 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new LDA formulation with covariates
Feb 18, 2022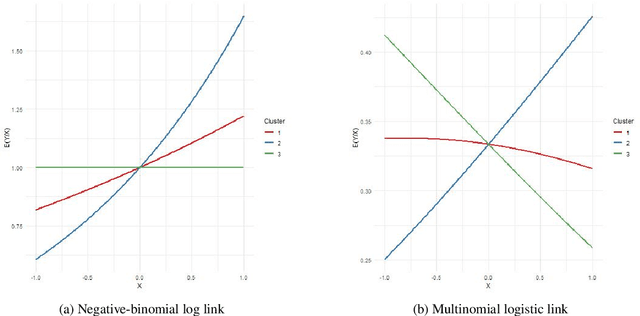
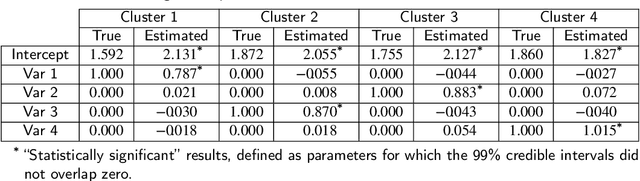
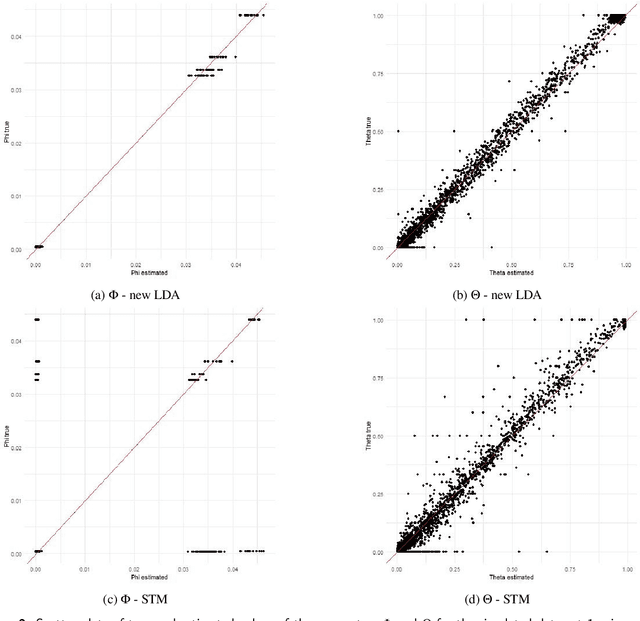
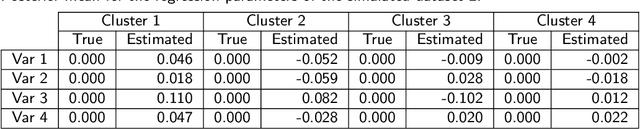
The Latent Dirichlet Allocation (LDA) model is a popular method for creating mixed-membership clusters. Despite having been originally developed for text analysis, LDA has been used for a wide range of other applications. We propose a new formulation for the LDA model which incorporates covariates. In this model, a negative binomial regression is embedded within LDA, enabling straight-forward interpretation of the regression coefficients and the analysis of the quantity of cluster-specific elements in each sampling units (instead of the analysis being focused on modeling the proportion of each cluster, as in Structural Topic Models). We use slice sampling within a Gibbs sampling algorithm to estimate model parameters. We rely on simulations to show how our algorithm is able to successfully retrieve the true parameter values and the ability to make predictions for the abundance matrix using the information given by the covariates. The model is illustrated using real data sets from three different areas: text-mining of Coronavirus articles, analysis of grocery shopping baskets, and ecology of tree species on Barro Colorado Island (Panama). This model allows the identification of mixed-membership clusters in discrete data and provides inference on the relationship between covariates and the abundance of these clusters.
CD-split: efficient conformal regions in high dimensions
Jul 24, 2020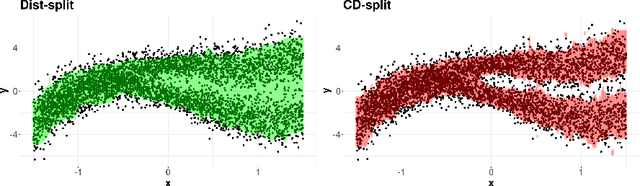
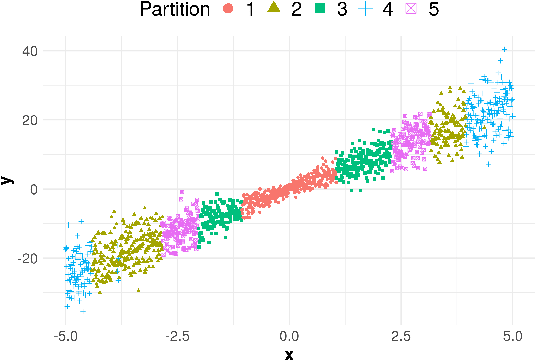
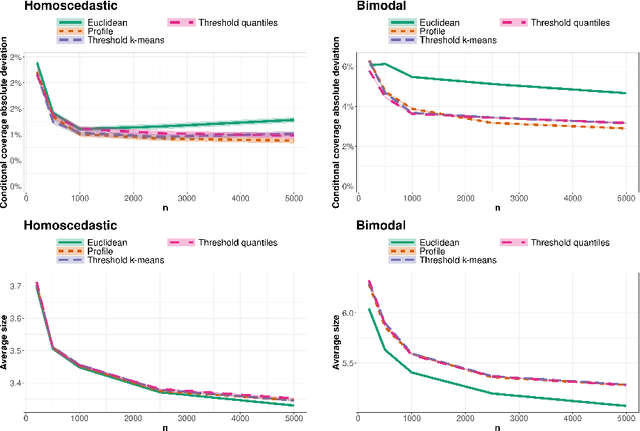
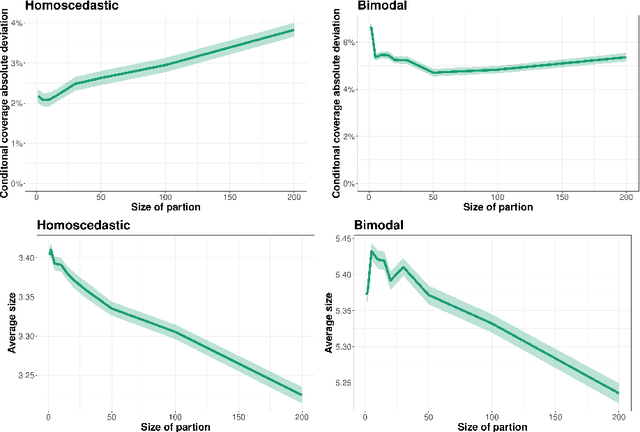
Conformal methods create prediction bands that control average coverage assuming solely i.i.d. data. Although the literature has mostly focused on prediction intervals, more general regions can often better represent uncertainty. For instance, a bimodal target is better represented by the union of two intervals. Such prediction regions are obtained by CD-split, which combines the split method and a data-driven partition of the feature space which scales to high dimensions. In this paper, we provide new theoretical properties and simulations related to CD-split. We show that CD-split converges asymptotically to the oracle highest density set. In particular, we show that CD-split satisfies local and asymptotic conditional validity. We also present many new simulations, which show how to tune CD-split and compare it to other methods in the literature. In a wide variety of these simulations, CD-split has a better conditional coverage and yields smaller prediction regions than other methods.