 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Free versus Model-Based Reinforcement Learning for Fixed-Wing UAV Attitude Control Under Varying Wind Conditions
Sep 26, 2024



This paper evaluates and compares the performance of model-free and model-based reinforcement learning for the attitude control of fixed-wing unmanned aerial vehicles using PID as a reference point. The comparison focuses on their ability to handle varying flight dynamics and wind disturbances in a simulated environment. Our results show that the Temporal Difference Model Predictive Control agent outperforms both the PID controller and other model-free reinforcement learning methods in terms of tracking accuracy and robustness over different reference difficulties, particularly in nonlinear flight regimes. Furthermore, we introduce actuation fluctuation as a key metric to assess energy efficiency and actuator wear, and we test two different approaches from the literature: action variation penalty and conditioning for action policy smoothness. We also evaluate all control methods when subject to stochastic turbulence and gusts separately, so as to measure their effects on tracking performance, observe their limitations and outline their implications on the Markov decision process formalism.
* Published at ICINCO 2024
CLIC: Curriculum Learning and Imitation for feature Control in non-rewarding environments
Jan 31, 2019

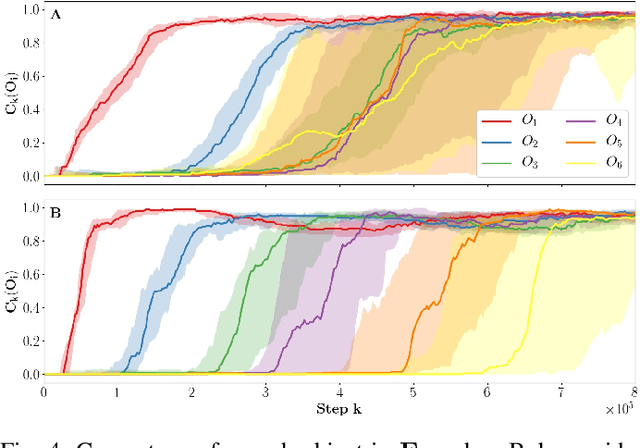
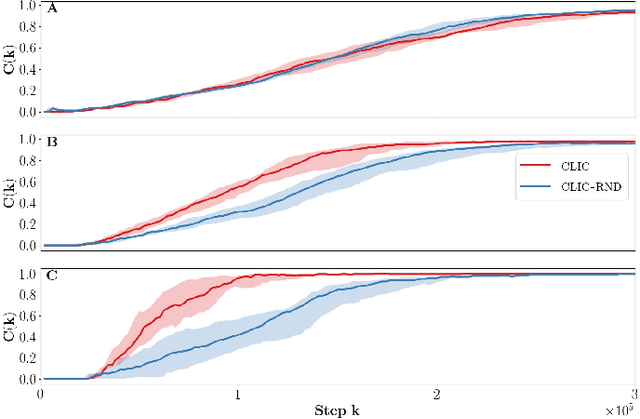
In this paper, we propose an unsupervised reinforcement learning agent called CLIC for Curriculum Learning and Imitation for Control. This agent learns to control features in its environment without external rewards, and observes the actions of a third party agent, Bob, who does not necessarily provide explicit guidance. CLIC selects which feature to train on and what to imitate from Bob's behavior by maximizing its learning progress. We show that CLIC can effectively identify helpful behaviors in Bob's actions, and imitate them to control the environment faster. CLIC can also follow Bob when he acts as a mentor and provides ordered demonstrations. Finally, when Bob controls features than the agent cannot, or in presence of a hierarchy between aspects of the environment, we show that CLIC ignores non-reproducible and already mastered behaviors, resulting in a greater benefit from imitation.
CURIOUS: Intrinsically Motivated Modular Multi-Goal Reinforcement Learning
Oct 24, 2018

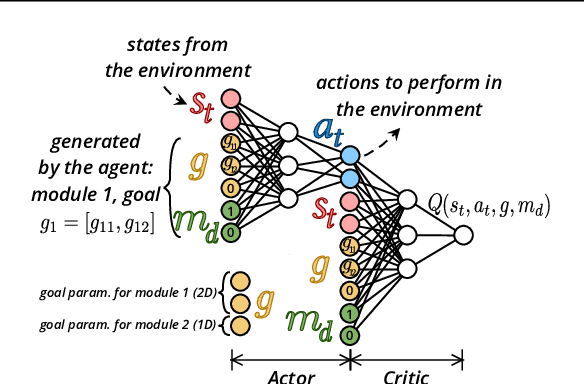

In open-ended and changing environments, agents face a wide range of potential tasks that may or may not come with associated reward functions. Such autonomous learning agents must be able to generate their own tasks through a process of intrinsically motivated exploration, some of which might prove easy, others impossible. For this reason, they should be able to actively select which task to practice at any given moment, to maximize their overall mastery on the set of learnable tasks. This paper proposes CURIOUS, an extension of Universal Value Function Approximators that enables intrinsically motivated agents to learn to achieve both multiple tasks and multiple goals within a unique policy, leveraging hindsight learning. Agents focus on achievable tasks first, using an automated curriculum learning mechanism that biases their attention towards tasks maximizing the absolute learning progress. This mechanism provides robustness to catastrophic forgetting (by refocusing on tasks where performance decreases) and distracting tasks (by avoiding tasks with no absolute learning progress). Furthermore, we show that having two levels of parameterization (tasks and goals within tasks) enables more efficient learning of skills in an environment with a modular physical structure (e.g. multiple objects) as compared to flat, goal-parameterized RL with hindsight experience replay.
Accuracy-based Curriculum Learning in Deep Reinforcement Learning
Sep 21, 2018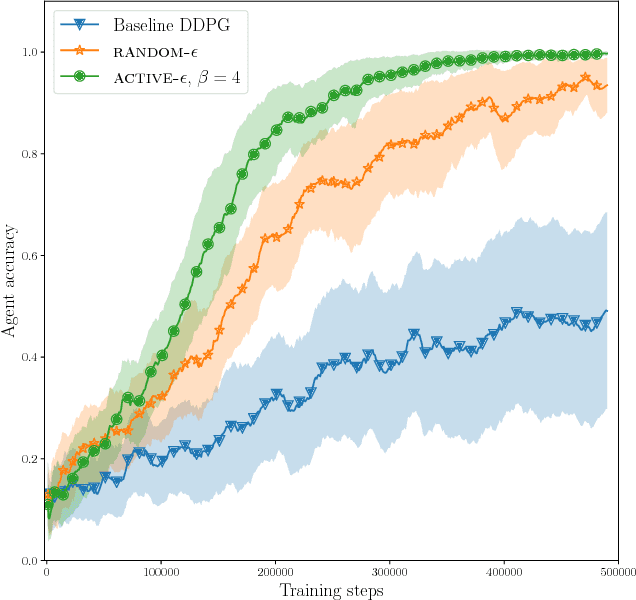

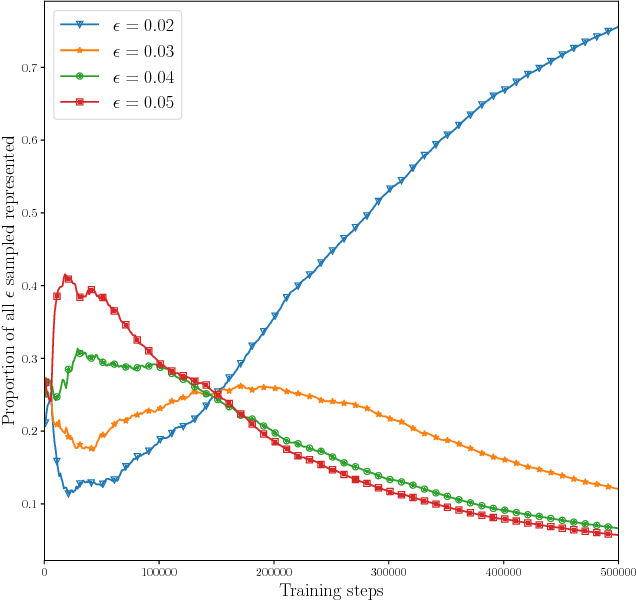
In this paper, we investigate a new form of automated curriculum learning based on adaptive selection of accuracy requirements, called accuracy-based curriculum learning. Using a reinforcement learning agent based on the Deep Deterministic Policy Gradient algorithm and addressing the Reacher environment, we first show that an agent trained with various accuracy requirements sampled randomly learns more efficiently than when asked to be very accurate at all times. Then we show that adaptive selection of accuracy requirements, based on a local measure of competence progress, automatically generates a curriculum where difficulty progressively increases, resulting in a better learning efficiency than sampling randomly.