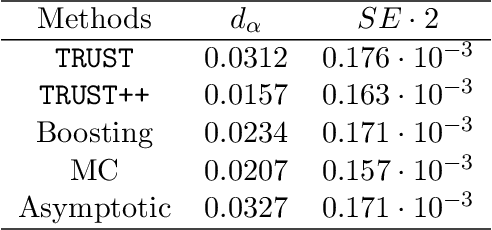
Predictive models make mistakes. Hence, there is a need to quantify the uncertainty associated with their predictions. Conformal inference has emerged as a powerful tool to create statistically valid prediction regions around point predictions, but its naive application to regression problems yields non-adaptive regions. New conformal scores, often relying upon quantile regressors or conditional density estimators, aim to address this limitation. Although they are useful for creating prediction bands, these scores are detached from the original goal of quantifying the uncertainty around an arbitrary predictive model. This paper presents a new, model-agnostic family of methods to calibrate prediction intervals for regression problems with local coverage guarantees. Our approach is based on pursuing the coarsest partition of the feature space that approximates conditional coverage. We create this partition by training regression trees and Random Forests on conformity scores. Our proposal is versatile, as it applies to various conformity scores and prediction settings and demonstrates superior scalability and performance compared to established baselines in simulated and real-world datasets. We provide a Python package clover that implements our methods using the standard scikit-learn interface.
Flexible conditional density estimation for time series
Jan 23, 2023This paper introduces FlexCodeTS, a new conditional density estimator for time series. FlexCodeTS is a flexible nonparametric conditional density estimator, which can be based on an arbitrary regression method. It is shown that FlexCodeTS inherits the rate of convergence of the chosen regression method. Hence, FlexCodeTS can adapt its convergence by employing the regression method that best fits the structure of data. From an empirical perspective, FlexCodeTS is compared to NNKCDE and GARCH in both simulated and real data. FlexCodeTS is shown to generally obtain the best performance among the selected methods according to either the CDE loss or the pinball loss.
Hierarchical clustering: visualization, feature importance and model selection
Nov 30, 2021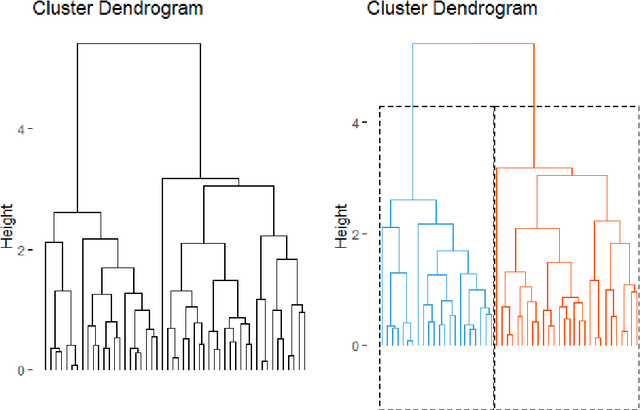
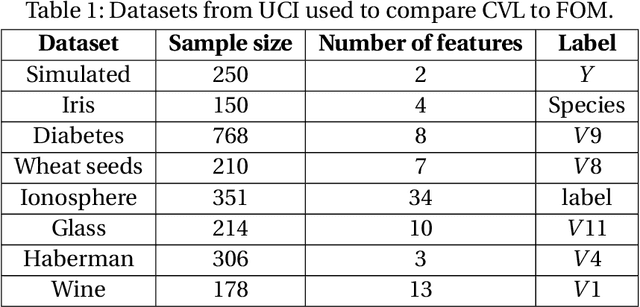
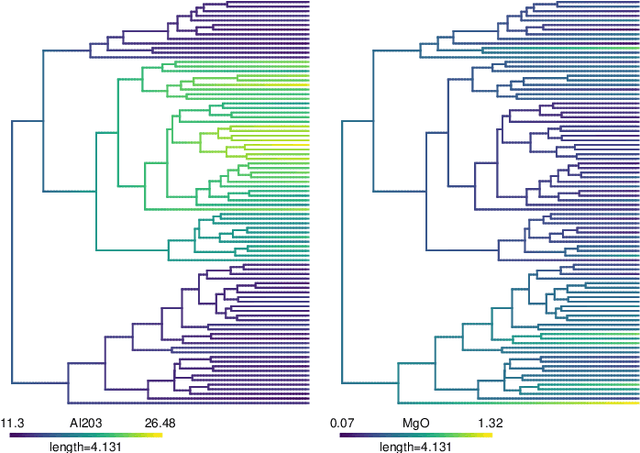

We propose methods for the analysis of hierarchical clustering that fully use the multi-resolution structure provided by a dendrogram. Specifically, we propose a loss for choosing between clustering methods, a feature importance score and a graphical tool for visualizing the segmentation of features in a dendrogram. Current approaches to these tasks lead to loss of information since they require the user to generate a single partition of the instances by cutting the dendrogram at a specified level. Our proposed methods, instead, use the full structure of the dendrogram. The key insight behind the proposed methods is to view a dendrogram as a phylogeny. This analogy permits the assignment of a feature value to each internal node of a tree through ancestral state reconstruction. Real and simulated datasets provide evidence that our proposed framework has desirable outcomes. We provide an R package that implements our methods.
CD-split: efficient conformal regions in high dimensions
Jul 24, 2020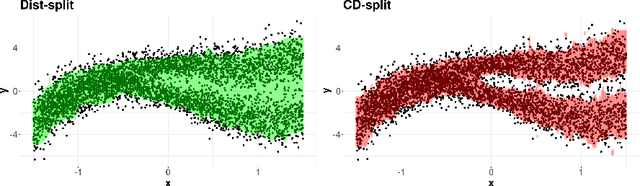
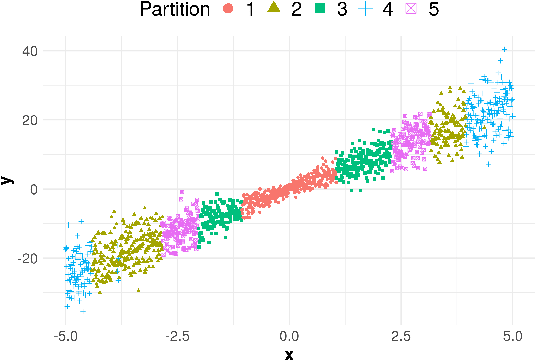
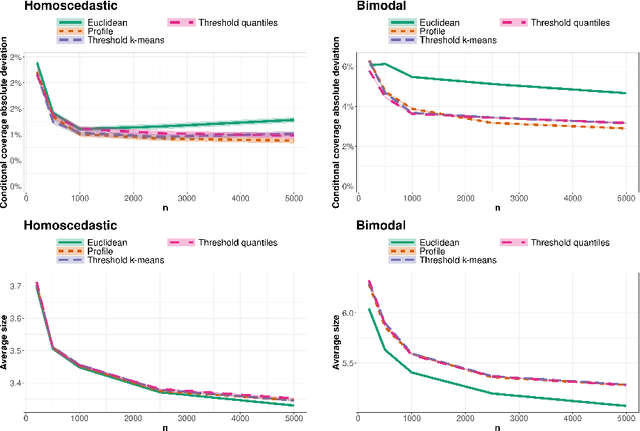
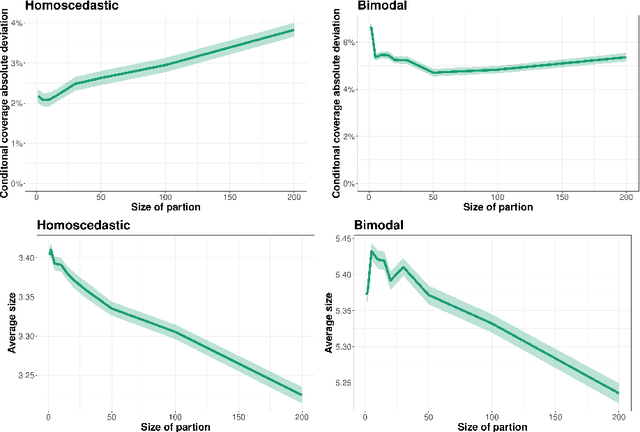
Conformal methods create prediction bands that control average coverage assuming solely i.i.d. data. Although the literature has mostly focused on prediction intervals, more general regions can often better represent uncertainty. For instance, a bimodal target is better represented by the union of two intervals. Such prediction regions are obtained by CD-split, which combines the split method and a data-driven partition of the feature space which scales to high dimensions. In this paper, we provide new theoretical properties and simulations related to CD-split. We show that CD-split converges asymptotically to the oracle highest density set. In particular, we show that CD-split satisfies local and asymptotic conditional validity. We also present many new simulations, which show how to tune CD-split and compare it to other methods in the literature. In a wide variety of these simulations, CD-split has a better conditional coverage and yields smaller prediction regions than other methods.
Distribution-free conditional predictive bands using density estimators
Oct 12, 2019
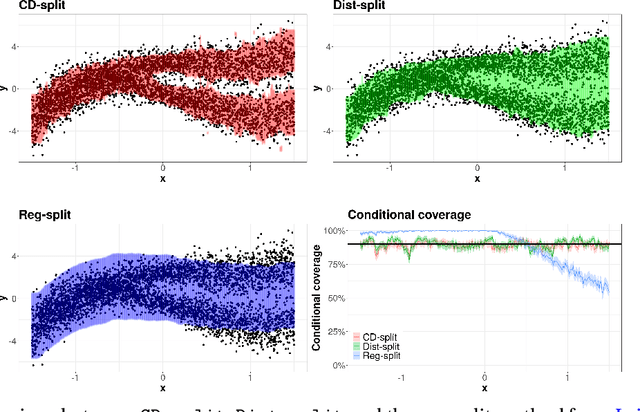
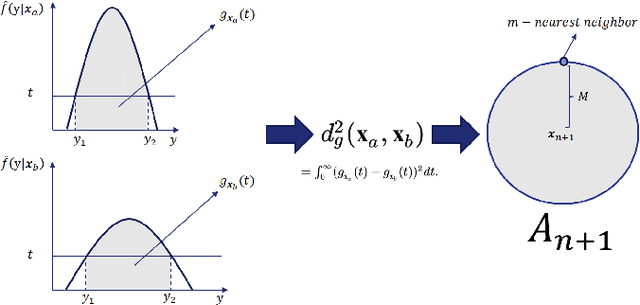
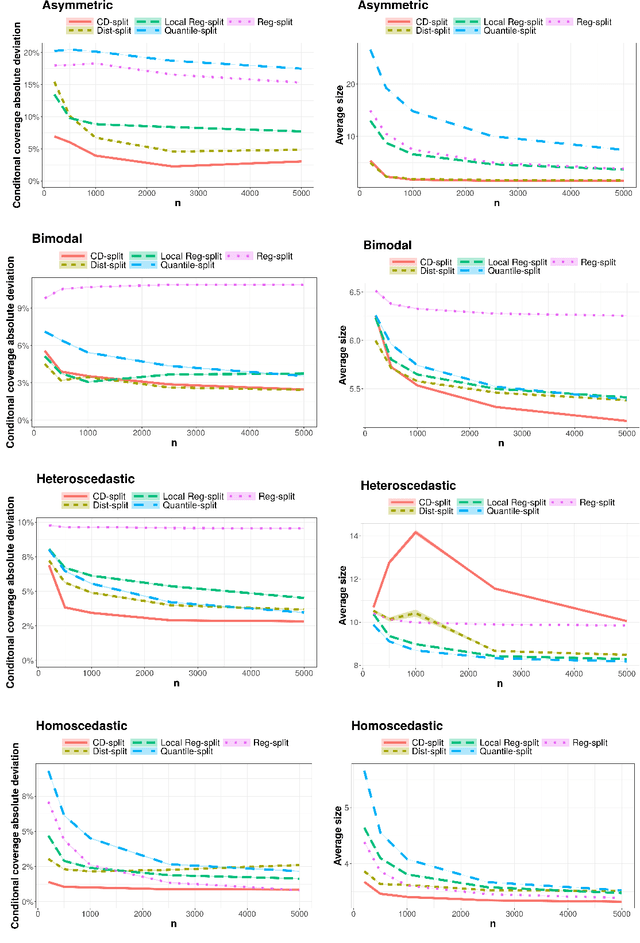
Conformal methods create prediction bands that control average coverage under no assumptions besides i.i.d. data. Besides average coverage, one might also desire to control conditional coverage, that is, coverage for every new testing point. However, without strong assumptions, conditional coverage is unachievable. Given this limitation, the literature has focused on methods with asymptotical conditional coverage. In order to obtain this property, these methods require strong conditions on the dependence between the target variable and the features. We introduce two conformal methods based on conditional density estimators that do not depend on this type of assumption to obtain asymptotic conditional coverage: Dist-split and CD-split. While Dist-split asymptotically obtains optimal intervals, which are easier to interpret than general regions, CD-split obtains optimal size regions, which are smaller than intervals. CD-split also obtains local coverage by creating a data-driven partition of the feature space that scales to high-dimensional settings and by generating prediction bands locally on the partition elements. In a wide variety of simulated scenarios, our methods have a better control of conditional coverage and have smaller length than previously proposed methods.