 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATOM: AdapTive and OptiMized dynamic temporal knowledge graph construction using LLMs
Oct 26, 2025In today's rapidly expanding data landscape, knowledge extraction from unstructured text is vital for real-time analytics, temporal inference, and dynamic memory frameworks. However, traditional static knowledge graph (KG) construction often overlooks the dynamic and time-sensitive nature of real-world data, limiting adaptability to continuous changes. Moreover, recent zero- or few-shot approaches that avoid domain-specific fine-tuning or reliance on prebuilt ontologies often suffer from instability across multiple runs, as well as incomplete coverage of key facts. To address these challenges, we introduce ATOM (AdapTive and OptiMized), a few-shot and scalable approach that builds and continuously updates Temporal Knowledge Graphs (TKGs) from unstructured texts. ATOM splits input documents into minimal, self-contained "atomic" facts, improving extraction exhaustivity and stability. Then, it constructs atomic TKGs from these facts while employing a dual-time modeling that distinguishes when information is observed from when it is valid. The resulting atomic TKGs are subsequently merged in parallel. Empirical evaluations demonstrate that ATOM achieves ~18% higher exhaustivity, ~17% better stability, and over 90% latency reduction compared to baseline methods, demonstrating a strong scalability potential for dynamic TKG construction.
Fréchet regression for multi-label feature selection with implicit regularization
Dec 24, 2024

Fr\'echet regression extends linear regression to model complex responses in metric spaces, making it particularly relevant for multi-label regression, where each instance can have multiple associated labels. However, variable selection within this framework remains underexplored. In this paper, we pro pose a novel variable selection method that employs implicit regularization instead of traditional explicit regularization approaches, which can introduce bias. Our method effectively captures nonlinear interactions between predic tors and responses while promoting model sparsity. We provide theoretical results demonstrating selection consistency and illustrate the performance of our approach through numerical examples
Implicit Regularization for Multi-label Feature Selection
Nov 18, 2024In this paper, we address the problem of feature selection in the context of multi-label learning, by using a new estimator based on implicit regularization and label embedding. Unlike the sparse feature selection methods that use a penalized estimator with explicit regularization terms such as $l_{2,1}$-norm, MCP or SCAD, we propose a simple alternative method via Hadamard product parameterization. In order to guide the feature selection process, a latent semantic of multi-label information method is adopted, as a label embedding. Experimental results on some known benchmark datasets suggest that the proposed estimator suffers much less from extra bias, and may lead to benign overfitting.
Multi-View Majority Vote Learning Algorithms: Direct Minimization of PAC-Bayesian Bounds
Nov 09, 2024



The PAC-Bayesian framework has significantly advanced our understanding of statistical learning, particularly in majority voting methods. However, its application to multi-view learning remains underexplored. In this paper, we extend PAC-Bayesian theory to the multi-view setting, introducing novel PAC-Bayesian bounds based on R\'enyi divergence. These bounds improve upon traditional Kullback-Leibler divergence and offer more refined complexity measures. We further propose first and second-order oracle PAC-Bayesian bounds, along with an extension of the C-bound for multi-view learning. To ensure practical applicability, we develop efficient optimization algorithms with self-bounding properties.
iText2KG: Incremental Knowledge Graphs Construction Using Large Language Models
Sep 05, 2024Most available data is unstructured, making it challenging to access valuable information. Automatically building Knowledge Graphs (KGs) is crucial for structuring data and making it accessible, allowing users to search for information effectively. KGs also facilitate insights, inference, and reasoning. Traditional NLP methods, such as named entity recognition and relation extraction, are key in information retrieval but face limitations, including the use of predefined entity types and the need for supervised learning. Current research leverages large language models' capabilities, such as zero- or few-shot learning. However, unresolved and semantically duplicated entities and relations still pose challenges, leading to inconsistent graphs and requiring extensive post-processing. Additionally, most approaches are topic-dependent. In this paper, we propose iText2KG, a method for incremental, topic-independent KG construction without post-processing. This plug-and-play, zero-shot method is applicable across a wide range of KG construction scenarios and comprises four modules: Document Distiller, Incremental Entity Extractor, Incremental Relation Extractor, and Graph Integrator and Visualization. Our method demonstrates superior performance compared to baseline methods across three scenarios: converting scientific papers to graphs, websites to graphs, and CVs to graphs.
PAC-Bayesian Domain Adaptation Bounds for Multi-view learning
Jan 02, 2024This paper presents a series of new results for domain adaptation in the multi-view learning setting. The incorporation of multiple views in the domain adaptation was paid little attention in the previous studies. In this way, we propose an analysis of generalization bounds with Pac-Bayesian theory to consolidate the two paradigms, which are currently treated separately. Firstly, building on previous work by Germain et al., we adapt the distance between distribution proposed by Germain et al. for domain adaptation with the concept of multi-view learning. Thus, we introduce a novel distance that is tailored for the multi-view domain adaptation setting. Then, we give Pac-Bayesian bounds for estimating the introduced divergence. Finally, we compare the different new bounds with the previous studies.
Autoencoder-based Attribute Noise Handling Method for Medical Data
Jun 20, 2022



Medical datasets are particularly subject to attribute noise, that is, missing and erroneous values. Attribute noise is known to be largely detrimental to learning performances. To maximize future learning performances it is primordial to deal with attribute noise before any inference. We propose a simple autoencoder-based preprocessing method that can correct mixed-type tabular data corrupted by attribute noise. No other method currently exists to handle attribute noise in tabular data. We experimentally demonstrate that our method outperforms both state-of-the-art imputation methods and noise correction methods on several real-world medical datasets.
Deep Multi-View Learning for Tire Recommendation
Mar 23, 2022
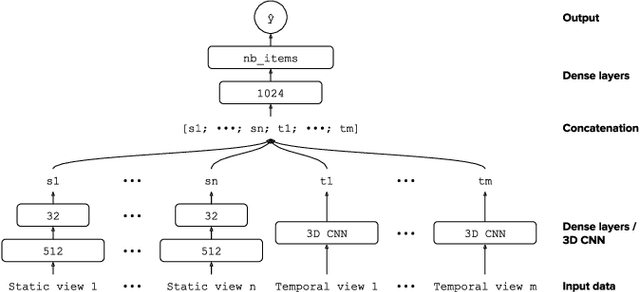


We are constantly using recommender systems, often without even noticing. They build a profile of our person in order to recommend the content we will most likely be interested in. The data representing the users, their interactions with the system or the products may come from different sources and be of a various nature. Our goal is to use a multi-view learning approach to improve our recommender system and improve its capacity to manage multi-view data. We propose a comparative study between several state-of-the-art multi-view models applied to our industrial data. Our study demonstrates the relevance of using multi-view learning within recommender systems.