 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Radio Experimental Infrastructure Architecture Towards 6G
Feb 29, 2024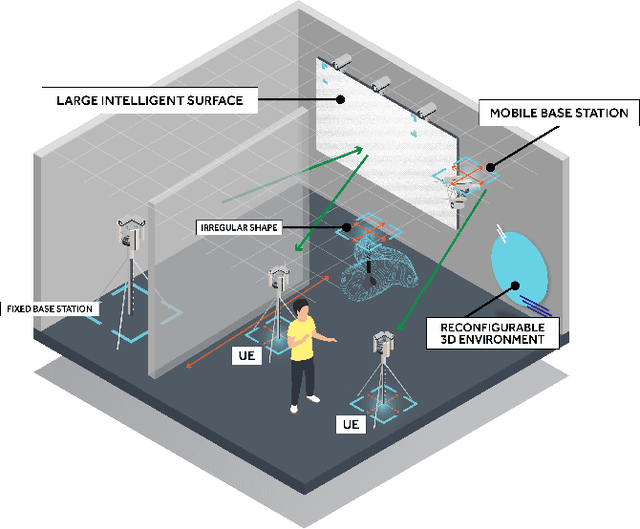
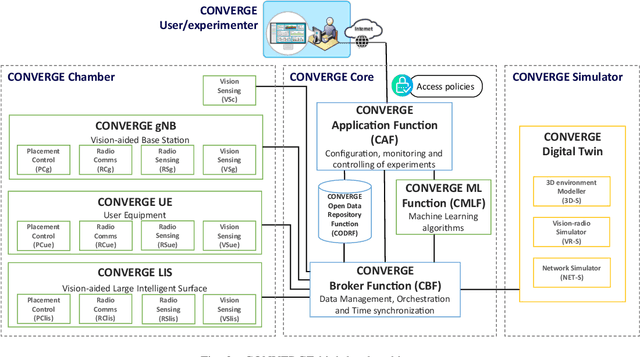
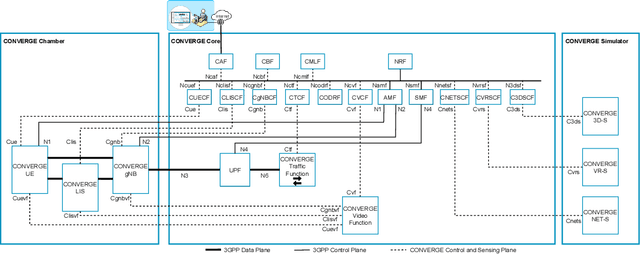
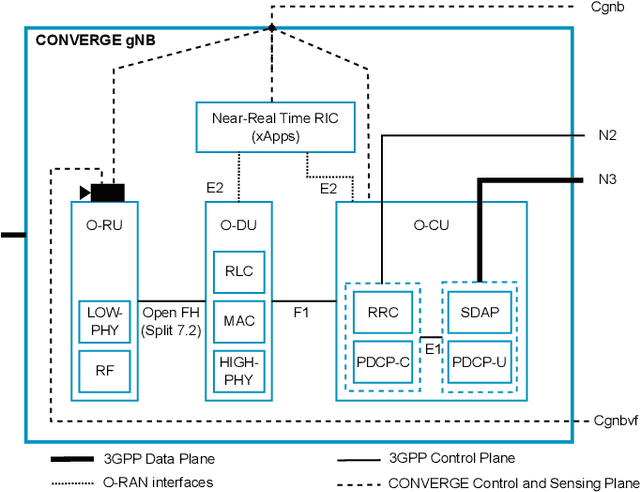
Telecommunications and computer vision have evolved separately so far. Yet, with the shift to sub-terahertz (sub-THz) and terahertz (THz) radio communications, there is an opportunity to explore computer vision technologies together with radio communications, considering the dependency of both technologies on Line of Sight. The combination of radio sensing and computer vision can address challenges such as obstructions and poor lighting. Also, machine learning algorithms, capable of processing multimodal data, play a crucial role in deriving insights from raw and low-level sensing data, offering a new level of abstraction that can enhance various applications and use cases such as beamforming and terminal handovers. This paper introduces CONVERGE, a pioneering vision-radio paradigm that bridges this gap by leveraging Integrated Sensing and Communication (ISAC) to facilitate a dual "View-to-Communicate, Communicate-to-View" approach. CONVERGE offers tools that merge wireless communications and computer vision, establishing a novel Research Infrastructure (RI) that will be open to the scientific community and capable of providing open datasets. This new infrastructure will support future research in 6G and beyond concerning multiple verticals, such as telecommunications, automotive, manufacturing, media, and health.
Emotion4MIDI: a Lyrics-based Emotion-Labeled Symbolic Music Dataset
Jul 27, 2023



We present a new large-scale emotion-labeled symbolic music dataset consisting of 12k MIDI songs. To create this dataset, we first trained emotion classification models on the GoEmotions dataset, achieving state-of-the-art results with a model half the size of the baseline. We then applied these models to lyrics from two large-scale MIDI datasets. Our dataset covers a wide range of fine-grained emotions, providing a valuable resource to explore the connection between music and emotions and, especially, to develop models that can generate music based on specific emotions. Our code for inference, trained models, and datasets are available online.
Symbolic music generation conditioned on continuous-valued emotions
Mar 30, 2022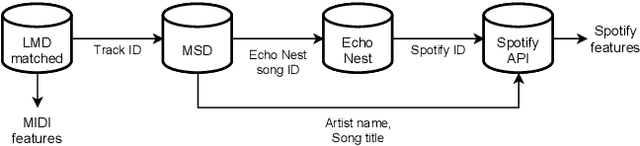
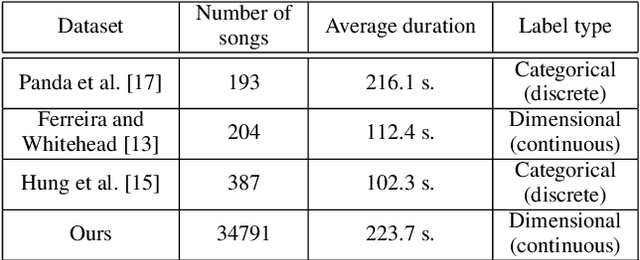
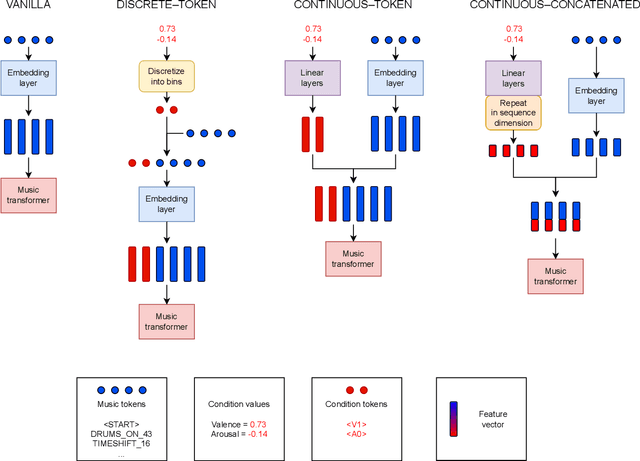
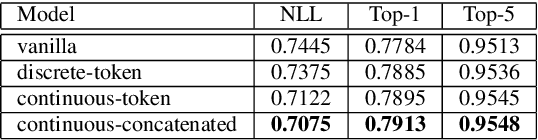
In this paper we present a new approach for the generation of multi-instrument symbolic music driven by musical emotion. The principal novelty of our approach centres on conditioning a state-of-the-art transformer based on continuous-valued valence and arousal labels. In addition, we provide a new large-scale dataset of symbolic music paired with emotion labels in terms of valence and arousal. We evaluate our approach in a quantitative manner in two ways, first by measuring its note prediction accuracy, and second via a regression task in the valence-arousal plane. Our results demonstrate that our proposed approaches outperform conditioning using control tokens which is representative of the current state of the art.
Recent Advances and Challenges in Deep Audio-Visual Correlation Learning
Feb 28, 2022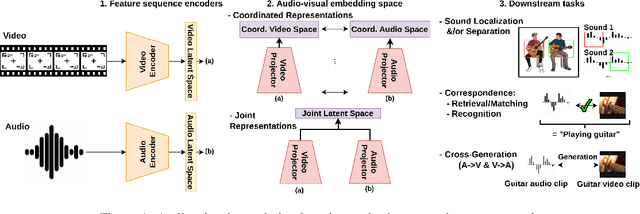
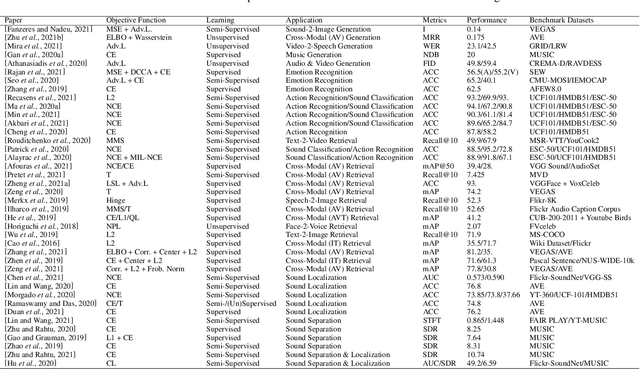
Audio-visual correlation learning aims to capture essential correspondences and understand natural phenomena between audio and video. With the rapid growth of deep learning, an increasing amount of attention has been paid to this emerging research issue. Through the past few years, various methods and datasets have been proposed for audio-visual correlation learning, which motivate us to conclude a comprehensive survey. This survey paper focuses on state-of-the-art (SOTA) models used to learn correlations between audio and video, but also discusses some tasks of definition and paradigm applied in AI multimedia. In addition, we investigate some objective functions frequently used for optimizing audio-visual correlation learning models and discuss how audio-visual data is exploited in the optimization process. Most importantly, we provide an extensive comparison and summarization of the recent progress of SOTA audio-visual correlation learning and discuss future research directions.