 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing News Summarization with ELearnFit through Efficient In-Context Learning and Efficient Fine-Tuning
May 04, 2024

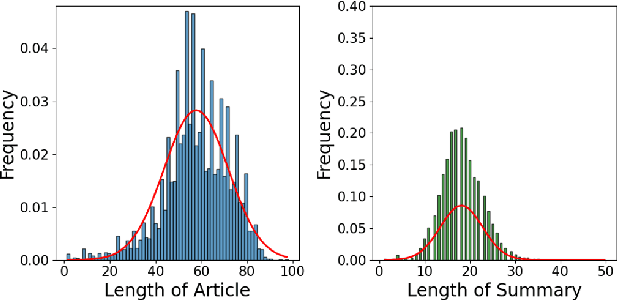

With the deluge of information delivered by the daily news cycle, there is a growing need to effectively and efficiently summarize news feeds for quick consumption. We leverage large language models (LLMs), with their advanced learning and generative abilities as compared to conventional language models, to generate concise and coherent summaries for news articles from the XSum dataset. Our paper focuses on two key aspects of LLMs: Efficient in-context Learning (ELearn) and Parameter Efficient Fine-tuning (EFit). Under ELearn, we find that increasing the number of shots in prompts and utilizing simple templates generally improve the quality of summaries. We also find that utilizing relevant examples in few-shot learning for ELearn does not improve model performance. In addition, we studied EFit using different methods and demonstrate that fine-tuning the first layer of LLMs produces better outcomes as compared to fine-tuning other layers or utilizing LoRA. We also find that leveraging more relevant training samples using selective layers does not result in better performance. By combining ELearn and EFit, we create a new model (ELearnFit) that leverages the benefits of both few-shot learning and fine-tuning and produces superior performance to either model alone. We also use ELearnFit to highlight the trade-offs between prompting and fine-tuning, especially for situations where only a limited number of annotated samples are available. Ultimately, our research provides practical techniques to optimize news summarization during the prompting and fine-tuning stages and enhances the synthesis of news articles.
Upscaling Global Hourly GPP with Temporal Fusion Transformer (TFT)
Jun 23, 2023Reliable estimates of Gross Primary Productivity (GPP), crucial for evaluating climate change initiatives, are currently only available from sparsely distributed eddy covariance tower sites. This limitation hampers access to reliable GPP quantification at regional to global scales. Prior machine learning studies on upscaling \textit{in situ} GPP to global wall-to-wall maps at sub-daily time steps faced limitations such as lack of input features at higher temporal resolutions and significant missing values. This research explored a novel upscaling solution using Temporal Fusion Transformer (TFT) without relying on past GPP time series. Model development was supplemented by Random Forest Regressor (RFR) and XGBoost, followed by the hybrid model of TFT and tree algorithms. The best preforming model yielded to model performance of 0.704 NSE and 3.54 RMSE. Another contribution of the study was the breakdown analysis of encoder feature importance based on time and flux tower sites. Such analysis enhanced the interpretability of the multi-head attention layer as well as the visual understanding of temporal dynamics of influential features.
Snowpack Estimation in Key Mountainous Water Basins from Openly-Available, Multimodal Data Sources
Aug 08, 2022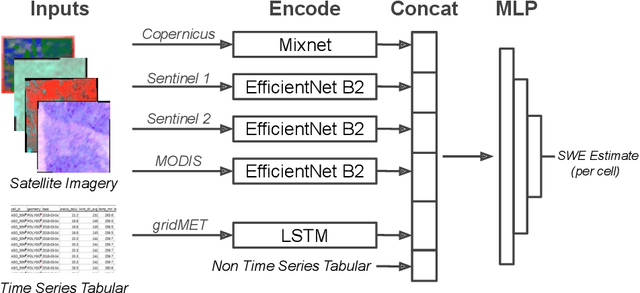
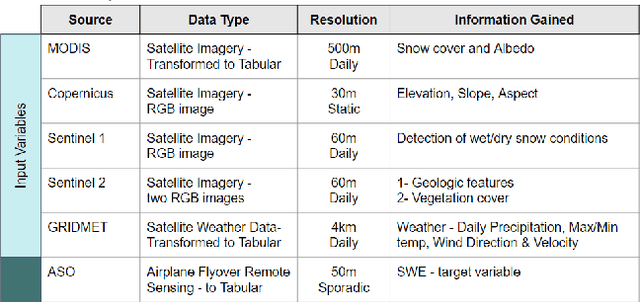
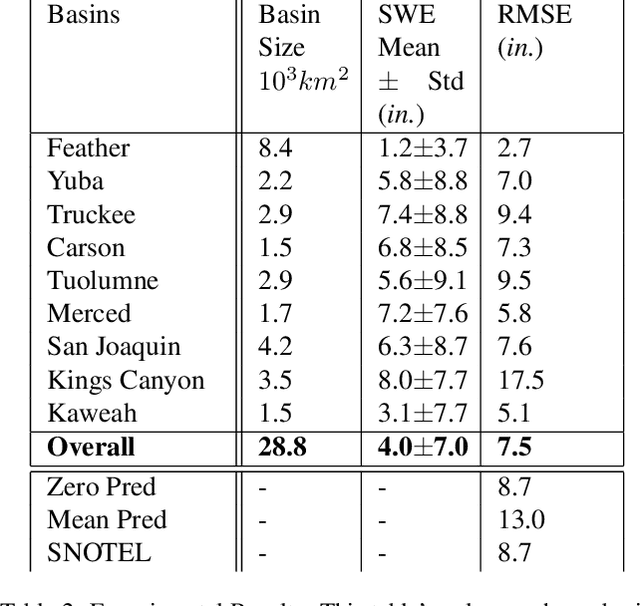
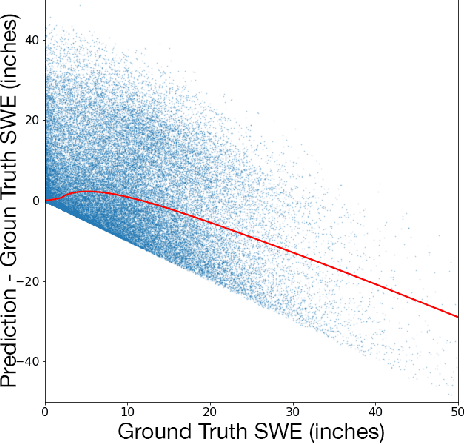
Accurately estimating the snowpack in key mountainous basins is critical for water resource managers to make decisions that impact local and global economies, wildlife, and public policy. Currently, this estimation requires multiple LiDAR-equipped plane flights or in situ measurements, both of which are expensive, sparse, and biased towards accessible regions. In this paper, we demonstrate that fusing spatial and temporal information from multiple, openly-available satellite and weather data sources enables estimation of snowpack in key mountainous regions. Our multisource model outperforms single-source estimation by 5.0 inches RMSE, as well as outperforms sparse in situ measurements by 1.2 inches RMSE.
High-resolution global irrigation prediction with Sentinel-2 30m data
Dec 09, 2020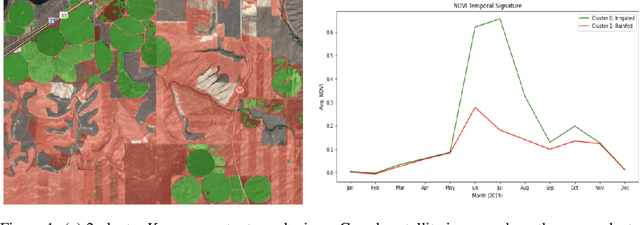
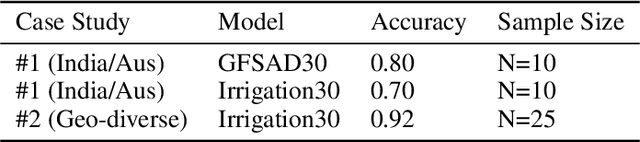
An accurate and precise understanding of global irrigation usage is crucial for a variety of climate science efforts. Irrigation is highly energy-intensive, and as population growth continues at its current pace, increases in crop need and water usage will have an impact on climate change. Precise irrigation data can help with monitoring water usage and optimizing agricultural yield, particularly in developing countries. Irrigation data, in tandem with precipitation data, can be used to predict water budgets as well as climate and weather modeling. With our research, we produce an irrigation prediction model that combines unsupervised clustering of Normalized Difference Vegetation Index (NDVI) temporal signatures with a precipitation heuristic to label the months that irrigation peaks for each cropland cluster in a given year. We have developed a novel irrigation model and Python package ("Irrigation30") to generate 30m resolution irrigation predictions of cropland worldwide. With a small crowdsourced test set of cropland coordinates and irrigation labels, using a fraction of the resources used by the state-of-the-art NASA-funded GFSAD30 project with irrigation data limited to India and Australia, our model was able to achieve consistency scores in excess of 97\% and an accuracy of 92\% in a small geo-diverse randomly sampled test set.