 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIOps Solutions for Incident Management: Technical Guidelines and A Comprehensive Literature Review
Apr 01, 2024



The management of modern IT systems poses unique challenges, necessitating scalability, reliability, and efficiency in handling extensive data streams. Traditional methods, reliant on manual tasks and rule-based approaches, prove inefficient for the substantial data volumes and alerts generated by IT systems. Artificial Intelligence for Operating Systems (AIOps) has emerged as a solution, leveraging advanced analytics like machine learning and big data to enhance incident management. AIOps detects and predicts incidents, identifies root causes, and automates healing actions, improving quality and reducing operational costs. However, despite its potential, the AIOps domain is still in its early stages, decentralized across multiple sectors, and lacking standardized conventions. Research and industrial contributions are distributed without consistent frameworks for data management, target problems, implementation details, requirements, and capabilities. This study proposes an AIOps terminology and taxonomy, establishing a structured incident management procedure and providing guidelines for constructing an AIOps framework. The research also categorizes contributions based on criteria such as incident management tasks, application areas, data sources, and technical approaches. The goal is to provide a comprehensive review of technical and research aspects in AIOps for incident management, aiming to structure knowledge, identify gaps, and establish a foundation for future developments in the field.
DeepLSH: Deep Locality-Sensitive Hash Learning for Fast and Efficient Near-Duplicate Crash Report Detection
Oct 10, 2023Automatic crash bucketing is a crucial phase in the software development process for efficiently triaging bug reports. It generally consists in grouping similar reports through clustering techniques. However, with real-time streaming bug collection, systems are needed to quickly answer the question: What are the most similar bugs to a new one?, that is, efficiently find near-duplicates. It is thus natural to consider nearest neighbors search to tackle this problem and especially the well-known locality-sensitive hashing (LSH) to deal with large datasets due to its sublinear performance and theoretical guarantees on the similarity search accuracy. Surprisingly, LSH has not been considered in the crash bucketing literature. It is indeed not trivial to derive hash functions that satisfy the so-called locality-sensitive property for the most advanced crash bucketing metrics. Consequently, we study in this paper how to leverage LSH for this task. To be able to consider the most relevant metrics used in the literature, we introduce DeepLSH, a Siamese DNN architecture with an original loss function, that perfectly approximates the locality-sensitivity property even for Jaccard and Cosine metrics for which exact LSH solutions exist. We support this claim with a series of experiments on an original dataset, which we make available.
Mining Java Memory Errors using Subjective Interesting Subgroups with Hierarchical Targets
Oct 01, 2023



Software applications, especially Enterprise Resource Planning (ERP) systems, are crucial to the day-to-day operations of many industries. Therefore, it is essential to maintain these systems effectively using tools that can identify, diagnose, and mitigate their incidents. One promising data-driven approach is the Subgroup Discovery (SD) technique, a data mining method that can automatically mine incident datasets and extract discriminant patterns to identify the root causes of issues. However, current SD solutions have limitations in handling complex target concepts with multiple attributes organized hierarchically. To illustrate this scenario, we examine the case of Java out-of-memory incidents among several possible applications. We have a dataset that describes these incidents, including their context and the types of Java objects occupying memory when it reaches saturation, with these types arranged hierarchically. This scenario inspires us to propose a novel Subgroup Discovery approach that can handle complex target concepts with hierarchies. To achieve this, we design a pattern syntax and a quality measure that ensure the identified subgroups are relevant, non-redundant, and resilient to noise. To achieve the desired quality measure, we use the Subjective Interestingness model that incorporates prior knowledge about the data and promotes patterns that are both informative and surprising relative to that knowledge. We apply this framework to investigate out-of-memory errors and demonstrate its usefulness in incident diagnosis. To validate the effectiveness of our approach and the quality of the identified patterns, we present an empirical study. The source code and data used in the evaluation are publicly accessible, ensuring transparency and reproducibility.
On-Premise AIOps Infrastructure for a Software Editor SME: An Experience Report
Aug 22, 2023Information Technology has become a critical component in various industries, leading to an increased focus on software maintenance and monitoring. With the complexities of modern software systems, traditional maintenance approaches have become insufficient. The concept of AIOps has emerged to enhance predictive maintenance using Big Data and Machine Learning capabilities. However, exploiting AIOps requires addressing several challenges related to the complexity of data and incident management. Commercial solutions exist, but they may not be suitable for certain companies due to high costs, data governance issues, and limitations in covering private software. This paper investigates the feasibility of implementing on-premise AIOps solutions by leveraging open-source tools. We introduce a comprehensive AIOps infrastructure that we have successfully deployed in our company, and we provide the rationale behind different choices that we made to build its various components. Particularly, we provide insights into our approach and criteria for selecting a data management system and we explain its integration. Our experience can be beneficial for companies seeking to internally manage their software maintenance processes with a modern AIOps approach.
How Can Subgroup Discovery Help AIOps?
Sep 10, 2021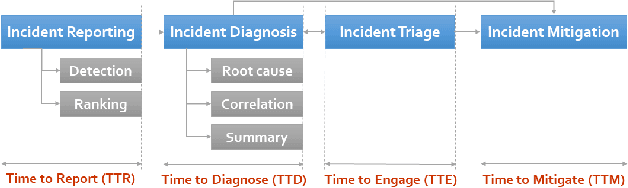
The genuine supervision of modern IT systems brings new challenges as it requires higher standards of scalability, reliability and efficiency when analysing and monitoring big data streams. Rule-based inference engines are a key component of maintenance systems in detecting anomalies and automating their resolution. However, they remain confined to simple and general rules and cannot handle the huge amount of data, nor the large number of alerts raised by IT systems, a lesson learned from expert systems era. Artificial Intelligence for Operation Systems (AIOps) proposes to take advantage of advanced analytics and machine learning on big data to improve and automate every step of supervision systems and aid incident management in detecting outages, identifying root causes and applying appropriate healing actions. Nevertheless, the best AIOps techniques rely on opaque models, strongly limiting their adoption. As a part of this PhD thesis, we study how Subgroup Discovery can help AIOps. This promising data mining technique offers possibilities to extract interesting hypothesis from data and understand the underlying process behind predictive models. To ensure relevancy of our propositions, this project involves both data mining researchers and practitioners from Infologic, a French software editor.
"What makes my queries slow?": Subgroup Discovery for SQL Workload Analysis
Aug 09, 2021

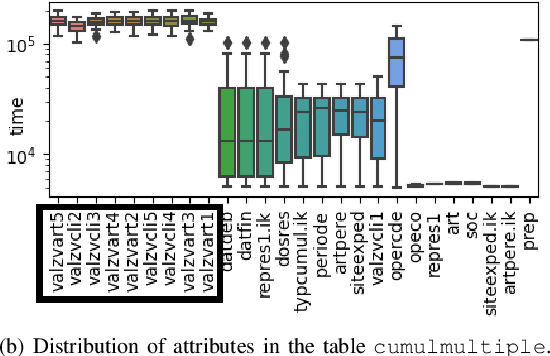
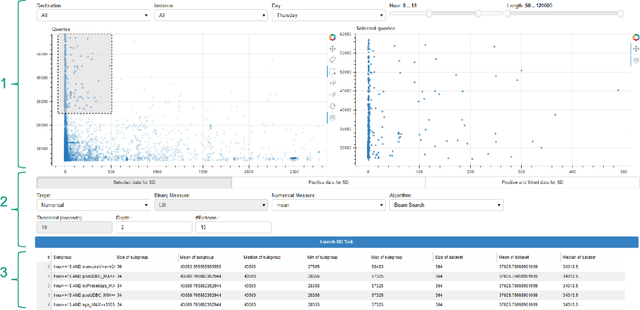
Among daily tasks of database administrators (DBAs), the analysis of query workloads to identify schema issues and improving performances is crucial. Although DBAs can easily pinpoint queries repeatedly causing performance issues, it remains challenging to automatically identify subsets of queries that share some properties only (a pattern) and simultaneously foster some target measures, such as execution time. Patterns are defined on combinations of query clauses, environment variables, database alerts and metrics and help answer questions like what makes SQL queries slow? What makes I/O communications high? Automatically discovering these patterns in a huge search space and providing them as hypotheses for helping to localize issues and root-causes is important in the context of explainable AI. To tackle it, we introduce an original approach rooted on Subgroup Discovery. We show how to instantiate and develop this generic data-mining framework to identify potential causes of SQL workloads issues. We believe that such data-mining technique is not trivial to apply for DBAs. As such, we also provide a visualization tool for interactive knowledge discovery. We analyse a one week workload from hundreds of databases from our company, make both the dataset and source code available, and experimentally show that insightful hypotheses can be discovered.
Interpretable Summaries of Black Box Incident Triaging with Subgroup Discovery
Aug 06, 2021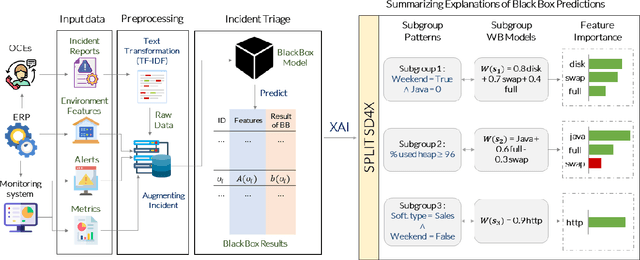
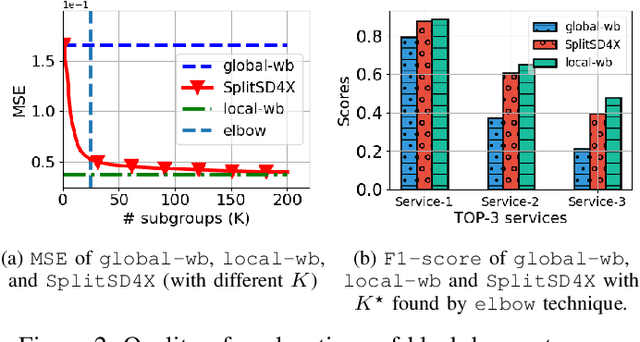
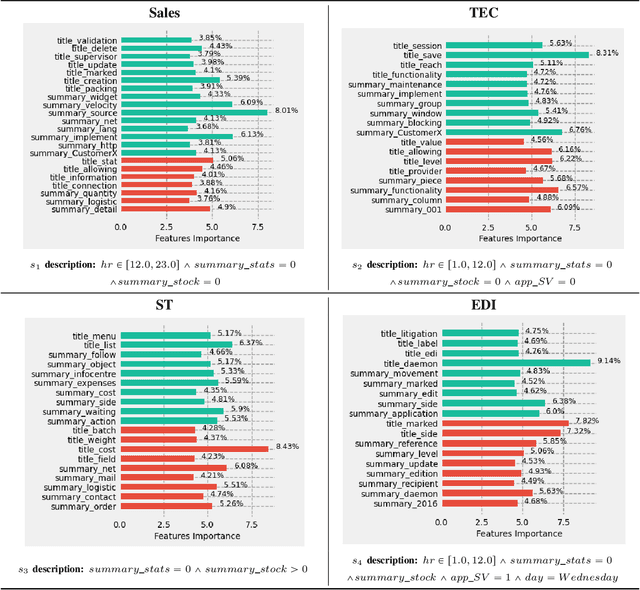
The need of predictive maintenance comes with an increasing number of incidents reported by monitoring systems and equipment/software users. In the front line, on-call engineers (OCEs) have to quickly assess the degree of severity of an incident and decide which service to contact for corrective actions. To automate these decisions, several predictive models have been proposed, but the most efficient models are opaque (say, black box), strongly limiting their adoption. In this paper, we propose an efficient black box model based on 170K incidents reported to our company over the last 7 years and emphasize on the need of automating triage when incidents are massively reported on thousands of servers running our product, an ERP. Recent developments in eXplainable Artificial Intelligence (XAI) help in providing global explanations to the model, but also, and most importantly, with local explanations for each model prediction/outcome. Sadly, providing a human with an explanation for each outcome is not conceivable when dealing with an important number of daily predictions. To address this problem, we propose an original data-mining method rooted in Subgroup Discovery, a pattern mining technique with the natural ability to group objects that share similar explanations of their black box predictions and provide a description for each group. We evaluate this approach and present our preliminary results which give us good hope towards an effective OCE's adoption. We believe that this approach provides a new way to address the problem of model agnostic outcome explanation.