 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Clustering Techniques for Speech Signal Enhancement: A Review and Metanalysis of Fuzzy C-Means, K-Means, and Kernel Fuzzy C-Means Methods
Sep 28, 2024



Speech signal processing is a cornerstone of modern communication technologies, tasked with improving the clarity and comprehensibility of audio data in noisy environments. The primary challenge in this field is the effective separation and recognition of speech from background noise, crucial for applications ranging from voice-activated assistants to automated transcription services. The quality of speech recognition directly impacts user experience and accessibility in technology-driven communication. This review paper explores advanced clustering techniques, particularly focusing on the Kernel Fuzzy C-Means (KFCM) method, to address these challenges. Our findings indicate that KFCM, compared to traditional methods like K-Means (KM) and Fuzzy C-Means (FCM), provides superior performance in handling non-linear and non-stationary noise conditions in speech signals. The most notable outcome of this review is the adaptability of KFCM to various noisy environments, making it a robust choice for speech enhancement applications. Additionally, the paper identifies gaps in current methodologies, such as the need for more dynamic clustering algorithms that can adapt in real time to changing noise conditions without compromising speech recognition quality. Key contributions include a detailed comparative analysis of current clustering algorithms and suggestions for further integrating hybrid models that combine KFCM with neural networks to enhance speech recognition accuracy. Through this review, we advocate for a shift towards more sophisticated, adaptive clustering techniques that can significantly improve speech enhancement and pave the way for more resilient speech processing systems.
An Improved Simulation Model for Pedestrian Crowd Evacuation
Dec 04, 2020
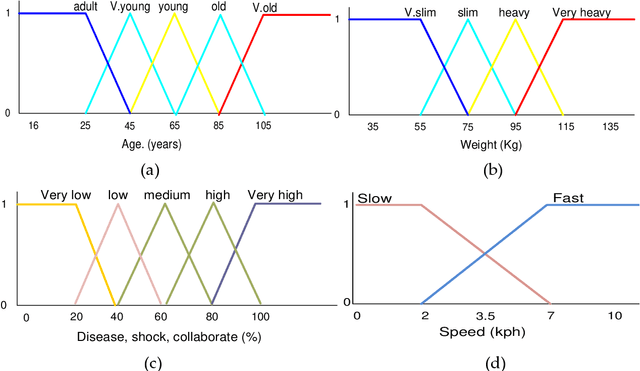

This paper works on one of the most recent pedestrian crowd evacuation models, i.e., "a simulation model for pedestrian crowd evacuation based on various AI techniques", developed in late 2019. This study adds a new feature to the developed model by proposing a new method and integrating it with the model. This method enables the developed model to find a more appropriate evacuation area design, among others regarding safety due to selecting the best exit door location among many suggested locations. This method is completely dependent on the selected model's output, i.e., the evacuation time for each individual within the evacuation process. The new method finds an average of the evacuees' evacuation times of each exit door location; then, based on the average evacuation time, it decides which exit door location would be the best exit door to be used for evacuation by the evacuees. To validate the method, various designs for the evacuation area with various written scenarios were used. The results showed that the model with this new method could predict a proper exit door location among many suggested locations. Lastly, from the results of this research using the integration of this newly proposed method, a new capability for the selected model in terms of safety allowed the right decision in selecting the finest design for the evacuation area among other designs.
Measuring Player's Behaviour Change over Time in Public Goods Game
Sep 09, 2016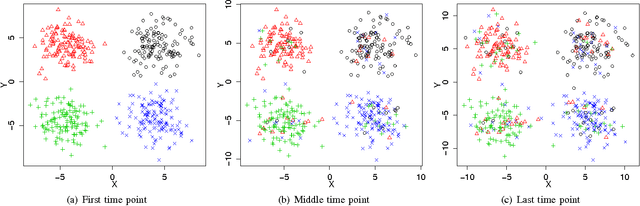
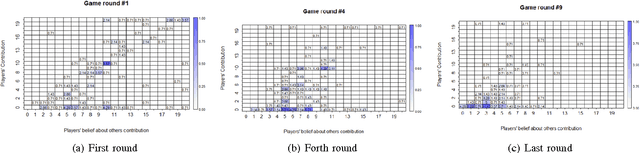
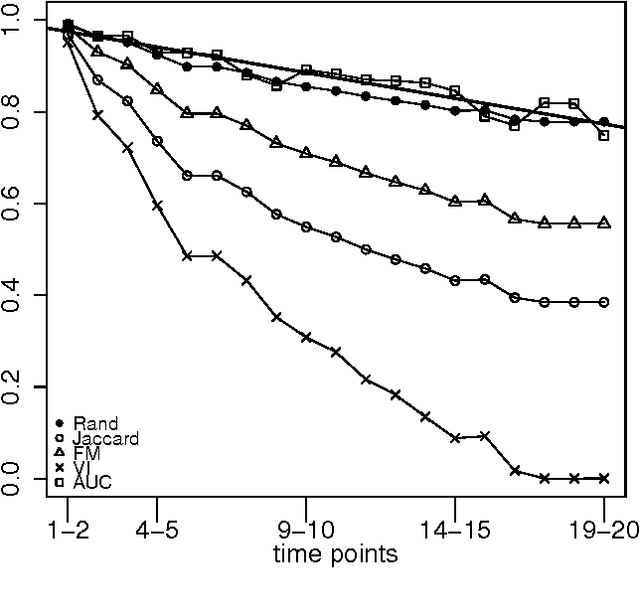
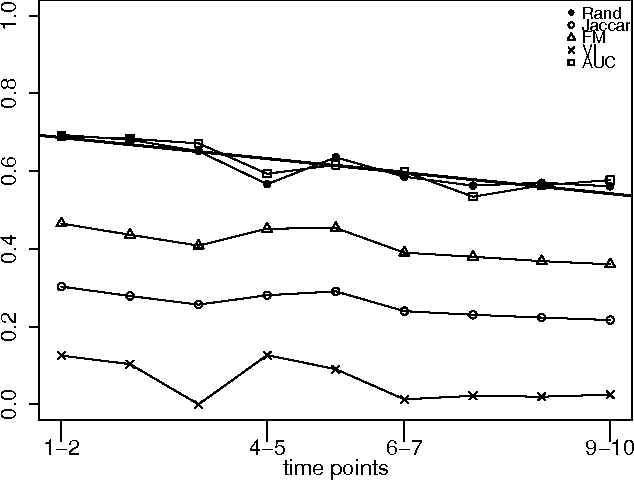
An important issue in public goods game is whether player's behaviour changes over time, and if so, how significant it is. In this game players can be classified into different groups according to the level of their participation in the public good. This problem can be considered as a concept drift problem by asking the amount of change that happens to the clusters of players over a sequence of game rounds. In this study we present a method for measuring changes in clusters with the same items over discrete time points using external clustering validation indices and area under the curve. External clustering indices were originally used to measure the difference between suggested clusters in terms of clustering algorithms and ground truth labels for items provided by experts. Instead of different cluster label comparison, we use these indices to compare between clusters of any two consecutive time points or between the first time point and the remaining time points to measure the difference between clusters through time points. In theory, any external clustering indices can be used to measure changes for any traditional (non-temporal) clustering algorithm, due to the fact that any time point alone is not carrying any temporal information. For the public goods game, our results indicate that the players are changing over time but the change is smooth and relatively constant between any two time points.
Optimising Rule-Based Classification in Temporal Data
Jul 20, 2016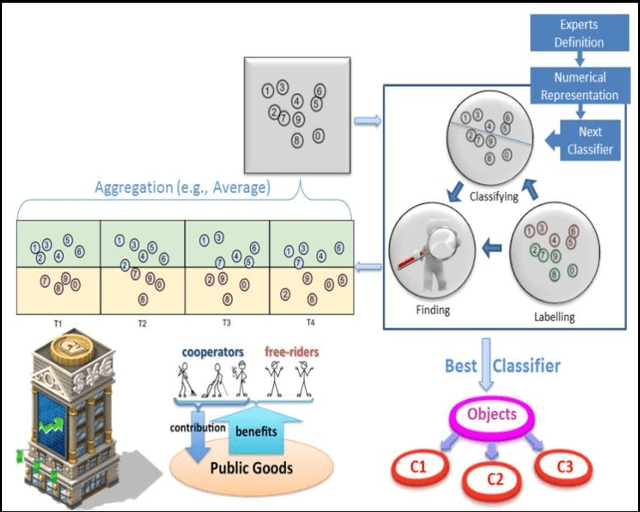
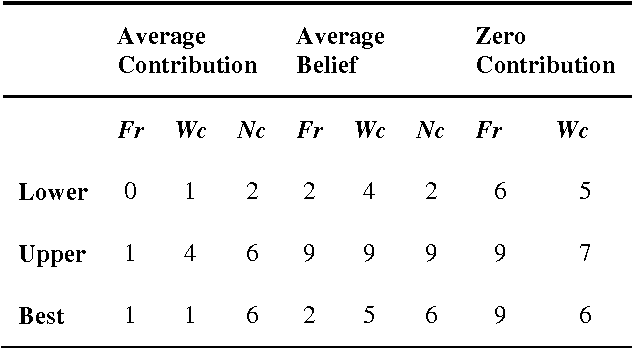
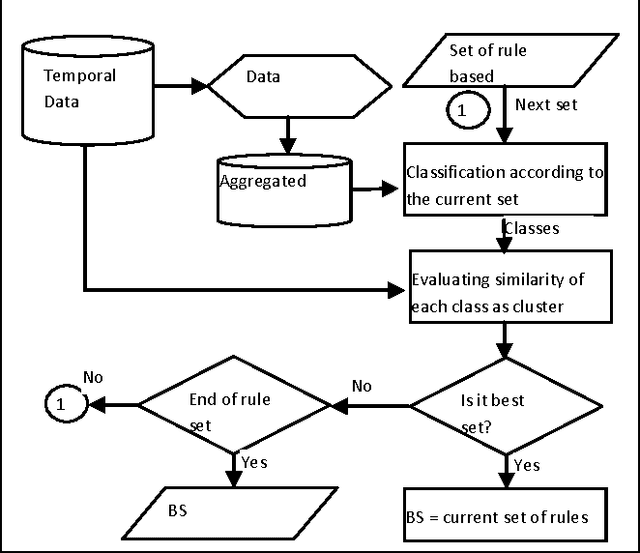
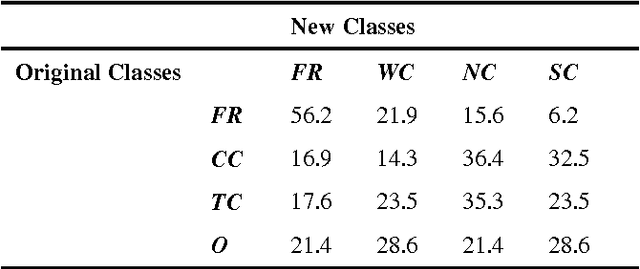
This study optimises manually derived rule-based expert system classification of objects according to changes in their properties over time. One of the key challenges that this study tries to address is how to classify objects that exhibit changes in their behaviour over time, for example how to classify companies' share price stability over a period of time or how to classify students' preferences for subjects while they are progressing through school. A specific case the paper considers is the strategy of players in public goods games (as common in economics) across multiple consecutive games. Initial classification starts from expert definitions specifying class allocation for players based on aggregated attributes of the temporal data. Based on these initial classifications, the optimisation process tries to find an improved classifier which produces the best possible compact classes of objects (players) for every time point in the temporal data. The compactness of the classes is measured by a cost function based on internal cluster indices like the Dunn Index, distance measures like Euclidean distance or statistically derived measures like standard deviation. The paper discusses the approach in the context of incorporating changing player strategies in the aforementioned public good games, where common classification approaches so far do not consider such changes in behaviour resulting from learning or in-game experience. By using the proposed process for classifying temporal data and the actual players' contribution during the games, we aim to produce a more refined classification which in turn may inform the interpretation of public goods game data.