 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Kernel for Conditional Moment-Matching Discrepancy-based Image Classification
Aug 24, 2020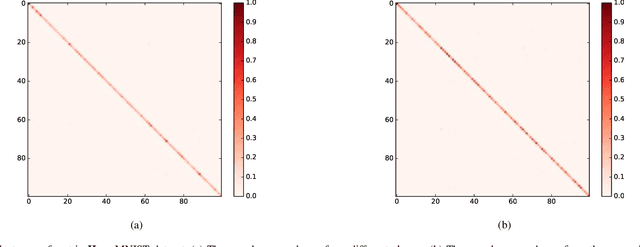
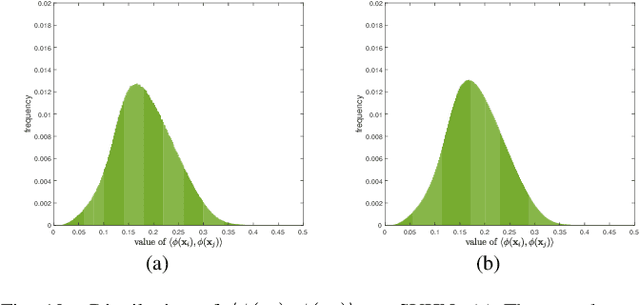


Conditional Maximum Mean Discrepancy (CMMD) can capture the discrepancy between conditional distributions by drawing support from nonlinear kernel functions, thus it has been successfully used for pattern classification. However, CMMD does not work well on complex distributions, especially when the kernel function fails to correctly characterize the difference between intra-class similarity and inter-class similarity. In this paper, a new kernel learning method is proposed to improve the discrimination performance of CMMD. It can be operated with deep network features iteratively and thus denoted as KLN for abbreviation. The CMMD loss and an auto-encoder (AE) are used to learn an injective function. By considering the compound kernel, i.e., the injective function with a characteristic kernel, the effectiveness of CMMD for data category description is enhanced. KLN can simultaneously learn a more expressive kernel and label prediction distribution, thus, it can be used to improve the classification performance in both supervised and semi-supervised learning scenarios. In particular, the kernel-based similarities are iteratively learned on the deep network features, and the algorithm can be implemented in an end-to-end manner. Extensive experiments are conducted on four benchmark datasets, including MNIST, SVHN, CIFAR-10 and CIFAR-100. The results indicate that KLN achieves state-of-the-art classification performance.
Unsupervised Domain Adaptation via Discriminative Manifold Propagation
Aug 23, 2020

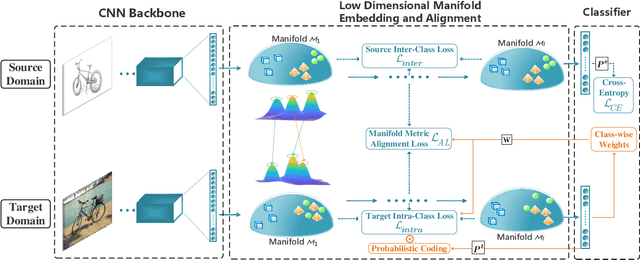

Unsupervised domain adaptation is effective in leveraging rich information from a labeled source domain to an unlabeled target domain. Though deep learning and adversarial strategy made a significant breakthrough in the adaptability of features, there are two issues to be further studied. First, hard-assigned pseudo labels on the target domain are arbitrary and error-prone, and direct application of them may destroy the intrinsic data structure. Second, batch-wise training of deep learning limits the characterization of the global structure. In this paper, a Riemannian manifold learning framework is proposed to achieve transferability and discriminability simultaneously. For the first issue, this framework establishes a probabilistic discriminant criterion on the target domain via soft labels. Based on pre-built prototypes, this criterion is extended to a global approximation scheme for the second issue. Manifold metric alignment is adopted to be compatible with the embedding space. The theoretical error bounds of different alignment metrics are derived for constructive guidance. The proposed method can be used to tackle a series of variants of domain adaptation problems, including both vanilla and partial settings. Extensive experiments have been conducted to investigate the method and a comparative study shows the superiority of the discriminative manifold learning framework.
Discriminative Residual Analysis for Image Set Classification with Posture and Age Variations
Aug 23, 2020
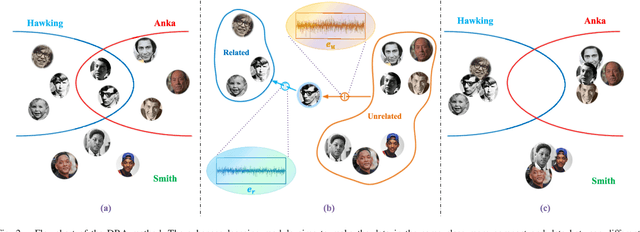


Image set recognition has been widely applied in many practical problems like real-time video retrieval and image caption tasks. Due to its superior performance, it has grown into a significant topic in recent years. However, images with complicated variations, e.g., postures and human ages, are difficult to address, as these variations are continuous and gradual with respect to image appearance. Consequently, the crucial point of image set recognition is to mine the intrinsic connection or structural information from the image batches with variations. In this work, a Discriminant Residual Analysis (DRA) method is proposed to improve the classification performance by discovering discriminant features in related and unrelated groups. Specifically, DRA attempts to obtain a powerful projection which casts the residual representations into a discriminant subspace. Such a projection subspace is expected to magnify the useful information of the input space as much as possible, then the relation between the training set and the test set described by the given metric or distance will be more precise in the discriminant subspace. We also propose a nonfeasance strategy by defining another approach to construct the unrelated groups, which help to reduce furthermore the cost of sampling errors. Two regularization approaches are used to deal with the probable small sample size problem. Extensive experiments are conducted on benchmark databases, and the results show superiority and efficiency of the new methods.
Domain Adaptation and Image Classification via Deep Conditional Adaptation Network
Jun 14, 2020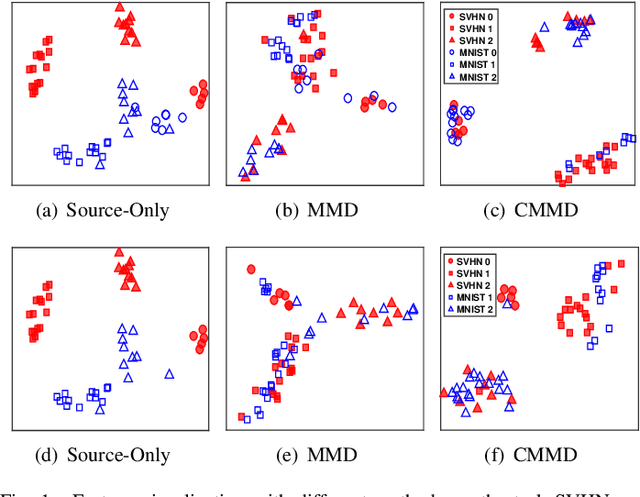



Unsupervised domain adaptation aims to generalize the supervised model trained on a source domain to an unlabeled target domain. Marginal distribution alignment of feature spaces is widely used to reduce the domain discrepancy between the source and target domains. However, it assumes that the source and target domains share the same label distribution, which limits their application scope. In this paper, we consider a more general application scenario where the label distributions of the source and target domains are not the same. In this scenario, marginal distribution alignment-based methods will be vulnerable to negative transfer. To address this issue, we propose a novel unsupervised domain adaptation method, Deep Conditional Adaptation Network (DCAN), based on conditional distribution alignment of feature spaces. To be specific, we reduce the domain discrepancy by minimizing the Conditional Maximum Mean Discrepancy between the conditional distributions of deep features on the source and target domains, and extract the discriminant information from target domain by maximizing the mutual information between samples and the prediction labels. In addition, DCAN can be used to address a special scenario, Partial unsupervised domain adaptation, where the target domain category is a subset of the source domain category. Experiments on both unsupervised domain adaptation and Partial unsupervised domain adaptation show that DCAN achieves superior classification performance over state-of-the-art methods. In particular, DCAN achieves great improvement in the tasks with large difference in label distributions (6.1\% on SVHN to MNIST, 5.4\% in UDA tasks on Office-Home and 4.5\% in Partial UDA tasks on Office-Home).