 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPS: A Generic Reservoir Patterns Sampler
Oct 31, 2024Efficient learning from streaming data is important for modern data analysis due to the continuous and rapid evolution of data streams. Despite significant advancements in stream pattern mining, challenges persist, particularly in managing complex data streams like sequential and weighted itemsets. While reservoir sampling serves as a fundamental method for randomly selecting fixed-size samples from data streams, its application to such complex patterns remains largely unexplored. In this study, we introduce an approach that harnesses a weighted reservoir to facilitate direct pattern sampling from streaming batch data, thus ensuring scalability and efficiency. We present a generic algorithm capable of addressing temporal biases and handling various pattern types, including sequential, weighted, and unweighted itemsets. Through comprehensive experiments conducted on real-world datasets, we evaluate the effectiveness of our method, showcasing its ability to construct accurate incremental online classifiers for sequential data. Our approach not only enables previously unusable online machine learning models for sequential data to achieve accuracy comparable to offline baselines but also represents significant progress in the development of incremental online sequential itemset classifiers.
The Structure and Dynamics of Knowledge Graphs, with Superficiality
May 16, 2023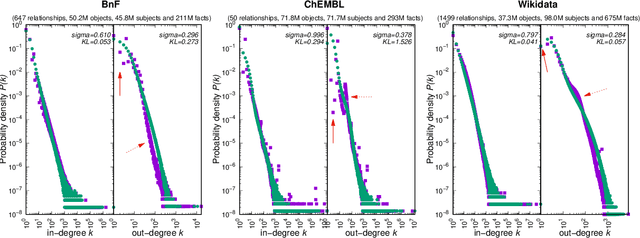
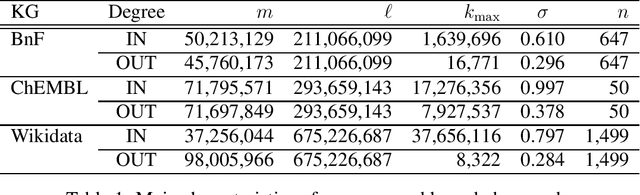
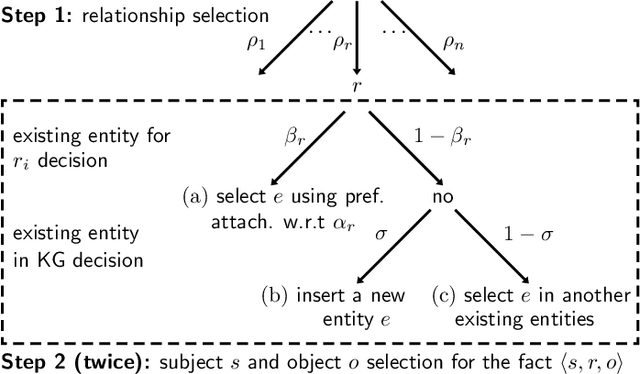
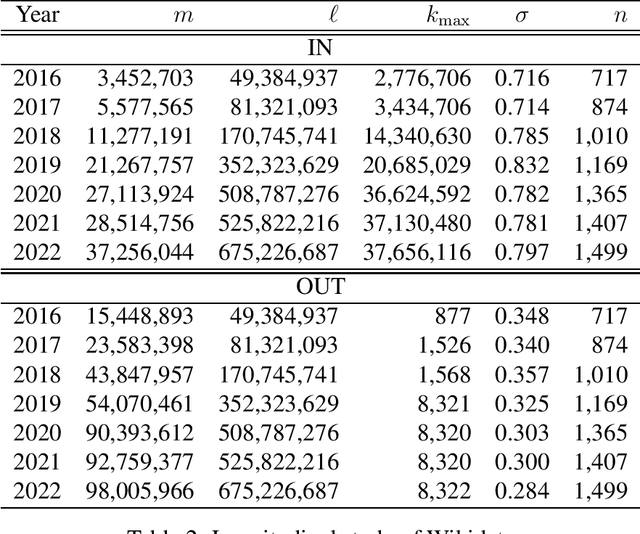
Large knowledge graphs combine human knowledge garnered from projects ranging from academia and institutions to enterprises and crowdsourcing. Within such graphs, each relationship between two nodes represents a basic fact involving these two entities. The diversity of the semantics of relationships constitutes the richness of knowledge graphs, leading to the emergence of singular topologies, sometimes chaotic in appearance. However, this complex characteristic can be modeled in a simple way by introducing the concept of superficiality, which controls the overlap between relationships whose facts are generated independently. Superficiality also regulates the balance of the global distribution of knowledge by determining the proportion of misdescribed entities. This is the first model for the structure and dynamics of knowledge graphs. It leads to a better understanding of formal knowledge acquisition and organization.