 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable and Explainable Surrogate Modeling for Simulations: A State-of-the-Art Survey and Perspectives on Explainable AI for Decision-Making
Apr 15, 2026The simulation of complex systems increasingly relies on sophisticated but fundamentally opaque computational black-box simulators. Surrogate models play a central role in reducing the computational cost of complex systems simulations across a wide range of scientific and engineering domains. Notwithstanding, they inevitably inherit and often exacerbate this black-box nature, obscuring how input variables drive physical responses. Conversely, Explainable Artificial Intelligence (XAI) offers powerful tools to unpack these models. Yet, XAI methods struggle with engineering-specific constraints, such as highly correlated inputs, dynamical systems, and rigorous reliability requirements. Consequently, surrogate modeling and XAI have largely evolved as distinct fields of research, despite their strong complementarity. To reconnect these approaches, this state-of-the-art survey provides a structured perspective that maps existing XAI techniques onto the various stages of surrogate modeling workflows for design and exploration. To ground this synthesis, we draw upon illustrative applications across both equation-based simulations and agent-based modeling. We survey a broad spectrum of techniques, highlighting their strengths for revealing interactions and supporting human comprehension. Finally, we identify pressing open challenges, including the explainability of dynamical systems and the handling of mixed-variable systems, and propose a research agenda to make explainability a core, embedded element of simulation-driven workflows from model construction through decision-making. By transforming opaque emulators into explainable tools, this agenda empowers practitioners to move beyond accelerating simulations to extracting actionable insights from complex system behaviors.
From Model-Based Screening to Data-Driven Surrogates: A Multi-Stage Workflow for Exploring Stochastic Agent-Based Models
Apr 03, 2026Systematic exploration of Agent-Based Models (ABMs) is challenged by the curse of dimensionality and their inherent stochasticity. We present a multi-stage pipeline integrating the systematic design of experiments with machine learning surrogates. Using a predator-prey case study, our methodology proceeds in two steps. First, an automated model-based screening identifies dominant variables, assesses outcome variability, and segments the parameter space. Second, we train Machine Learning models to map the remaining nonlinear interaction effects. This approach automates the discovery of unstable regions where system outcomes are highly dependent on nonlinear interactions between many variables. Thus, this work provides modelers with a rigorous, hands-off framework for sensitivity analysis and policy testing, even when dealing with high-dimensional stochastic simulators.
* Published in MABS 2026 - The 27th International Workshop on Multi-Agent-Based Simulation
Analyzing Shapley Additive Explanations to Understand Anomaly Detection Algorithm Behaviors and Their Complementarity
Jan 30, 2026Unsupervised anomaly detection is a challenging problem due to the diversity of data distributions and the lack of labels. Ensemble methods are often adopted to mitigate these challenges by combining multiple detectors, which can reduce individual biases and increase robustness. Yet building an ensemble that is genuinely complementary remains challenging, since many detectors rely on similar decision cues and end up producing redundant anomaly scores. As a result, the potential of ensemble learning is often limited by the difficulty of identifying models that truly capture different types of irregularities. To address this, we propose a methodology for characterizing anomaly detectors through their decision mechanisms. Using SHapley Additive exPlanations, we quantify how each model attributes importance to input features, and we use these attribution profiles to measure similarity between detectors. We show that detectors with similar explanations tend to produce correlated anomaly scores and identify largely overlapping anomalies. Conversely, explanation divergence reliably indicates complementary detection behavior. Our results demonstrate that explanation-driven metrics offer a different criterion than raw outputs for selecting models in an ensemble. However, we also demonstrate that diversity alone is insufficient; high individual model performance remains a prerequisite for effective ensembles. By explicitly targeting explanation diversity while maintaining model quality, we are able to construct ensembles that are more diverse, more complementary, and ultimately more effective for unsupervised anomaly detection.
Adaptive Agents in Spatial Double-Auction Markets: Modeling the Emergence of Industrial Symbiosis
Dec 19, 2025



Industrial symbiosis fosters circularity by enabling firms to repurpose residual resources, yet its emergence is constrained by socio-spatial frictions that shape costs, matching opportunities, and market efficiency. Existing models often overlook the interaction between spatial structure, market design, and adaptive firm behavior, limiting our understanding of where and how symbiosis arises. We develop an agent-based model where heterogeneous firms trade byproducts through a spatially embedded double-auction market, with prices and quantities emerging endogenously from local interactions. Leveraging reinforcement learning, firms adapt their bidding strategies to maximize profit while accounting for transport costs, disposal penalties, and resource scarcity. Simulation experiments reveal the economic and spatial conditions under which decentralized exchanges converge toward stable and efficient outcomes. Counterfactual regret analysis shows that sellers' strategies approach a near Nash equilibrium, while sensitivity analysis highlights how spatial structures and market parameters jointly govern circularity. Our model provides a basis for exploring policy interventions that seek to align firm incentives with sustainability goals, and more broadly demonstrates how decentralized coordination can emerge from adaptive agents in spatially constrained markets.
* AAMAS CC-BY 4.0 licence. Adaptive Agents in Spatial Double-Auction Markets: Modeling the Emergence of Industrial Symbiosis. Full paper. In Proc. of the 25th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2026), Paphos, Cyprus, May 25 - 29, 2026, IFAAMAS, 10 pages
Data-Driven Global Sensitivity Analysis for Engineering Design Based on Individual Conditional Expectations
Dec 12, 2025Explainable machine learning techniques have gained increasing attention in engineering applications, especially in aerospace design and analysis, where understanding how input variables influence data-driven models is essential. Partial Dependence Plots (PDPs) are widely used for interpreting black-box models by showing the average effect of an input variable on the prediction. However, their global sensitivity metric can be misleading when strong interactions are present, as averaging tends to obscure interaction effects. To address this limitation, we propose a global sensitivity metric based on Individual Conditional Expectation (ICE) curves. The method computes the expected feature importance across ICE curves, along with their standard deviation, to more effectively capture the influence of interactions. We provide a mathematical proof demonstrating that the PDP-based sensitivity is a lower bound of the proposed ICE-based metric under truncated orthogonal polynomial expansion. In addition, we introduce an ICE-based correlation value to quantify how interactions modify the relationship between inputs and the output. Comparative evaluations were performed on three cases: a 5-variable analytical function, a 5-variable wind-turbine fatigue problem, and a 9-variable airfoil aerodynamics case, where ICE-based sensitivity was benchmarked against PDP, SHapley Additive exPlanations (SHAP), and Sobol' indices. The results show that ICE-based feature importance provides richer insights than the traditional PDP-based approach, while visual interpretations from PDP, ICE, and SHAP complement one another by offering multiple perspectives.
Modèles de Substitution pour les Modèles à base d'Agents : Enjeux, Méthodes et Applications
May 17, 2025Multi-agent simulations enables the modeling and analyses of the dynamic behaviors and interactions of autonomous entities evolving in complex environments. Agent-based models (ABM) are widely used to study emergent phenomena arising from local interactions. However, their high computational cost poses a significant challenge, particularly for large-scale simulations requiring extensive parameter exploration, optimization, or uncertainty quantification. The increasing complexity of ABM limits their feasibility for real-time decision-making and large-scale scenario analysis. To address these limitations, surrogate models offer an efficient alternative by learning approximations from sparse simulation data. These models provide cheap-to-evaluate predictions, significantly reducing computational costs while maintaining accuracy. Various machine learning techniques, including regression models, neural networks, random forests and Gaussian processes, have been applied to construct robust surrogates. Moreover, uncertainty quantification and sensitivity analysis play a crucial role in enhancing model reliability and interpretability. This article explores the motivations, methods, and applications of surrogate modeling for ABM, emphasizing the trade-offs between accuracy, computational efficiency, and interpretability. Through a case study on a segregation model, we highlight the challenges associated with building and validating surrogate models, comparing different approaches and evaluating their performance. Finally, we discuss future perspectives on integrating surrogate models within ABM to improve scalability, explainability, and real-time decision support across various fields such as ecology, urban planning and economics.
Regularized infill criteria for multi-objective Bayesian optimization with application to aircraft design
Apr 11, 2025


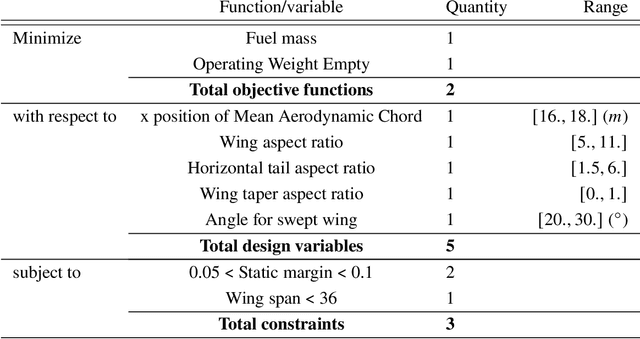
Bayesian optimization is an advanced tool to perform ecient global optimization It consists on enriching iteratively surrogate Kriging models of the objective and the constraints both supposed to be computationally expensive of the targeted optimization problem Nowadays efficient extensions of Bayesian optimization to solve expensive multiobjective problems are of high interest The proposed method in this paper extends the super efficient global optimization with mixture of experts SEGOMOE to solve constrained multiobjective problems To cope with the illposedness of the multiobjective inll criteria different enrichment procedures using regularization techniques are proposed The merit of the proposed approaches are shown on known multiobjective benchmark problems with and without constraints The proposed methods are then used to solve a biobjective application related to conceptual aircraft design with ve unknown design variables and three nonlinear inequality constraints The preliminary results show a reduction of the total cost in terms of function evaluations by a factor of 20 compared to the evolutionary algorithm NSGA-II.
Bayesian optimization for mixed variables using an adaptive dimension reduction process: applications to aircraft design
Apr 11, 2025



Multidisciplinary design optimization methods aim at adapting numerical optimization techniques to the design of engineering systems involving multiple disciplines. In this context, a large number of mixed continuous, integer and categorical variables might arise during the optimization process and practical applications involve a large number of design variables. Recently, there has been a growing interest in mixed variables constrained Bayesian optimization but most existing approaches severely increase the number of the hyperparameters related to the surrogate model. In this paper, we address this issue by constructing surrogate models using less hyperparameters. The reduction process is based on the partial least squares method. An adaptive procedure for choosing the number of hyperparameters is proposed. The performance of the proposed approach is confirmed on analytical tests as well as two real applications related to aircraft design. A significant improvement is obtained compared to genetic algorithms.
Surrogate-based optimization of system architectures subject to hidden constraints
Apr 11, 2025The exploration of novel architectures requires physics-based simulation due to a lack of prior experience to start from, which introduces two specific challenges for optimization algorithms: evaluations become more expensive (in time) and evaluations might fail. The former challenge is addressed by Surrogate-Based Optimization (SBO) algorithms, in particular Bayesian Optimization (BO) using Gaussian Process (GP) models. An overview is provided of how BO can deal with challenges specific to architecture optimization, such as design variable hierarchy and multiple objectives: specific measures include ensemble infills and a hierarchical sampling algorithm. Evaluations might fail due to non-convergence of underlying solvers or infeasible geometry in certain areas of the design space. Such failed evaluations, also known as hidden constraints, pose a particular challenge to SBO/BO, as the surrogate model cannot be trained on empty results. This work investigates various strategies for satisfying hidden constraints in BO algorithms. Three high-level strategies are identified: rejection of failed points from the training set, replacing failed points based on viable (non-failed) points, and predicting the failure region. Through investigations on a set of test problems including a jet engine architecture optimization problem, it is shown that best performance is achieved with a mixed-discrete GP to predict the Probability of Viability (PoV), and by ensuring selected infill points satisfy some minimum PoV threshold. This strategy is demonstrated by solving a jet engine architecture problem that features at 50% failure rate and could not previously be solved by a BO algorithm. The developed BO algorithm and used test problems are available in the open-source Python library SBArchOpt.
Bayesian Optimization of a Lightweight and Accurate Neural Network for Aerodynamic Performance Prediction
Mar 25, 2025

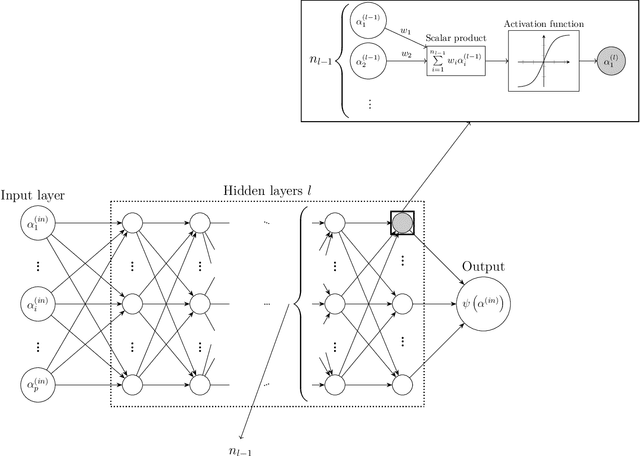

Ensuring high accuracy and efficiency of predictive models is paramount in the aerospace industry, particularly in the context of multidisciplinary design and optimization processes. These processes often require numerous evaluations of complex objective functions, which can be computationally expensive and time-consuming. To build efficient and accurate predictive models, we propose a new approach that leverages Bayesian Optimization (BO) to optimize the hyper-parameters of a lightweight and accurate Neural Network (NN) for aerodynamic performance prediction. To clearly describe the interplay between design variables, hierarchical and categorical kernels are used in the BO formulation. We demonstrate the efficiency of our approach through two comprehensive case studies, where the optimized NN significantly outperforms baseline models and other publicly available NNs in terms of accuracy and parameter efficiency. For the drag coefficient prediction task, the Mean Absolute Percentage Error (MAPE) of our optimized model drops from 0.1433\% to 0.0163\%, which is nearly an order of magnitude improvement over the baseline model. Additionally, our model achieves a MAPE of 0.82\% on a benchmark aircraft self-noise prediction problem, significantly outperforming existing models (where their MAPE values are around 2 to 3\%) while requiring less computational resources. The results highlight the potential of our framework to enhance the scalability and performance of NNs in large-scale MDO problems, offering a promising solution for the aerospace industry.