 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
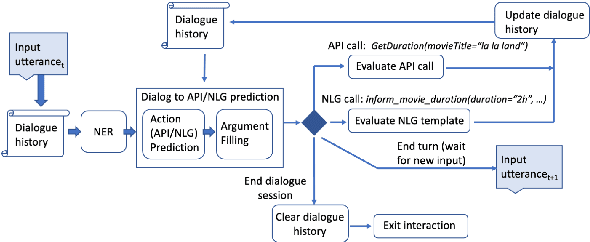

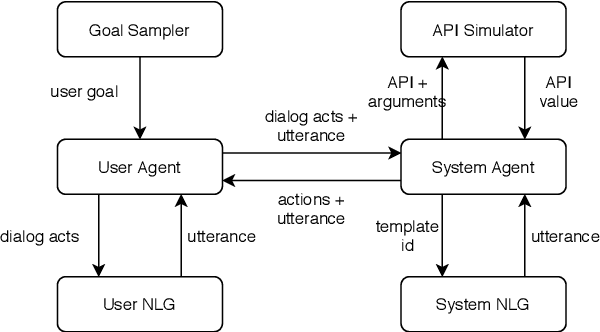
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
MA-DST: Multi-Attention Based Scalable Dialog State Tracking
Feb 07, 2020

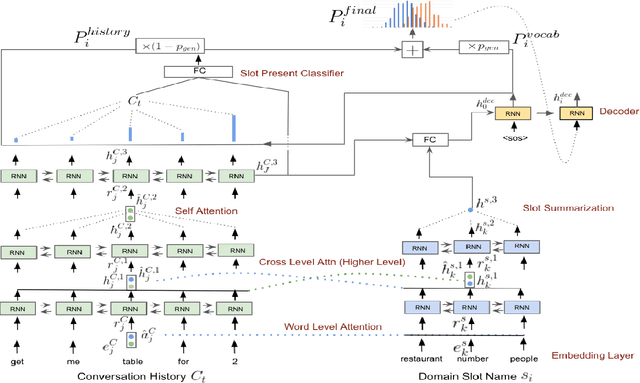
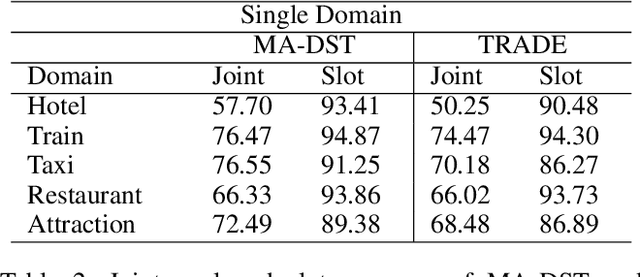
Task oriented dialog agents provide a natural language interface for users to complete their goal. Dialog State Tracking (DST), which is often a core component of these systems, tracks the system's understanding of the user's goal throughout the conversation. To enable accurate multi-domain DST, the model needs to encode dependencies between past utterances and slot semantics and understand the dialog context, including long-range cross-domain references. We introduce a novel architecture for this task to encode the conversation history and slot semantics more robustly by using attention mechanisms at multiple granularities. In particular, we use cross-attention to model relationships between the context and slots at different semantic levels and self-attention to resolve cross-domain coreferences. In addition, our proposed architecture does not rely on knowing the domain ontologies beforehand and can also be used in a zero-shot setting for new domains or unseen slot values. Our model improves the joint goal accuracy by 5% (absolute) in the full-data setting and by up to 2% (absolute) in the zero-shot setting over the present state-of-the-art on the MultiWoZ 2.1 dataset.