 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATOM: AdapTive and OptiMized dynamic temporal knowledge graph construction using LLMs
Oct 26, 2025In today's rapidly expanding data landscape, knowledge extraction from unstructured text is vital for real-time analytics, temporal inference, and dynamic memory frameworks. However, traditional static knowledge graph (KG) construction often overlooks the dynamic and time-sensitive nature of real-world data, limiting adaptability to continuous changes. Moreover, recent zero- or few-shot approaches that avoid domain-specific fine-tuning or reliance on prebuilt ontologies often suffer from instability across multiple runs, as well as incomplete coverage of key facts. To address these challenges, we introduce ATOM (AdapTive and OptiMized), a few-shot and scalable approach that builds and continuously updates Temporal Knowledge Graphs (TKGs) from unstructured texts. ATOM splits input documents into minimal, self-contained "atomic" facts, improving extraction exhaustivity and stability. Then, it constructs atomic TKGs from these facts while employing a dual-time modeling that distinguishes when information is observed from when it is valid. The resulting atomic TKGs are subsequently merged in parallel. Empirical evaluations demonstrate that ATOM achieves ~18% higher exhaustivity, ~17% better stability, and over 90% latency reduction compared to baseline methods, demonstrating a strong scalability potential for dynamic TKG construction.
When Astronomy Meets AI: Manazel For Crescent Visibility Prediction in Morocco
Mar 27, 2025
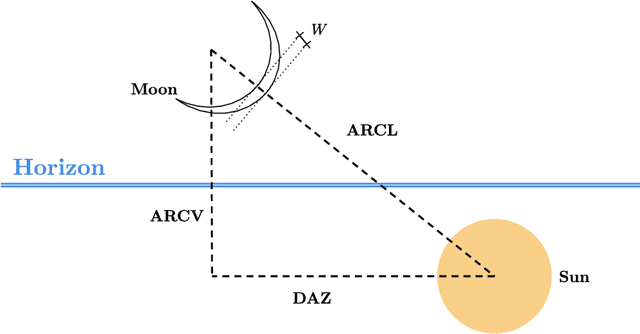


The accurate determination of the beginning of each Hijri month is essential for religious, cultural, and administrative purposes. Manazel (The code and datasets are available at https://github.com/lairgiyassir/manazel) addresses this challenge in Morocco by leveraging 13 years of crescent visibility data to refine the ODEH criterion, a widely used standard for lunar crescent visibility prediction. The study integrates two key features, the Arc of Vision (ARCV) and the total width of the crescent (W), to enhance the accuracy of lunar visibility assessments. A machine learning approach utilizing the Logistic Regression algorithm is employed to classify crescent visibility conditions, achieving a predictive accuracy of 98.83%. This data-driven methodology offers a robust and reliable framework for determining the start of the Hijri month, comparing different data classification tools, and improving the consistency of lunar calendar calculations in Morocco. The findings demonstrate the effectiveness of machine learning in astronomical applications and highlight the potential for further enhancements in the modeling of crescent visibility.
iText2KG: Incremental Knowledge Graphs Construction Using Large Language Models
Sep 05, 2024Most available data is unstructured, making it challenging to access valuable information. Automatically building Knowledge Graphs (KGs) is crucial for structuring data and making it accessible, allowing users to search for information effectively. KGs also facilitate insights, inference, and reasoning. Traditional NLP methods, such as named entity recognition and relation extraction, are key in information retrieval but face limitations, including the use of predefined entity types and the need for supervised learning. Current research leverages large language models' capabilities, such as zero- or few-shot learning. However, unresolved and semantically duplicated entities and relations still pose challenges, leading to inconsistent graphs and requiring extensive post-processing. Additionally, most approaches are topic-dependent. In this paper, we propose iText2KG, a method for incremental, topic-independent KG construction without post-processing. This plug-and-play, zero-shot method is applicable across a wide range of KG construction scenarios and comprises four modules: Document Distiller, Incremental Entity Extractor, Incremental Relation Extractor, and Graph Integrator and Visualization. Our method demonstrates superior performance compared to baseline methods across three scenarios: converting scientific papers to graphs, websites to graphs, and CVs to graphs.