 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Target Domain Specific Classifier for Partial Domain Adaptation
Aug 25, 2020
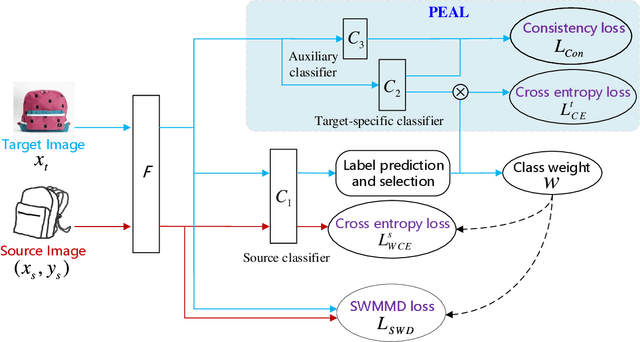
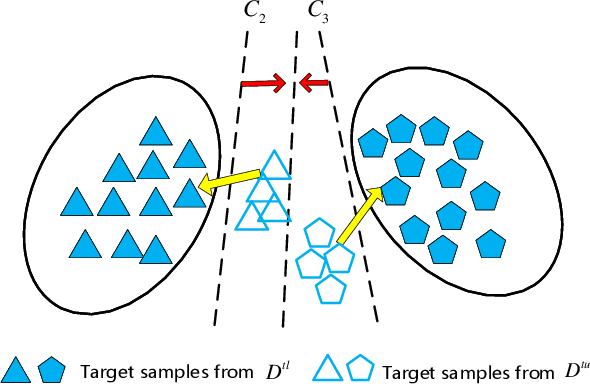

Unsupervised domain adaptation~(UDA) aims at reducing the distribution discrepancy when transferring knowledge from a labeled source domain to an unlabeled target domain. Previous UDA methods assume that the source and target domains share an identical label space, which is unrealistic in practice since the label information of the target domain is agnostic. This paper focuses on a more realistic UDA scenario, i.e. partial domain adaptation (PDA), where the target label space is subsumed to the source label space. In the PDA scenario, the source outliers that are absent in the target domain may be wrongly matched to the target domain (technically named negative transfer), leading to performance degradation of UDA methods. This paper proposes a novel Target Domain Specific Classifier Learning-based Domain Adaptation (TSCDA) method. TSCDA presents a soft-weighed maximum mean discrepancy criterion to partially align feature distributions and alleviate negative transfer. Also, it learns a target-specific classifier for the target domain with pseudo-labels and multiple auxiliary classifiers, to further address classifier shift. A module named Peers Assisted Learning is used to minimize the prediction difference between multiple target-specific classifiers, which makes the classifiers more discriminant for the target domain. Extensive experiments conducted on three PDA benchmark datasets show that TSCDA outperforms other state-of-the-art methods with a large margin, e.g. $4\%$ and $5.6\%$ averagely on Office-31 and Office-Home, respectively.
Learning Kernel for Conditional Moment-Matching Discrepancy-based Image Classification
Aug 24, 2020


Conditional Maximum Mean Discrepancy (CMMD) can capture the discrepancy between conditional distributions by drawing support from nonlinear kernel functions, thus it has been successfully used for pattern classification. However, CMMD does not work well on complex distributions, especially when the kernel function fails to correctly characterize the difference between intra-class similarity and inter-class similarity. In this paper, a new kernel learning method is proposed to improve the discrimination performance of CMMD. It can be operated with deep network features iteratively and thus denoted as KLN for abbreviation. The CMMD loss and an auto-encoder (AE) are used to learn an injective function. By considering the compound kernel, i.e., the injective function with a characteristic kernel, the effectiveness of CMMD for data category description is enhanced. KLN can simultaneously learn a more expressive kernel and label prediction distribution, thus, it can be used to improve the classification performance in both supervised and semi-supervised learning scenarios. In particular, the kernel-based similarities are iteratively learned on the deep network features, and the algorithm can be implemented in an end-to-end manner. Extensive experiments are conducted on four benchmark datasets, including MNIST, SVHN, CIFAR-10 and CIFAR-100. The results indicate that KLN achieves state-of-the-art classification performance.
Dual Adversarial Auto-Encoders for Clustering
Aug 23, 2020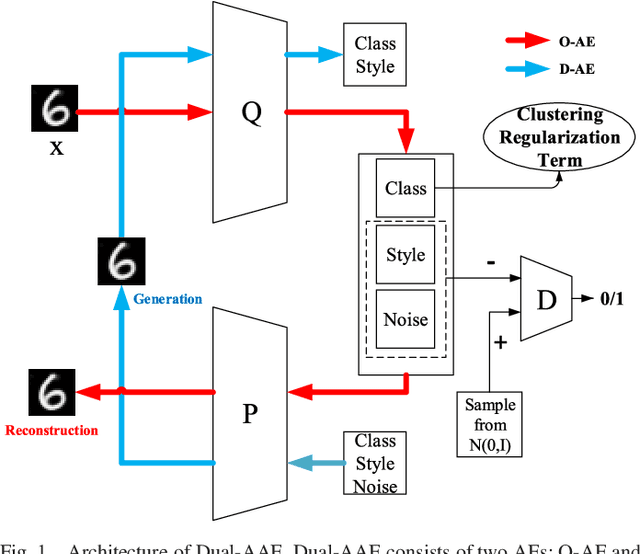
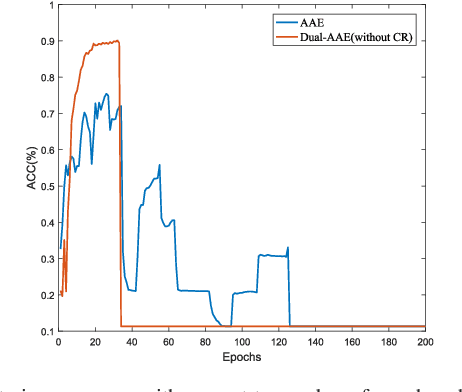
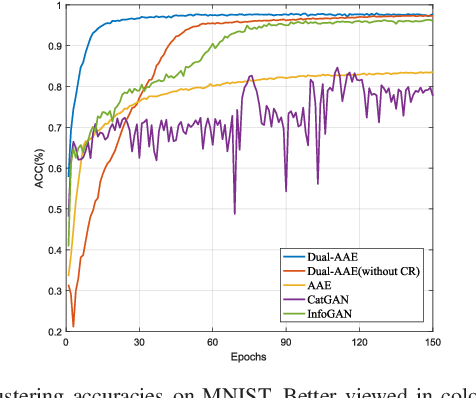

As a powerful approach for exploratory data analysis, unsupervised clustering is a fundamental task in computer vision and pattern recognition. Many clustering algorithms have been developed, but most of them perform unsatisfactorily on the data with complex structures. Recently, Adversarial Auto-Encoder (AAE) shows effectiveness on tackling such data by combining Auto-Encoder (AE) and adversarial training, but it cannot effectively extract classification information from the unlabeled data. In this work, we propose Dual Adversarial Auto-encoder (Dual-AAE) which simultaneously maximizes the likelihood function and mutual information between observed examples and a subset of latent variables. By performing variational inference on the objective function of Dual-AAE, we derive a new reconstruction loss which can be optimized by training a pair of Auto-encoders. Moreover, to avoid mode collapse, we introduce the clustering regularization term for the category variable. Experiments on four benchmarks show that Dual-AAE achieves superior performance over state-of-the-art clustering methods. Besides, by adding a reject option, the clustering accuracy of Dual-AAE can reach that of supervised CNN algorithms. Dual-AAE can also be used for disentangling style and content of images without using supervised information.
Domain Adaptation and Image Classification via Deep Conditional Adaptation Network
Jun 14, 2020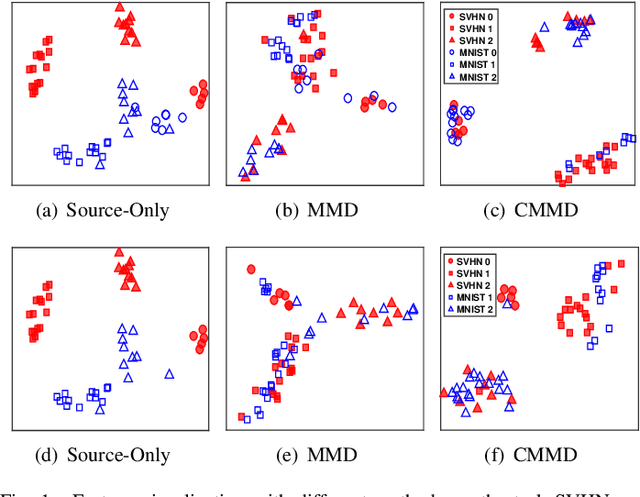



Unsupervised domain adaptation aims to generalize the supervised model trained on a source domain to an unlabeled target domain. Marginal distribution alignment of feature spaces is widely used to reduce the domain discrepancy between the source and target domains. However, it assumes that the source and target domains share the same label distribution, which limits their application scope. In this paper, we consider a more general application scenario where the label distributions of the source and target domains are not the same. In this scenario, marginal distribution alignment-based methods will be vulnerable to negative transfer. To address this issue, we propose a novel unsupervised domain adaptation method, Deep Conditional Adaptation Network (DCAN), based on conditional distribution alignment of feature spaces. To be specific, we reduce the domain discrepancy by minimizing the Conditional Maximum Mean Discrepancy between the conditional distributions of deep features on the source and target domains, and extract the discriminant information from target domain by maximizing the mutual information between samples and the prediction labels. In addition, DCAN can be used to address a special scenario, Partial unsupervised domain adaptation, where the target domain category is a subset of the source domain category. Experiments on both unsupervised domain adaptation and Partial unsupervised domain adaptation show that DCAN achieves superior classification performance over state-of-the-art methods. In particular, DCAN achieves great improvement in the tasks with large difference in label distributions (6.1\% on SVHN to MNIST, 5.4\% in UDA tasks on Office-Home and 4.5\% in Partial UDA tasks on Office-Home).
Unsupervised Domain Adaptation via Discriminative Manifold Embedding and Alignment
Feb 28, 2020
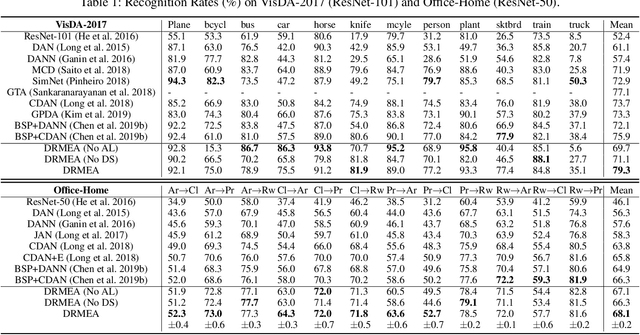
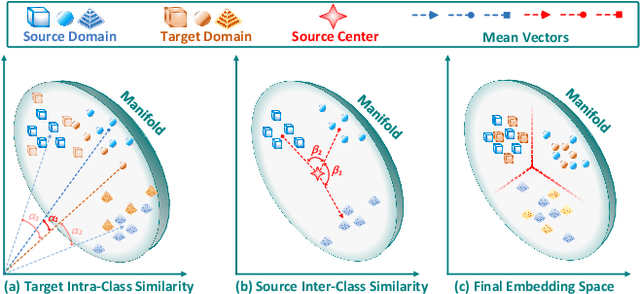

Unsupervised domain adaptation is effective in leveraging the rich information from the source domain to the unsupervised target domain. Though deep learning and adversarial strategy make an important breakthrough in the adaptability of features, there are two issues to be further explored. First, the hard-assigned pseudo labels on the target domain are risky to the intrinsic data structure. Second, the batch-wise training manner in deep learning limits the description of the global structure. In this paper, a Riemannian manifold learning framework is proposed to achieve transferability and discriminability consistently. As to the first problem, this method establishes a probabilistic discriminant criterion on the target domain via soft labels. Further, this criterion is extended to a global approximation scheme for the second issue; such approximation is also memory-saving. The manifold metric alignment is exploited to be compatible with the embedding space. A theoretical error bound is derived to facilitate the alignment. Extensive experiments have been conducted to investigate the proposal and results of the comparison study manifest the superiority of consistent manifold learning framework.