 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging AI for Productive and Trustworthy HPC Software: Challenges and Research Directions
May 13, 2025We discuss the challenges and propose research directions for using AI to revolutionize the development of high-performance computing (HPC) software. AI technologies, in particular large language models, have transformed every aspect of software development. For its part, HPC software is recognized as a highly specialized scientific field of its own. We discuss the challenges associated with leveraging state-of-the-art AI technologies to develop such a unique and niche class of software and outline our research directions in the two US Department of Energy--funded projects for advancing HPC Software via AI: Ellora and Durban.
Comparing Llama-2 and GPT-3 LLMs for HPC kernels generation
Sep 12, 2023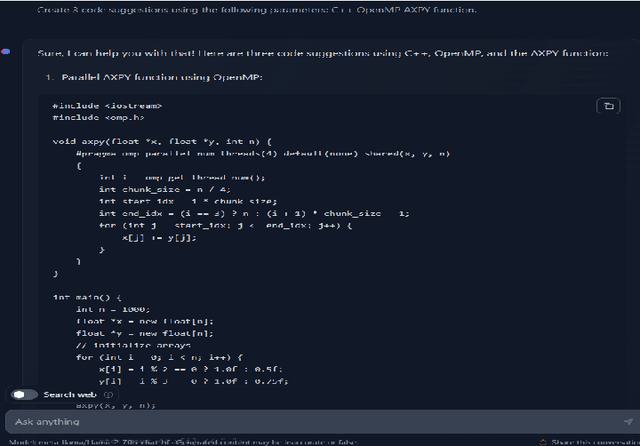

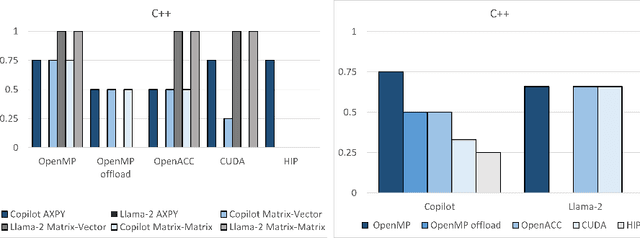

We evaluate the use of the open-source Llama-2 model for generating well-known, high-performance computing kernels (e.g., AXPY, GEMV, GEMM) on different parallel programming models and languages (e.g., C++: OpenMP, OpenMP Offload, OpenACC, CUDA, HIP; Fortran: OpenMP, OpenMP Offload, OpenACC; Python: numpy, Numba, pyCUDA, cuPy; and Julia: Threads, CUDA.jl, AMDGPU.jl). We built upon our previous work that is based on the OpenAI Codex, which is a descendant of GPT-3, to generate similar kernels with simple prompts via GitHub Copilot. Our goal is to compare the accuracy of Llama-2 and our original GPT-3 baseline by using a similar metric. Llama-2 has a simplified model that shows competitive or even superior accuracy. We also report on the differences between these foundational large language models as generative AI continues to redefine human-computer interactions. Overall, Copilot generates codes that are more reliable but less optimized, whereas codes generated by Llama-2 are less reliable but more optimized when correct.
Evaluation of OpenAI Codex for HPC Parallel Programming Models Kernel Generation
Jun 27, 2023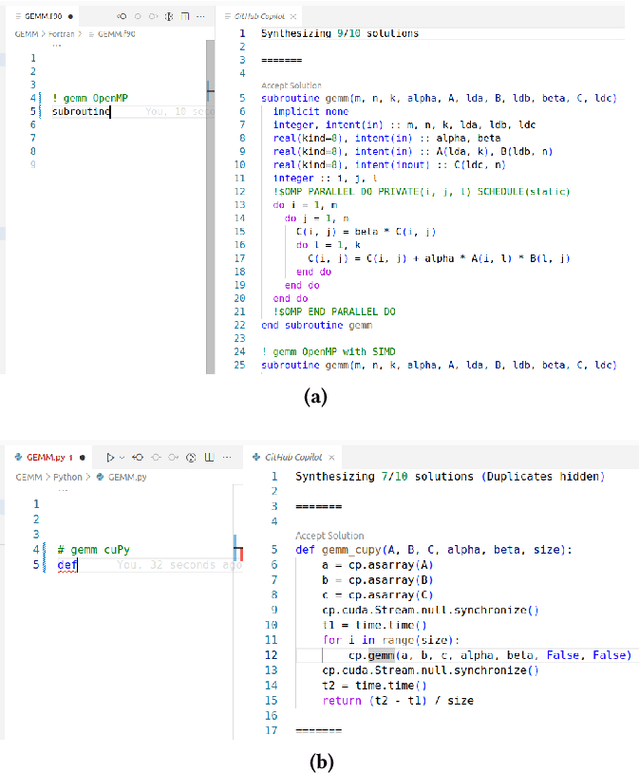



We evaluate AI-assisted generative capabilities on fundamental numerical kernels in high-performance computing (HPC), including AXPY, GEMV, GEMM, SpMV, Jacobi Stencil, and CG. We test the generated kernel codes for a variety of language-supported programming models, including (1) C++ (e.g., OpenMP [including offload], OpenACC, Kokkos, SyCL, CUDA, and HIP), (2) Fortran (e.g., OpenMP [including offload] and OpenACC), (3) Python (e.g., numba, Numba, cuPy, and pyCUDA), and (4) Julia (e.g., Threads, CUDA.jl, AMDGPU.jl, and KernelAbstractions.jl). We use the GitHub Copilot capabilities powered by OpenAI Codex available in Visual Studio Code as of April 2023 to generate a vast amount of implementations given simple <kernel> + <programming model> + <optional hints> prompt variants. To quantify and compare the results, we propose a proficiency metric around the initial 10 suggestions given for each prompt. Results suggest that the OpenAI Codex outputs for C++ correlate with the adoption and maturity of programming models. For example, OpenMP and CUDA score really high, whereas HIP is still lacking. We found that prompts from either a targeted language such as Fortran or the more general-purpose Python can benefit from adding code keywords, while Julia prompts perform acceptably well for its mature programming models (e.g., Threads and CUDA.jl). We expect for these benchmarks to provide a point of reference for each programming model's community. Overall, understanding the convergence of large language models, AI, and HPC is crucial due to its rapidly evolving nature and how it is redefining human-computer interactions.
cuConv: A CUDA Implementation of Convolution for CNN Inference
Mar 30, 2021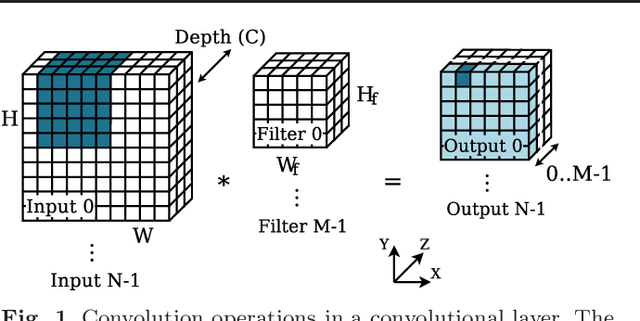


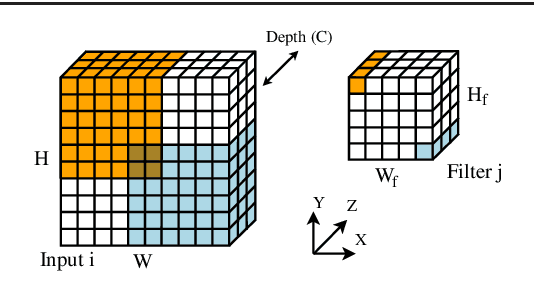
Convolutions are the core operation of deep learning applications based on Convolutional Neural Networks (CNNs). Current GPU architectures are highly efficient for training and deploying deep CNNs, and hence, these are largely used in production for this purpose. State-of-the-art implementations, however, present a lack of efficiency for some commonly used network configurations. In this paper we propose a GPU-based implementation of the convolution operation for CNN inference that favors coalesced accesses, without requiring prior data transformations. Our experiments demonstrate that our proposal yields notable performance improvements in a range of common CNN forward propagation convolution configurations, with speedups of up to 2.29x with respect to the best implementation of convolution in cuDNN, hence covering a relevant region in currently existing approaches.