 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecuConv: A CUDA Implementation of Convolution for CNN Inference
Paper and Code
Mar 30, 2021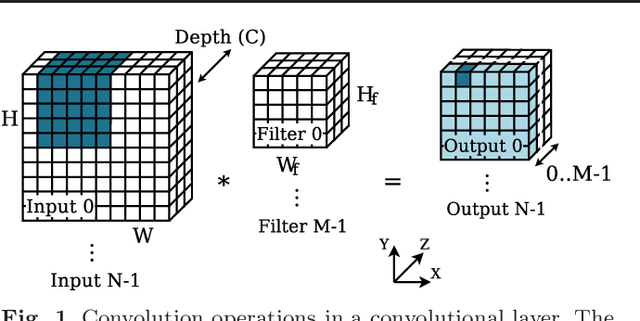


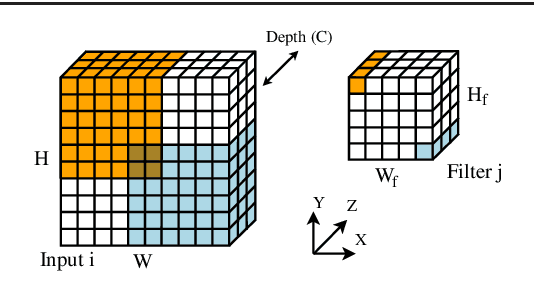
Convolutions are the core operation of deep learning applications based on Convolutional Neural Networks (CNNs). Current GPU architectures are highly efficient for training and deploying deep CNNs, and hence, these are largely used in production for this purpose. State-of-the-art implementations, however, present a lack of efficiency for some commonly used network configurations. In this paper we propose a GPU-based implementation of the convolution operation for CNN inference that favors coalesced accesses, without requiring prior data transformations. Our experiments demonstrate that our proposal yields notable performance improvements in a range of common CNN forward propagation convolution configurations, with speedups of up to 2.29x with respect to the best implementation of convolution in cuDNN, hence covering a relevant region in currently existing approaches.