 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoencoder-based Attribute Noise Handling Method for Medical Data
Jun 20, 2022



Medical datasets are particularly subject to attribute noise, that is, missing and erroneous values. Attribute noise is known to be largely detrimental to learning performances. To maximize future learning performances it is primordial to deal with attribute noise before any inference. We propose a simple autoencoder-based preprocessing method that can correct mixed-type tabular data corrupted by attribute noise. No other method currently exists to handle attribute noise in tabular data. We experimentally demonstrate that our method outperforms both state-of-the-art imputation methods and noise correction methods on several real-world medical datasets.
Deep Multi-View Learning for Tire Recommendation
Mar 23, 2022
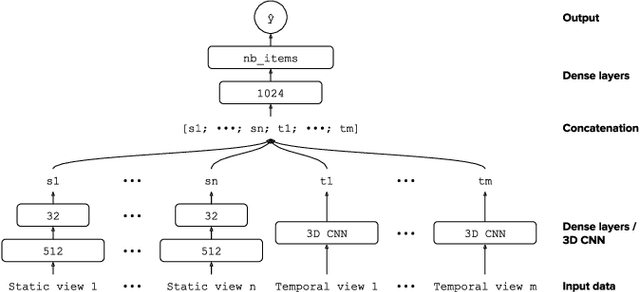


We are constantly using recommender systems, often without even noticing. They build a profile of our person in order to recommend the content we will most likely be interested in. The data representing the users, their interactions with the system or the products may come from different sources and be of a various nature. Our goal is to use a multi-view learning approach to improve our recommender system and improve its capacity to manage multi-view data. We propose a comparative study between several state-of-the-art multi-view models applied to our industrial data. Our study demonstrates the relevance of using multi-view learning within recommender systems.