 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Rectify Step by Step: Improving Aspect-based Sentiment Analysis with Diffusion Models
Feb 23, 2024Aspect-Based Sentiment Analysis (ABSA) stands as a crucial task in predicting the sentiment polarity associated with identified aspects within text. However, a notable challenge in ABSA lies in precisely determining the aspects' boundaries (start and end indices), especially for long ones, due to users' colloquial expressions. We propose DiffusionABSA, a novel diffusion model tailored for ABSA, which extracts the aspects progressively step by step. Particularly, DiffusionABSA gradually adds noise to the aspect terms in the training process, subsequently learning a denoising process that progressively restores these terms in a reverse manner. To estimate the boundaries, we design a denoising neural network enhanced by a syntax-aware temporal attention mechanism to chronologically capture the interplay between aspects and surrounding text. Empirical evaluations conducted on eight benchmark datasets underscore the compelling advantages offered by DiffusionABSA when compared against robust baseline models. Our code is publicly available at https://github.com/Qlb6x/DiffusionABSA.
A Knowledge-Enhanced Adversarial Model for Cross-lingual Structured Sentiment Analysis
May 31, 2022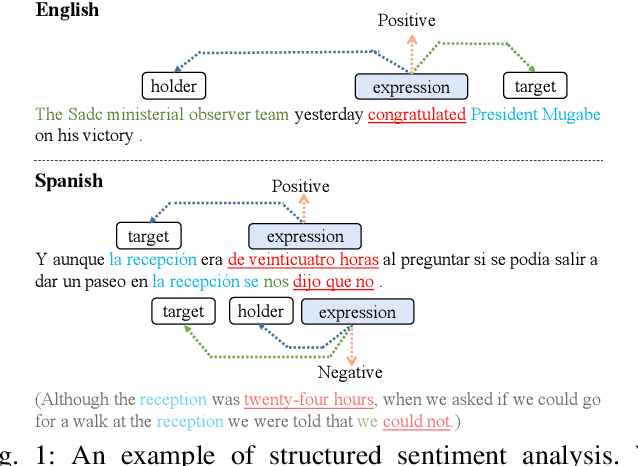
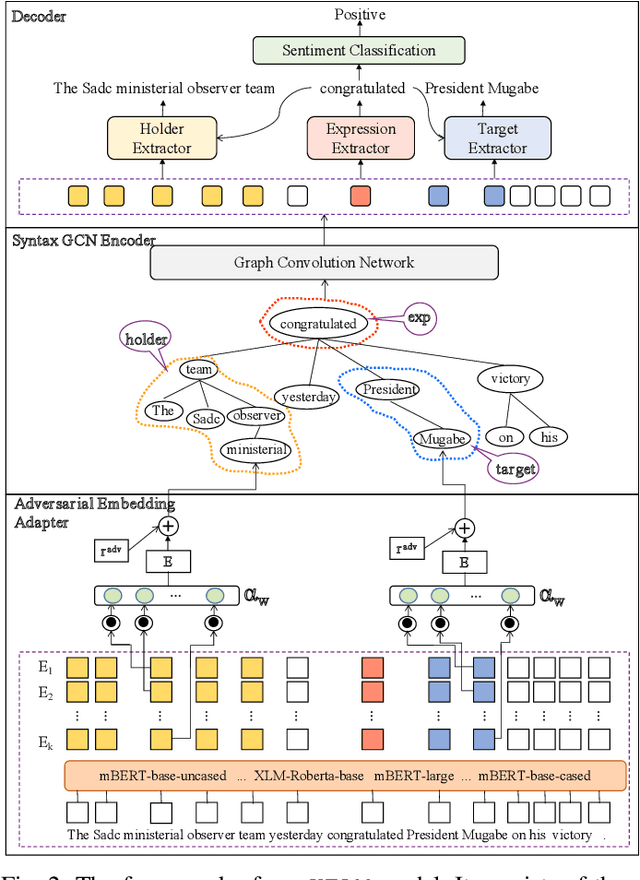
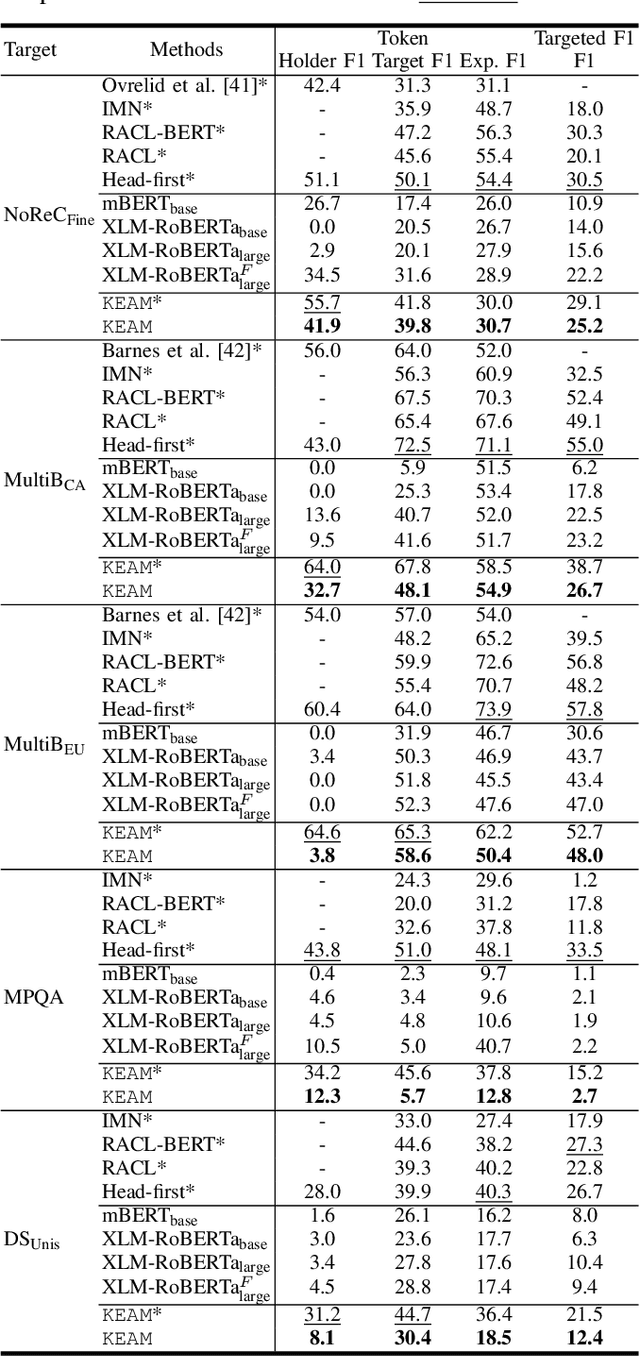
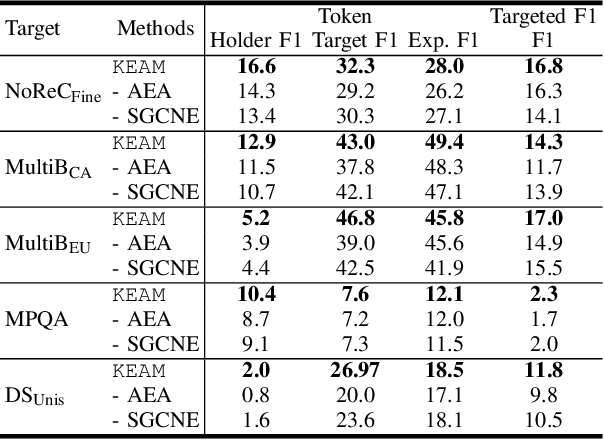
Structured sentiment analysis, which aims to extract the complex semantic structures such as holders, expressions, targets, and polarities, has obtained widespread attention from both industry and academia. Unfortunately, the existing structured sentiment analysis datasets refer to a few languages and are relatively small, limiting neural network models' performance. In this paper, we focus on the cross-lingual structured sentiment analysis task, which aims to transfer the knowledge from the source language to the target one. Notably, we propose a Knowledge-Enhanced Adversarial Model (\texttt{KEAM}) with both implicit distributed and explicit structural knowledge to enhance the cross-lingual transfer. First, we design an adversarial embedding adapter for learning an informative and robust representation by capturing implicit semantic information from diverse multi-lingual embeddings adaptively. Then, we propose a syntax GCN encoder to transfer the explicit semantic information (e.g., universal dependency tree) among multiple languages. We conduct experiments on five datasets and compare \texttt{KEAM} with both the supervised and unsupervised methods. The extensive experimental results show that our \texttt{KEAM} model outperforms all the unsupervised baselines in various metrics.