 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automated Question-Answering Framework Based on Evolution Algorithm
Jan 26, 2022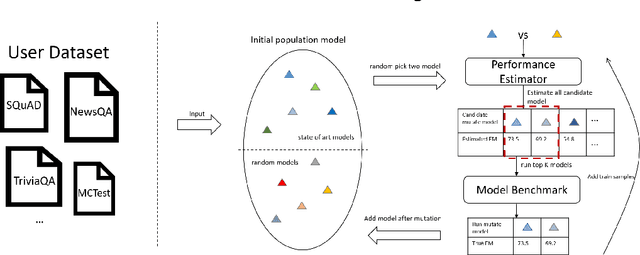

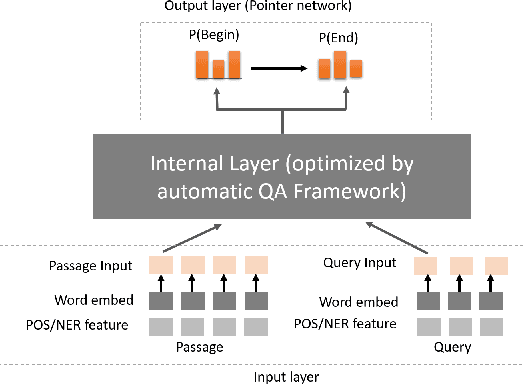
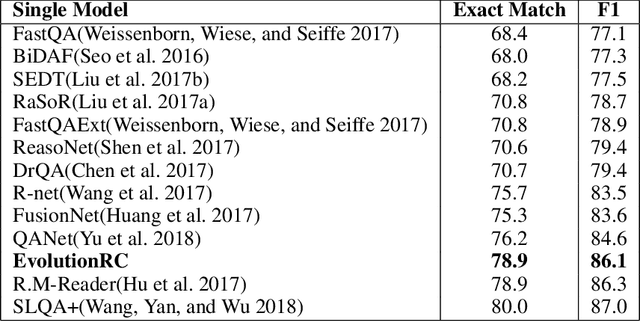
Building a deep learning model for a Question-Answering (QA) task requires a lot of human effort, it may need several months to carefully tune various model architectures and find a best one. It's even harder to find different excellent models for multiple datasets. Recent works show that the best model structure is related to the dataset used, and one single model cannot adapt to all tasks. In this paper, we propose an automated Question-Answering framework, which could automatically adjust network architecture for multiple datasets. Our framework is based on an innovative evolution algorithm, which is stable and suitable for multiple dataset scenario. The evolution algorithm for search combine prior knowledge into initial population and use a performance estimator to avoid inefficient mutation by predicting the performance of candidate model architecture. The prior knowledge used in initial population could improve the final result of the evolution algorithm. The performance estimator could quickly filter out models with bad performance in population as the number of trials increases, to speed up the convergence. Our framework achieves 78.9 EM and 86.1 F1 on SQuAD 1.1, 69.9 EM and 72.5 F1 on SQuAD 2.0. On NewsQA dataset, the found model achieves 47.0 EM and 62.9 F1.
Dynamic Hybrid Relation Network for Cross-Domain Context-Dependent Semantic Parsing
Jan 05, 2021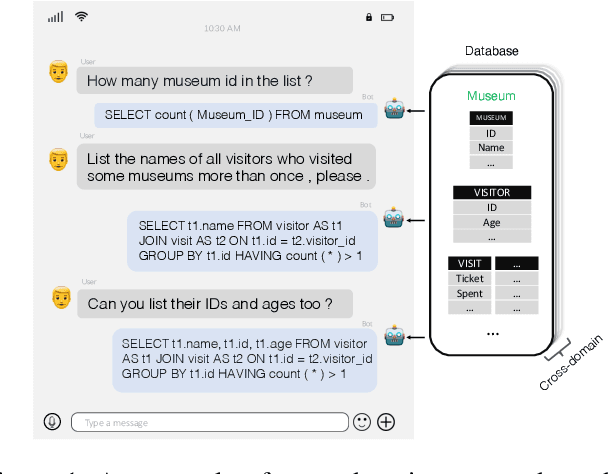

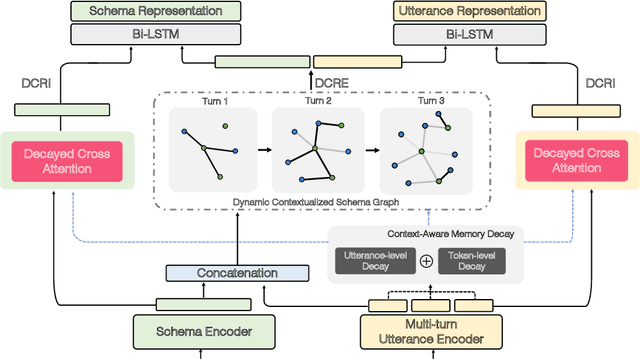
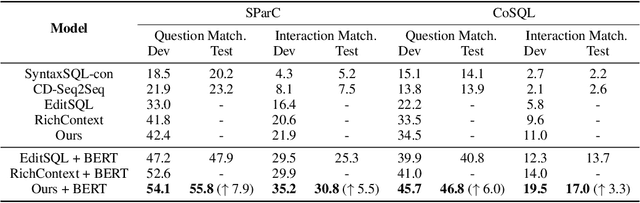
Semantic parsing has long been a fundamental problem in natural language processing. Recently, cross-domain context-dependent semantic parsing has become a new focus of research. Central to the problem is the challenge of leveraging contextual information of both natural language utterance and database schemas in the interaction history. In this paper, we present a dynamic graph framework that is capable of effectively modelling contextual utterances, tokens, database schemas, and their complicated interaction as the conversation proceeds. The framework employs a dynamic memory decay mechanism that incorporates inductive bias to integrate enriched contextual relation representation, which is further enhanced with a powerful reranking model. At the time of writing, we demonstrate that the proposed framework outperforms all existing models by large margins, achieving new state-of-the-art performance on two large-scale benchmarks, the SParC and CoSQL datasets. Specifically, the model attains a 55.8% question-match and 30.8% interaction-match accuracy on SParC, and a 46.8% question-match and 17.0% interaction-match accuracy on CoSQL.