 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEANN: A Domain-Informed Neural Network for Epidemiological Insights
Jan 17, 2025
In epidemiology, traditional statistical methods such as logistic regression, linear regression, and other parametric models are commonly employed to investigate associations between predictors and health outcomes. However, non-parametric machine learning techniques, such as deep neural networks (DNNs), coupled with explainable AI (XAI) tools, offer new opportunities for this task. Despite their potential, these methods face challenges due to the limited availability of high-quality, high-quantity data in this field. To address these challenges, we introduce SEANN, a novel approach for informed DNNs that leverages a prevalent form of domain-specific knowledge: Pooled Effect Sizes (PES). PESs are commonly found in published Meta-Analysis studies, in different forms, and represent a quantitative form of a scientific consensus. By direct integration within the learning procedure using a custom loss, we experimentally demonstrate significant improvements in the generalizability of predictive performances and the scientific plausibility of extracted relationships compared to a domain-knowledge agnostic neural network in a scarce and noisy data setting.
RPS: A Generic Reservoir Patterns Sampler
Oct 31, 2024Efficient learning from streaming data is important for modern data analysis due to the continuous and rapid evolution of data streams. Despite significant advancements in stream pattern mining, challenges persist, particularly in managing complex data streams like sequential and weighted itemsets. While reservoir sampling serves as a fundamental method for randomly selecting fixed-size samples from data streams, its application to such complex patterns remains largely unexplored. In this study, we introduce an approach that harnesses a weighted reservoir to facilitate direct pattern sampling from streaming batch data, thus ensuring scalability and efficiency. We present a generic algorithm capable of addressing temporal biases and handling various pattern types, including sequential, weighted, and unweighted itemsets. Through comprehensive experiments conducted on real-world datasets, we evaluate the effectiveness of our method, showcasing its ability to construct accurate incremental online classifiers for sequential data. Our approach not only enables previously unusable online machine learning models for sequential data to achieve accuracy comparable to offline baselines but also represents significant progress in the development of incremental online sequential itemset classifiers.
Scalable Sampling for High Utility Patterns
Oct 30, 2024Discovering valuable insights from data through meaningful associations is a crucial task. However, it becomes challenging when trying to identify representative patterns in quantitative databases, especially with large datasets, as enumeration-based strategies struggle due to the vast search space involved. To tackle this challenge, output space sampling methods have emerged as a promising solution thanks to its ability to discover valuable patterns with reduced computational overhead. However, existing sampling methods often encounter limitations when dealing with large quantitative database, resulting in scalability-related challenges. In this work, we propose a novel high utility pattern sampling algorithm and its on-disk version both designed for large quantitative databases based on two original theorems. Our approach ensures both the interactivity required for user-centered methods and strong statistical guarantees through random sampling. Thanks to our method, users can instantly discover relevant and representative utility pattern, facilitating efficient exploration of the database within seconds. To demonstrate the interest of our approach, we present a compelling use case involving archaeological knowledge graph sub-profiles discovery. Experiments on semantic and none-semantic quantitative databases show that our approach outperforms the state-of-the art methods.
On GNN explanability with activation rules
Jun 17, 2024


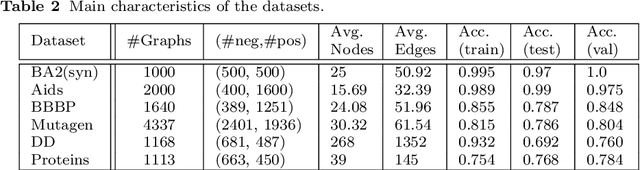
GNNs are powerful models based on node representation learning that perform particularly well in many machine learning problems related to graphs. The major obstacle to the deployment of GNNs is mostly a problem of societal acceptability and trustworthiness, properties which require making explicit the internal functioning of such models. Here, we propose to mine activation rules in the hidden layers to understand how the GNNs perceive the world. The problem is not to discover activation rules that are individually highly discriminating for an output of the model. Instead, the challenge is to provide a small set of rules that cover all input graphs. To this end, we introduce the subjective activation pattern domain. We define an effective and principled algorithm to enumerate activations rules in each hidden layer. The proposed approach for quantifying the interest of these rules is rooted in information theory and is able to account for background knowledge on the input graph data. The activation rules can then be redescribed thanks to pattern languages involving interpretable features. We show that the activation rules provide insights on the characteristics used by the GNN to classify the graphs. Especially, this allows to identify the hidden features built by the GNN through its different layers. Also, these rules can subsequently be used for explaining GNN decisions. Experiments on both synthetic and real-life datasets show highly competitive performance, with up to 200% improvement in fidelity on explaining graph classification over the SOTA methods.
Mining Java Memory Errors using Subjective Interesting Subgroups with Hierarchical Targets
Oct 01, 2023



Software applications, especially Enterprise Resource Planning (ERP) systems, are crucial to the day-to-day operations of many industries. Therefore, it is essential to maintain these systems effectively using tools that can identify, diagnose, and mitigate their incidents. One promising data-driven approach is the Subgroup Discovery (SD) technique, a data mining method that can automatically mine incident datasets and extract discriminant patterns to identify the root causes of issues. However, current SD solutions have limitations in handling complex target concepts with multiple attributes organized hierarchically. To illustrate this scenario, we examine the case of Java out-of-memory incidents among several possible applications. We have a dataset that describes these incidents, including their context and the types of Java objects occupying memory when it reaches saturation, with these types arranged hierarchically. This scenario inspires us to propose a novel Subgroup Discovery approach that can handle complex target concepts with hierarchies. To achieve this, we design a pattern syntax and a quality measure that ensure the identified subgroups are relevant, non-redundant, and resilient to noise. To achieve the desired quality measure, we use the Subjective Interestingness model that incorporates prior knowledge about the data and promotes patterns that are both informative and surprising relative to that knowledge. We apply this framework to investigate out-of-memory errors and demonstrate its usefulness in incident diagnosis. To validate the effectiveness of our approach and the quality of the identified patterns, we present an empirical study. The source code and data used in the evaluation are publicly accessible, ensuring transparency and reproducibility.
Interpretable Summaries of Black Box Incident Triaging with Subgroup Discovery
Aug 06, 2021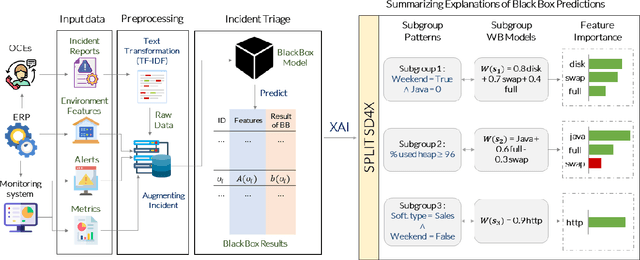
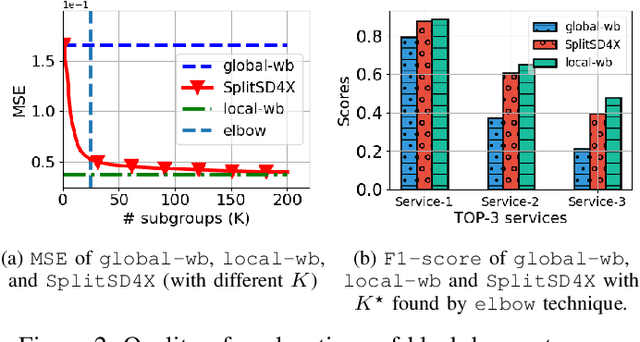
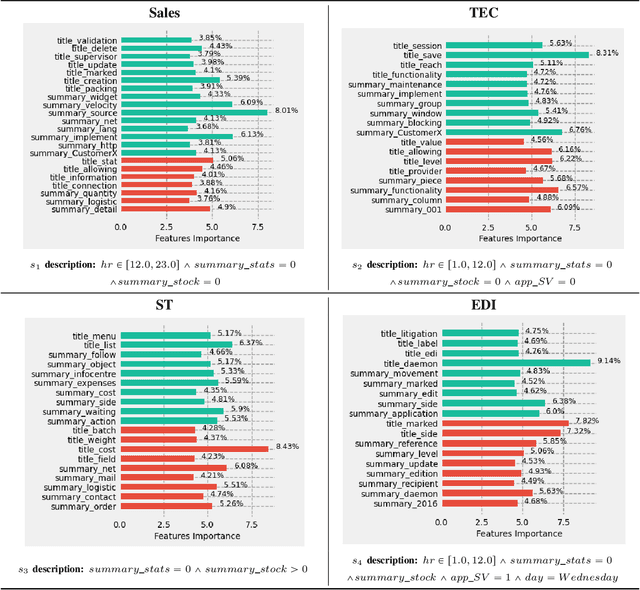
The need of predictive maintenance comes with an increasing number of incidents reported by monitoring systems and equipment/software users. In the front line, on-call engineers (OCEs) have to quickly assess the degree of severity of an incident and decide which service to contact for corrective actions. To automate these decisions, several predictive models have been proposed, but the most efficient models are opaque (say, black box), strongly limiting their adoption. In this paper, we propose an efficient black box model based on 170K incidents reported to our company over the last 7 years and emphasize on the need of automating triage when incidents are massively reported on thousands of servers running our product, an ERP. Recent developments in eXplainable Artificial Intelligence (XAI) help in providing global explanations to the model, but also, and most importantly, with local explanations for each model prediction/outcome. Sadly, providing a human with an explanation for each outcome is not conceivable when dealing with an important number of daily predictions. To address this problem, we propose an original data-mining method rooted in Subgroup Discovery, a pattern mining technique with the natural ability to group objects that share similar explanations of their black box predictions and provide a description for each group. We evaluate this approach and present our preliminary results which give us good hope towards an effective OCE's adoption. We believe that this approach provides a new way to address the problem of model agnostic outcome explanation.
Sequential recommendation with metric models based on frequent sequences
Aug 12, 2020


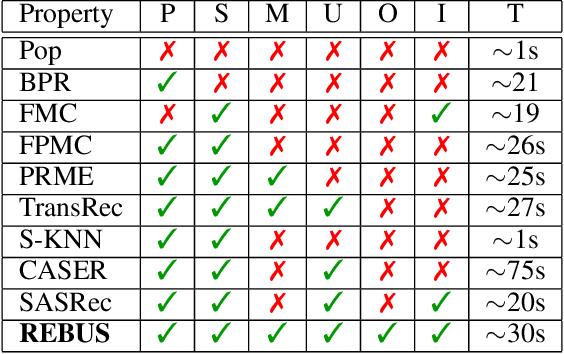
Modeling user preferences (long-term history) and user dynamics (short-term history) is of greatest importance to build efficient sequential recommender systems. The challenge lies in the successful combination of the whole user's history and his recent actions (sequential dynamics) to provide personalized recommendations. Existing methods capture the sequential dynamics of a user using fixed-order Markov chains (usually first order chains) regardless of the user, which limits both the impact of the past of the user on the recommendation and the ability to adapt its length to the user profile. In this article, we propose to use frequent sequences to identify the most relevant part of the user history for the recommendation. The most salient items are then used in a unified metric model that embeds items based on user preferences and sequential dynamics. Extensive experiments demonstrate that our method outperforms state-of-the-art, especially on sparse datasets. We show that considering sequences of varying lengths improves the recommendations and we also emphasize that these sequences provide explanations on the recommendation.