 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivately Estimating a Gaussian: Efficient, Robust and Optimal
Dec 15, 2022

In this work, we give efficient algorithms for privately estimating a Gaussian distribution in both pure and approximate differential privacy (DP) models with optimal dependence on the dimension in the sample complexity. In the pure DP setting, we give an efficient algorithm that estimates an unknown $d$-dimensional Gaussian distribution up to an arbitrary tiny total variation error using $\widetilde{O}(d^2 \log \kappa)$ samples while tolerating a constant fraction of adversarial outliers. Here, $\kappa$ is the condition number of the target covariance matrix. The sample bound matches best non-private estimators in the dependence on the dimension (up to a polylogarithmic factor). We prove a new lower bound on differentially private covariance estimation to show that the dependence on the condition number $\kappa$ in the above sample bound is also tight. Prior to our work, only identifiability results (yielding inefficient super-polynomial time algorithms) were known for the problem. In the approximate DP setting, we give an efficient algorithm to estimate an unknown Gaussian distribution up to an arbitrarily tiny total variation error using $\widetilde{O}(d^2)$ samples while tolerating a constant fraction of adversarial outliers. Prior to our work, all efficient approximate DP algorithms incurred a super-quadratic sample cost or were not outlier-robust. For the special case of mean estimation, our algorithm achieves the optimal sample complexity of $\widetilde O(d)$, improving on a $\widetilde O(d^{1.5})$ bound from prior work. Our pure DP algorithm relies on a recursive private preconditioning subroutine that utilizes the recent work on private mean estimation [Hopkins et al., 2022]. Our approximate DP algorithms are based on a substantial upgrade of the method of stabilizing convex relaxations introduced in [Kothari et al., 2022].
Near-optimal fitting of ellipsoids to random points
Aug 29, 2022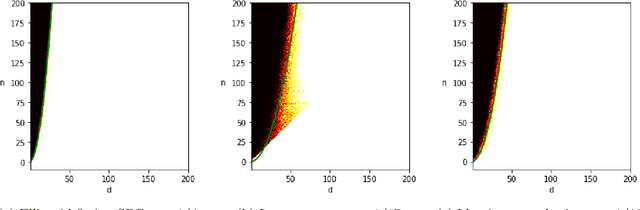
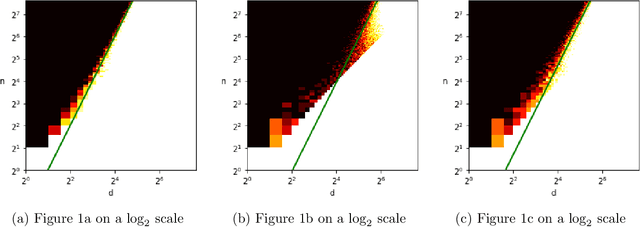
Given independent standard Gaussian points $v_1, \ldots, v_n$ in dimension $d$, for what values of $(n, d)$ does there exist with high probability an origin-symmetric ellipsoid that simultaneously passes through all of the points? This basic problem of fitting an ellipsoid to random points has connections to low-rank matrix decompositions, independent component analysis, and principal component analysis. Based on strong numerical evidence, Saunderson, Parrilo, and Willsky [Proc. of Conference on Decision and Control, pp. 6031-6036, 2013] conjecture that the ellipsoid fitting problem transitions from feasible to infeasible as the number of points $n$ increases, with a sharp threshold at $n \sim d^2/4$. We resolve this conjecture up to logarithmic factors by constructing a fitting ellipsoid for some $n = \Omega( \, d^2/\log^5(d) \,)$, improving prior work of Ghosh et al. [Proc. of Symposium on Foundations of Computer Science, pp. 954-965, 2020] that requires $n = o(d^{3/2})$. Our proof demonstrates feasibility of the least squares construction of Saunderson et al. using a careful analysis of the eigenvectors and eigenvalues of a certain non-standard random matrix.
Optimal Regularization Can Mitigate Double Descent
Mar 04, 2020
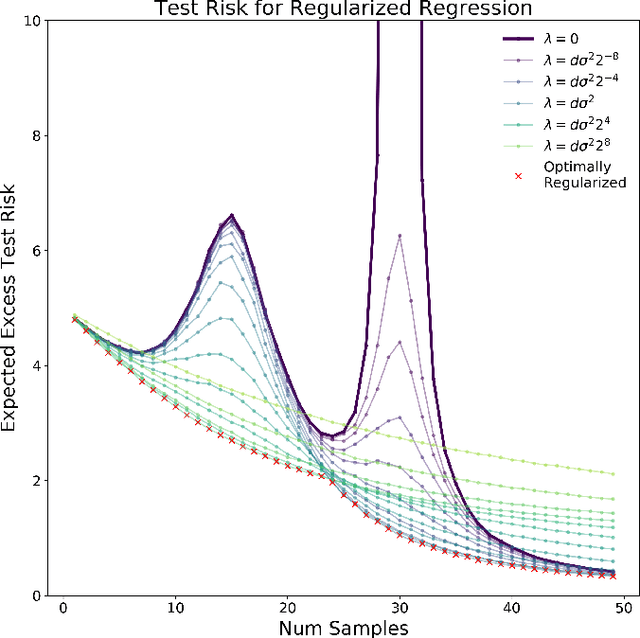
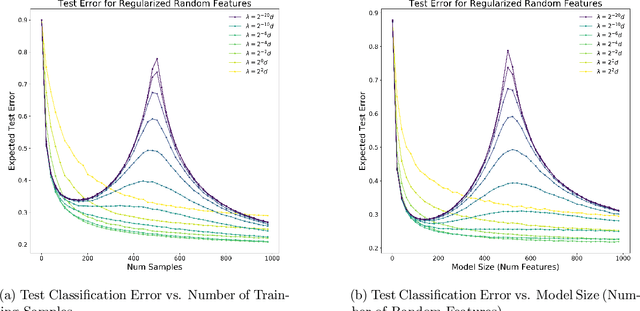

Recent empirical and theoretical studies have shown that many learning algorithms -- from linear regression to neural networks -- can have test performance that is non-monotonic in quantities such the sample size and model size. This striking phenomenon, often referred to as "double descent", has raised questions of if we need to re-think our current understanding of generalization. In this work, we study whether the double-descent phenomenon can be avoided by using optimal regularization. Theoretically, we prove that for certain linear regression models with isotropic data distribution, optimally-tuned $\ell_2$ regularization achieves monotonic test performance as we grow either the sample size or the model size. We also demonstrate empirically that optimally-tuned $\ell_2$ regularization can mitigate double descent for more general models, including neural networks. Our results suggest that it may also be informative to study the test risk scalings of various algorithms in the context of appropriately tuned regularization.
A Fast Spectral Algorithm for Mean Estimation with Sub-Gaussian Rates
Aug 13, 2019We study the algorithmic problem of estimating the mean of heavy-tailed random vector in $\mathbb{R}^d$, given $n$ i.i.d. samples. The goal is to design an efficient estimator that attains the optimal sub-gaussian error bound, only assuming that the random vector has bounded mean and covariance. Polynomial-time solutions to this problem are known but have high runtime due to their use of semi-definite programming (SDP). Conceptually, it remains open whether convex relaxation is truly necessary for this problem. In this work, we show that it is possible to go beyond SDP and achieve better computational efficiency. In particular, we provide a spectral algorithm that achieves the optimal statistical performance and runs in time $\widetilde O\left(n^2 d \right)$, improving upon the previous fastest runtime $\widetilde O\left(n^{3.5}+ n^2d\right)$ by Cherapanamjeri el al. (COLT '19) and matching the concurrent work by Depersin and Lecu\'e. Our algorithm is spectral in that it only requires (approximate) eigenvector computations, which can be implemented very efficiently by, for example, power iteration or the Lanczos method. At the core of our algorithm is a novel connection between the furthest hyperplane problem introduced by Karnin et al. (COLT '12) and a structural lemma on heavy-tailed distributions by Lugosi and Mendelson (Ann. Stat. '19). This allows us to iteratively reduce the estimation error at a geometric rate using only the information derived from the top singular vector of the data matrix, leading to a significantly faster running time.