 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-based Music Generation
Feb 05, 2026As the volume of video content on the internet grows rapidly, finding a suitable soundtrack remains a significant challenge. This thesis presents EMSYNC (EMotion and SYNChronization), a fast, free, and automatic solution that generates music tailored to the input video, enabling content creators to enhance their productions without composing or licensing music. Our model creates music that is emotionally and rhythmically synchronized with the video. A core component of EMSYNC is a novel video emotion classifier. By leveraging pretrained deep neural networks for feature extraction and keeping them frozen while training only fusion layers, we reduce computational complexity while improving accuracy. We show the generalization abilities of our method by obtaining state-of-the-art results on Ekman-6 and MovieNet. Another key contribution is a large-scale, emotion-labeled MIDI dataset for affective music generation. We then present an emotion-based MIDI generator, the first to condition on continuous emotional values rather than discrete categories, enabling nuanced music generation aligned with complex emotional content. To enhance temporal synchronization, we introduce a novel temporal boundary conditioning method, called "boundary offset encodings," aligning musical chords with scene changes. Combining video emotion classification, emotion-based music generation, and temporal boundary conditioning, EMSYNC emerges as a fully automatic video-based music generator. User studies show that it consistently outperforms existing methods in terms of music richness, emotional alignment, temporal synchronization, and overall preference, setting a new state-of-the-art in video-based music generation.
Emotion4MIDI: a Lyrics-based Emotion-Labeled Symbolic Music Dataset
Jul 27, 2023



We present a new large-scale emotion-labeled symbolic music dataset consisting of 12k MIDI songs. To create this dataset, we first trained emotion classification models on the GoEmotions dataset, achieving state-of-the-art results with a model half the size of the baseline. We then applied these models to lyrics from two large-scale MIDI datasets. Our dataset covers a wide range of fine-grained emotions, providing a valuable resource to explore the connection between music and emotions and, especially, to develop models that can generate music based on specific emotions. Our code for inference, trained models, and datasets are available online.
Symbolic music generation conditioned on continuous-valued emotions
Mar 30, 2022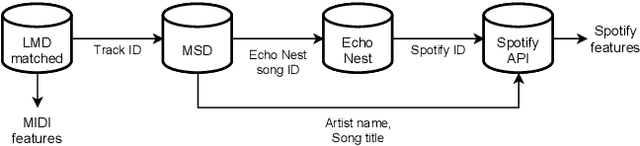
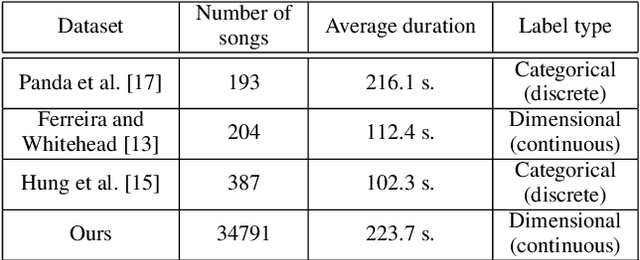
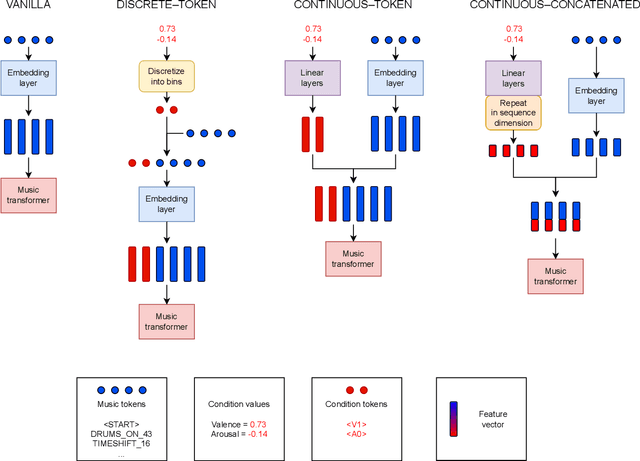
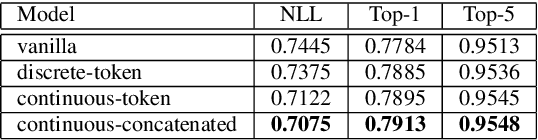
In this paper we present a new approach for the generation of multi-instrument symbolic music driven by musical emotion. The principal novelty of our approach centres on conditioning a state-of-the-art transformer based on continuous-valued valence and arousal labels. In addition, we provide a new large-scale dataset of symbolic music paired with emotion labels in terms of valence and arousal. We evaluate our approach in a quantitative manner in two ways, first by measuring its note prediction accuracy, and second via a regression task in the valence-arousal plane. Our results demonstrate that our proposed approaches outperform conditioning using control tokens which is representative of the current state of the art.
On Filter Generalization for Music Bandwidth Extension Using Deep Neural Networks
Nov 14, 2020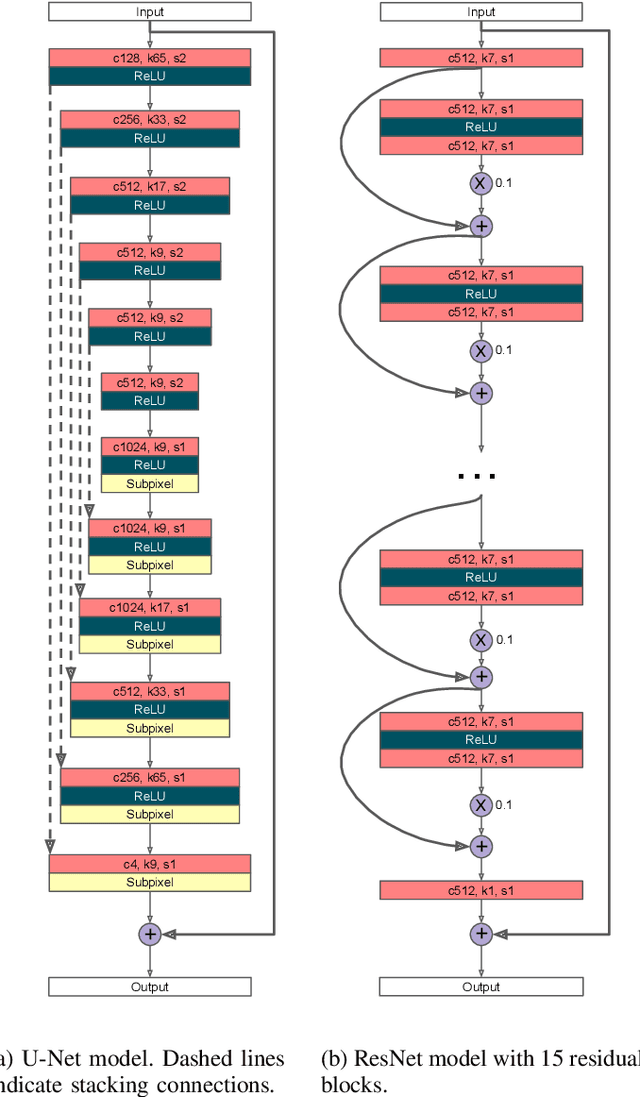
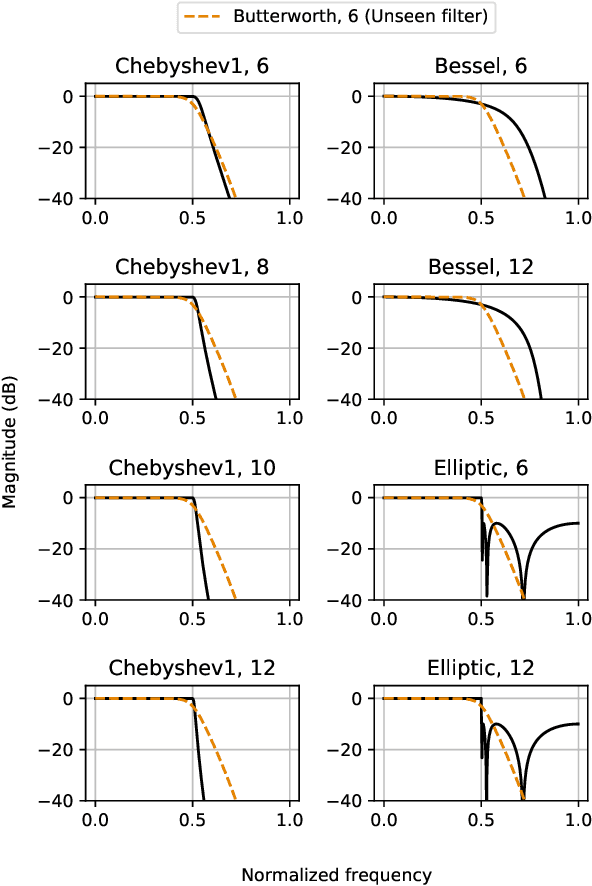
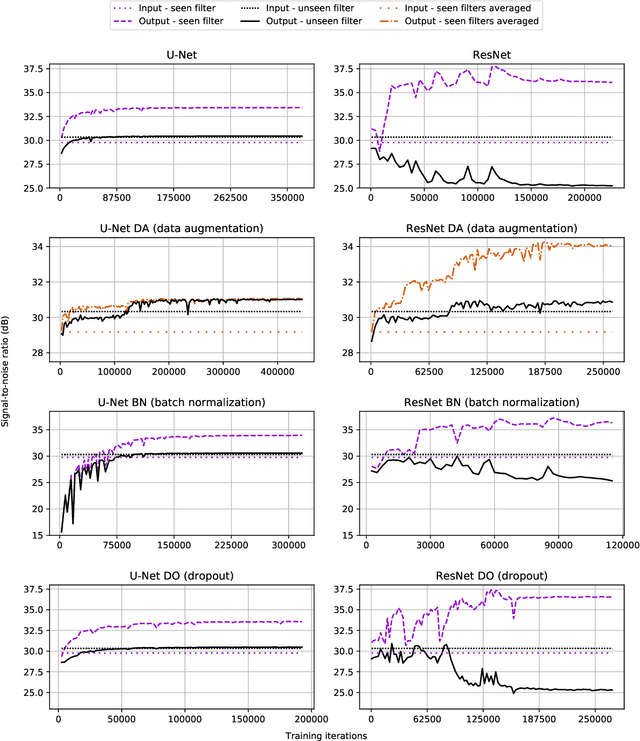
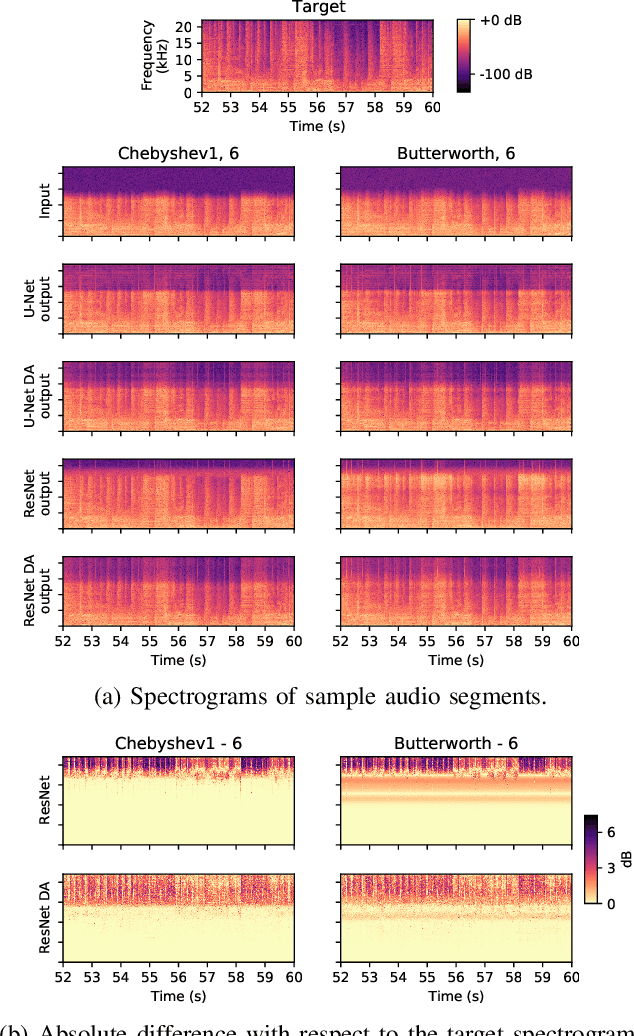
In this paper, we address a sub-topic of the broad domain of audio enhancement, namely musical audio bandwidth extension. We formulate the bandwidth extension problem using deep neural networks, where a band-limited signal is provided as input to the network, with the goal of reconstructing a full-bandwidth output. Our main contribution centers on the impact of the choice of low pass filter when training and subsequently testing the network. For two different state of the art deep architectures, ResNet and U-Net, we demonstrate that when the training and testing filters are matched, improvements in signal-to-noise ratio (SNR) of up to 7dB can be obtained. However, when these filters differ, the improvement falls considerably and under some training conditions results in a lower SNR than the band-limited input. To circumvent this apparent overfitting to filter shape, we propose a data augmentation strategy which utilizes multiple low pass filters during training and leads to improved generalization to unseen filtering conditions at test time.
Can Learned Frame-Prediction Compete with Block-Motion Compensation for Video Coding?
Jul 17, 2020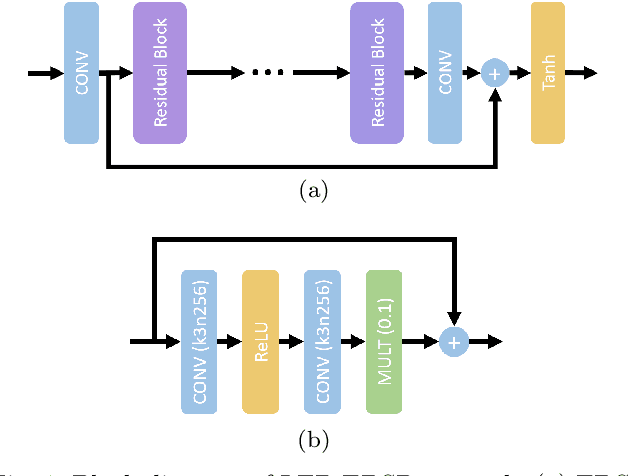
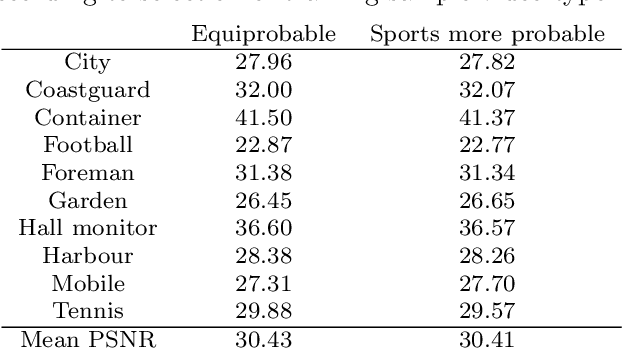
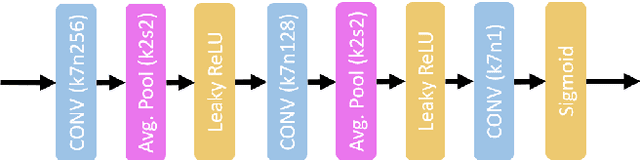
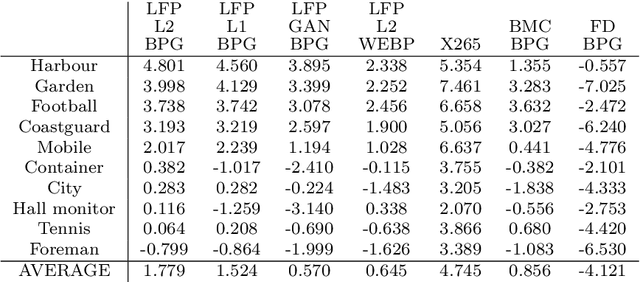
Given recent advances in learned video prediction, we investigate whether a simple video codec using a pre-trained deep model for next frame prediction based on previously encoded/decoded frames without sending any motion side information can compete with standard video codecs based on block-motion compensation. Frame differences given learned frame predictions are encoded by a standard still-image (intra) codec. Experimental results show that the rate-distortion performance of the simple codec with symmetric complexity is on average better than that of x264 codec on 10 MPEG test videos, but does not yet reach the level of x265 codec. This result demonstrates the power of learned frame prediction (LFP), since unlike motion compensation, LFP does not use information from the current picture. The implications of training with L1, L2, or combined L2 and adversarial loss on prediction performance and compression efficiency are analyzed.
Deep Learned Frame Prediction for Video Compression
Nov 27, 2018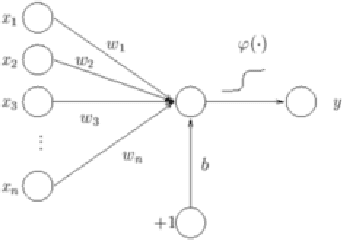
Motion compensation is one of the most essential methods for any video compression algorithm. Video frame prediction is a task analogous to motion compensation. In recent years, the task of frame prediction is undertaken by deep neural networks (DNNs). In this thesis we create a DNN to perform learned frame prediction and additionally implement a codec that contains our DNN. We train our network using two methods for two different goals. Firstly we train our network based on mean square error (MSE) only, aiming to obtain highest PSNR values at frame prediction and video compression. Secondly we use adversarial training to produce visually more realistic frame predictions. For frame prediction, we compare our method with the baseline methods of frame difference and 16x16 block motion compensation. For video compression we further include x264 video codec in the comparison. We show that in frame prediction, adversarial training produces frames that look sharper and more realistic, compared MSE based training, but in video compression it consistently performs worse. This proves that even though adversarial training is useful for generating video frames that are more pleasing to the human eye, they should not be employed for video compression. Moreover, our network trained with MSE produces accurate frame predictions, and in quantitative results, for both tasks, it produces comparable results in all videos and outperforms other methods on average. More specifically, learned frame prediction outperforms other methods in terms of rate-distortion performance in case of high motion video, while the rate-distortion performance of our method is competitive with that of x264 in low motion video.