 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"What makes my queries slow?": Subgroup Discovery for SQL Workload Analysis
Aug 09, 2021

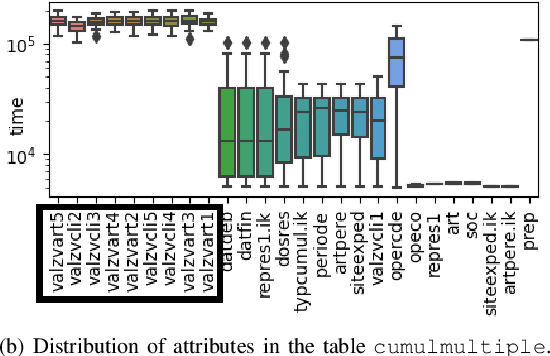
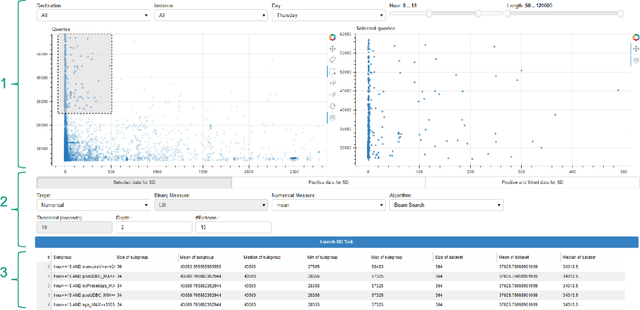
Among daily tasks of database administrators (DBAs), the analysis of query workloads to identify schema issues and improving performances is crucial. Although DBAs can easily pinpoint queries repeatedly causing performance issues, it remains challenging to automatically identify subsets of queries that share some properties only (a pattern) and simultaneously foster some target measures, such as execution time. Patterns are defined on combinations of query clauses, environment variables, database alerts and metrics and help answer questions like what makes SQL queries slow? What makes I/O communications high? Automatically discovering these patterns in a huge search space and providing them as hypotheses for helping to localize issues and root-causes is important in the context of explainable AI. To tackle it, we introduce an original approach rooted on Subgroup Discovery. We show how to instantiate and develop this generic data-mining framework to identify potential causes of SQL workloads issues. We believe that such data-mining technique is not trivial to apply for DBAs. As such, we also provide a visualization tool for interactive knowledge discovery. We analyse a one week workload from hundreds of databases from our company, make both the dataset and source code available, and experimentally show that insightful hypotheses can be discovered.