 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATOM: AdapTive and OptiMized dynamic temporal knowledge graph construction using LLMs
Oct 26, 2025In today's rapidly expanding data landscape, knowledge extraction from unstructured text is vital for real-time analytics, temporal inference, and dynamic memory frameworks. However, traditional static knowledge graph (KG) construction often overlooks the dynamic and time-sensitive nature of real-world data, limiting adaptability to continuous changes. Moreover, recent zero- or few-shot approaches that avoid domain-specific fine-tuning or reliance on prebuilt ontologies often suffer from instability across multiple runs, as well as incomplete coverage of key facts. To address these challenges, we introduce ATOM (AdapTive and OptiMized), a few-shot and scalable approach that builds and continuously updates Temporal Knowledge Graphs (TKGs) from unstructured texts. ATOM splits input documents into minimal, self-contained "atomic" facts, improving extraction exhaustivity and stability. Then, it constructs atomic TKGs from these facts while employing a dual-time modeling that distinguishes when information is observed from when it is valid. The resulting atomic TKGs are subsequently merged in parallel. Empirical evaluations demonstrate that ATOM achieves ~18% higher exhaustivity, ~17% better stability, and over 90% latency reduction compared to baseline methods, demonstrating a strong scalability potential for dynamic TKG construction.
Discovering Communities in Continuous-Time Temporal Networks by Optimizing L-Modularity
Oct 01, 2025Community detection is a fundamental problem in network analysis, with many applications in various fields. Extending community detection to the temporal setting with exact temporal accuracy, as required by real-world dynamic data, necessitates methods specifically adapted to the temporal nature of interactions. We introduce LAGO, a novel method for uncovering dynamic communities by greedy optimization of Longitudinal Modularity, a specific adaptation of Modularity for continuous-time networks. Unlike prior approaches that rely on time discretization or assume rigid community evolution, LAGO captures the precise moments when nodes enter and exit communities. We evaluate LAGO on synthetic benchmarks and real-world datasets, demonstrating its ability to efficiently uncover temporally and topologically coherent communities.
SEANN: A Domain-Informed Neural Network for Epidemiological Insights
Jan 17, 2025
In epidemiology, traditional statistical methods such as logistic regression, linear regression, and other parametric models are commonly employed to investigate associations between predictors and health outcomes. However, non-parametric machine learning techniques, such as deep neural networks (DNNs), coupled with explainable AI (XAI) tools, offer new opportunities for this task. Despite their potential, these methods face challenges due to the limited availability of high-quality, high-quantity data in this field. To address these challenges, we introduce SEANN, a novel approach for informed DNNs that leverages a prevalent form of domain-specific knowledge: Pooled Effect Sizes (PES). PESs are commonly found in published Meta-Analysis studies, in different forms, and represent a quantitative form of a scientific consensus. By direct integration within the learning procedure using a custom loss, we experimentally demonstrate significant improvements in the generalizability of predictive performances and the scientific plausibility of extracted relationships compared to a domain-knowledge agnostic neural network in a scarce and noisy data setting.
Inside Alameda Research: A Multi-Token Network Analysis
Sep 17, 2024
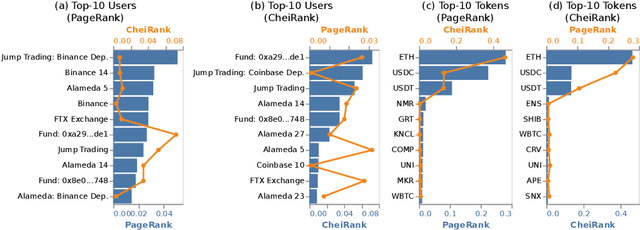


We analyze the token transfer network on Ethereum, focusing on accounts associated with Alameda Research, a cryptocurrency trading firm implicated in the misuse of FTX customer funds. Using a multi-token network representation, we examine node centralities and the network backbone to identify critical accounts, tokens, and activity groups. The temporal evolution of Alameda accounts reveals shifts in token accumulation and distribution patterns leading up to its bankruptcy in November 2022. Through network analysis, our work offers insights into the activities and dynamics that shape the DeFi ecosystem.
iText2KG: Incremental Knowledge Graphs Construction Using Large Language Models
Sep 05, 2024Most available data is unstructured, making it challenging to access valuable information. Automatically building Knowledge Graphs (KGs) is crucial for structuring data and making it accessible, allowing users to search for information effectively. KGs also facilitate insights, inference, and reasoning. Traditional NLP methods, such as named entity recognition and relation extraction, are key in information retrieval but face limitations, including the use of predefined entity types and the need for supervised learning. Current research leverages large language models' capabilities, such as zero- or few-shot learning. However, unresolved and semantically duplicated entities and relations still pose challenges, leading to inconsistent graphs and requiring extensive post-processing. Additionally, most approaches are topic-dependent. In this paper, we propose iText2KG, a method for incremental, topic-independent KG construction without post-processing. This plug-and-play, zero-shot method is applicable across a wide range of KG construction scenarios and comprises four modules: Document Distiller, Incremental Entity Extractor, Incremental Relation Extractor, and Graph Integrator and Visualization. Our method demonstrates superior performance compared to baseline methods across three scenarios: converting scientific papers to graphs, websites to graphs, and CVs to graphs.
Y Social: an LLM-powered Social Media Digital Twin
Aug 01, 2024



In this paper we introduce Y, a new-generation digital twin designed to replicate an online social media platform. Digital twins are virtual replicas of physical systems that allow for advanced analyses and experimentation. In the case of social media, a digital twin such as Y provides a powerful tool for researchers to simulate and understand complex online interactions. {\tt Y} leverages state-of-the-art Large Language Models (LLMs) to replicate sophisticated agent behaviors, enabling accurate simulations of user interactions, content dissemination, and network dynamics. By integrating these aspects, Y offers valuable insights into user engagement, information spread, and the impact of platform policies. Moreover, the integration of LLMs allows Y to generate nuanced textual content and predict user responses, facilitating the study of emergent phenomena in online environments. To better characterize the proposed digital twin, in this paper we describe the rationale behind its implementation, provide examples of the analyses that can be performed on the data it enables to be generated, and discuss its relevance for multidisciplinary research.
Redefining Event Types and Group Evolution in Temporal Data
Mar 11, 2024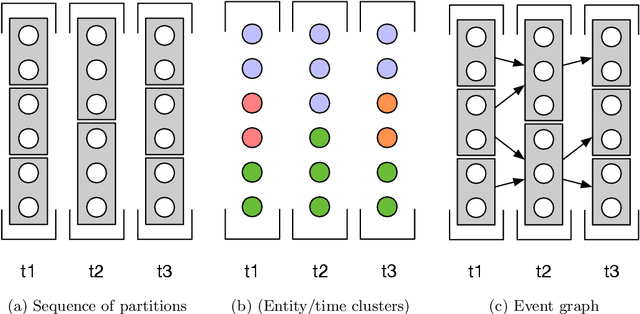

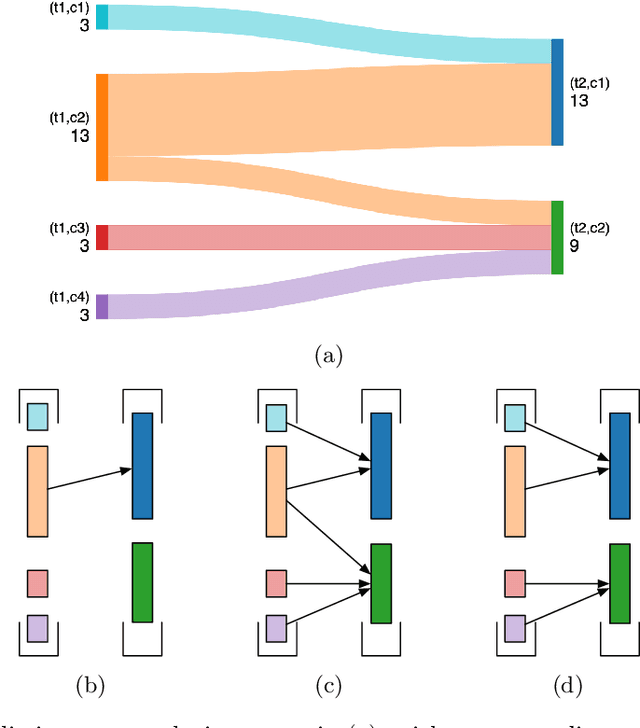

Groups -- such as clusters of points or communities of nodes -- are fundamental when addressing various data mining tasks. In temporal data, the predominant approach for characterizing group evolution has been through the identification of ``events". However, the events usually described in the literature, e.g., shrinks/growths, splits/merges, are often arbitrarily defined, creating a gap between such theoretical/predefined types and real-data group observations. Moving beyond existing taxonomies, we think of events as ``archetypes" characterized by a unique combination of quantitative dimensions that we call ``facets". Group dynamics are defined by their position within the facet space, where archetypal events occupy extremities. Thus, rather than enforcing strict event types, our approach can allow for hybrid descriptions of dynamics involving group proximity to multiple archetypes. We apply our framework to evolving groups from several face-to-face interaction datasets, showing it enables richer, more reliable characterization of group dynamics with respect to state-of-the-art methods, especially when the groups are subject to complex relationships. Our approach also offers intuitive solutions to common tasks related to dynamic group analysis, such as choosing an appropriate aggregation scale, quantifying partition stability, and evaluating event quality.
Pattern Analysis of Money Flow in the Bitcoin Blockchain
Jul 15, 2022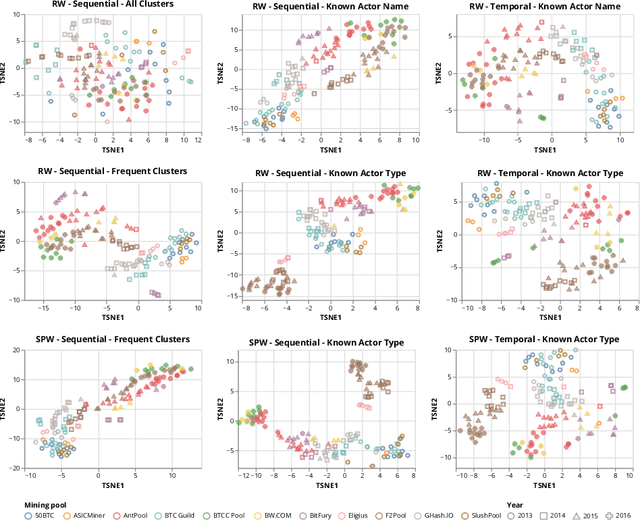


Bitcoin is the first and highest valued cryptocurrency that stores transactions in a publicly distributed ledger called the blockchain. Understanding the activity and behavior of Bitcoin actors is a crucial research topic as they are pseudonymous in the transaction network. In this article, we propose a method based on taint analysis to extract taint flows --dynamic networks representing the sequence of Bitcoins transferred from an initial source to other actors until dissolution. Then, we apply graph embedding methods to characterize taint flows. We evaluate our embedding method with taint flows from top mining pools and show that it can classify mining pools with high accuracy. We also found that taint flows from the same period show high similarity. Our work proves that tracing the money flows can be a promising approach to classifying source actors and characterizing different money flow patterns