 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness Implies Generalization via Data-Dependent Generalization Bounds
Jun 27, 2022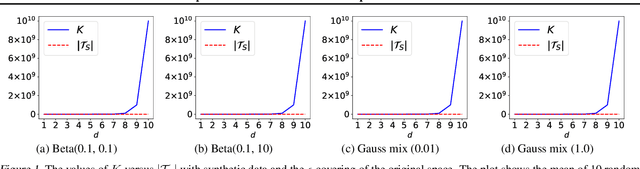

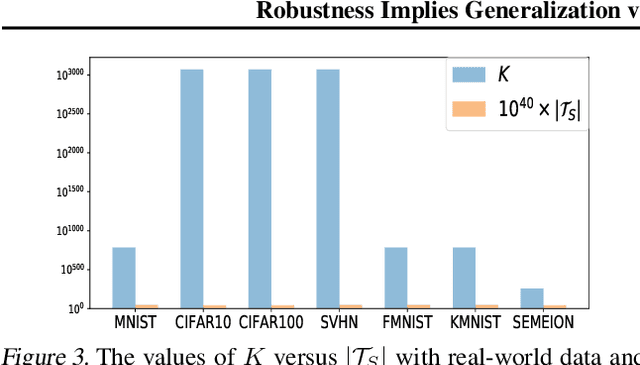
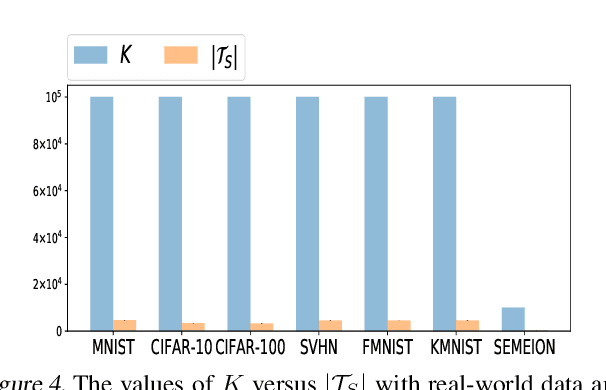
This paper proves that robustness implies generalization via data-dependent generalization bounds. As a result, robustness and generalization are shown to be connected closely in a data-dependent manner. Our bounds improve previous bounds in two directions, to solve an open problem that has seen little development since 2010. The first is to reduce the dependence on the covering number. The second is to remove the dependence on the hypothesis space. We present several examples, including ones for lasso and deep learning, in which our bounds are provably preferable. The experiments on real-world data and theoretical models demonstrate near-exponential improvements in various situations. To achieve these improvements, we do not require additional assumptions on the unknown distribution; instead, we only incorporate an observable and computable property of the training samples. A key technical innovation is an improved concentration bound for multinomial random variables that is of independent interest beyond robustness and generalization.
A Fast Spectral Algorithm for Mean Estimation with Sub-Gaussian Rates
Aug 13, 2019We study the algorithmic problem of estimating the mean of heavy-tailed random vector in $\mathbb{R}^d$, given $n$ i.i.d. samples. The goal is to design an efficient estimator that attains the optimal sub-gaussian error bound, only assuming that the random vector has bounded mean and covariance. Polynomial-time solutions to this problem are known but have high runtime due to their use of semi-definite programming (SDP). Conceptually, it remains open whether convex relaxation is truly necessary for this problem. In this work, we show that it is possible to go beyond SDP and achieve better computational efficiency. In particular, we provide a spectral algorithm that achieves the optimal statistical performance and runs in time $\widetilde O\left(n^2 d \right)$, improving upon the previous fastest runtime $\widetilde O\left(n^{3.5}+ n^2d\right)$ by Cherapanamjeri el al. (COLT '19) and matching the concurrent work by Depersin and Lecu\'e. Our algorithm is spectral in that it only requires (approximate) eigenvector computations, which can be implemented very efficiently by, for example, power iteration or the Lanczos method. At the core of our algorithm is a novel connection between the furthest hyperplane problem introduced by Karnin et al. (COLT '12) and a structural lemma on heavy-tailed distributions by Lugosi and Mendelson (Ann. Stat. '19). This allows us to iteratively reduce the estimation error at a geometric rate using only the information derived from the top singular vector of the data matrix, leading to a significantly faster running time.