 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection in 3D Point Clouds using Deep Geometric Descriptors
Feb 23, 2022
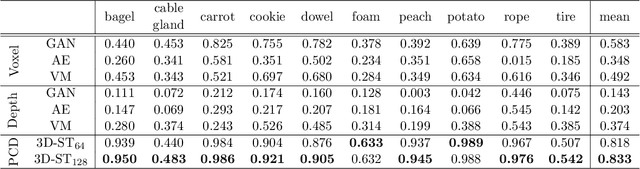
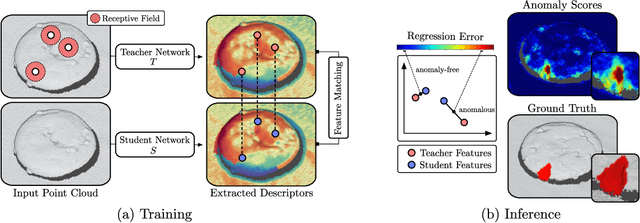
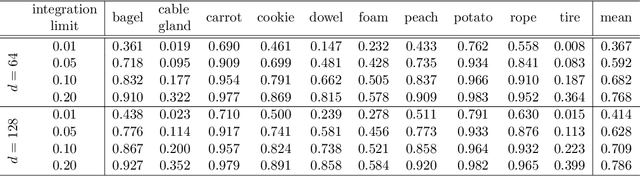
We present a new method for the unsupervised detection of geometric anomalies in high-resolution 3D point clouds. In particular, we propose an adaptation of the established student-teacher anomaly detection framework to three dimensions. A student network is trained to match the output of a pretrained teacher network on anomaly-free point clouds. When applied to test data, regression errors between the teacher and the student allow reliable localization of anomalous structures. To construct an expressive teacher network that extracts dense local geometric descriptors, we introduce a novel self-supervised pretraining strategy. The teacher is trained by reconstructing local receptive fields and does not require annotations. Extensive experiments on the comprehensive MVTec 3D Anomaly Detection dataset highlight the effectiveness of our approach, which outperforms the next-best method by a large margin. Ablation studies show that our approach meets the requirements of practical applications regarding performance, runtime, and memory consumption.
The MVTec 3D-AD Dataset for Unsupervised 3D Anomaly Detection and Localization
Dec 16, 2021
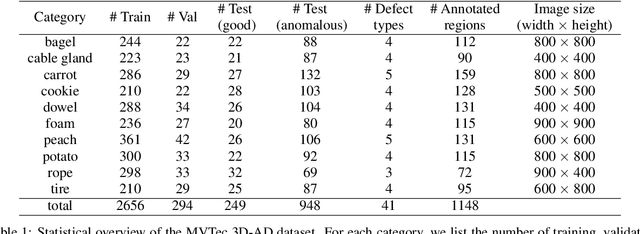


We introduce the first comprehensive 3D dataset for the task of unsupervised anomaly detection and localization. It is inspired by real-world visual inspection scenarios in which a model has to detect various types of defects on manufactured products, even if it is trained only on anomaly-free data. There are defects that manifest themselves as anomalies in the geometric structure of an object. These cause significant deviations in a 3D representation of the data. We employed a high-resolution industrial 3D sensor to acquire depth scans of 10 different object categories. For all object categories, we present a training and validation set, each of which solely consists of scans of anomaly-free samples. The corresponding test sets contain samples showing various defects such as scratches, dents, holes, contaminations, or deformations. Precise ground-truth annotations are provided for every anomalous test sample. An initial benchmark of 3D anomaly detection methods on our dataset indicates a considerable room for improvement.
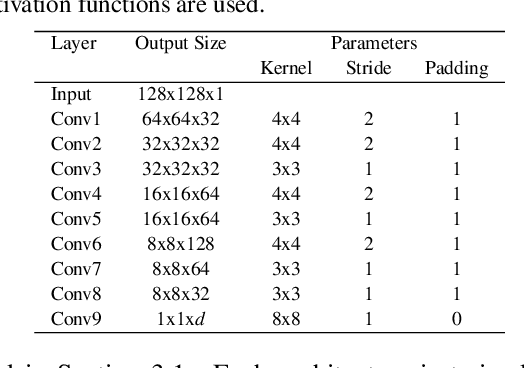
Uninformed Students: Student-Teacher Anomaly Detection with Discriminative Latent Embeddings
Nov 06, 2019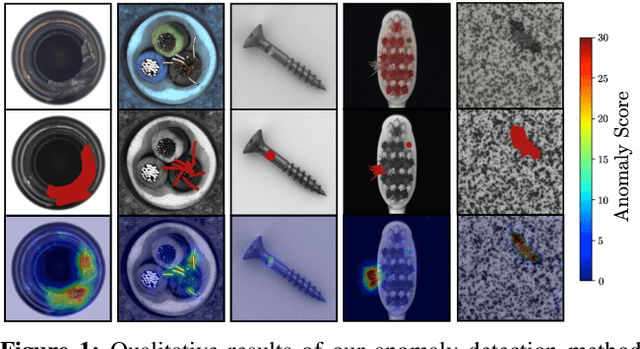
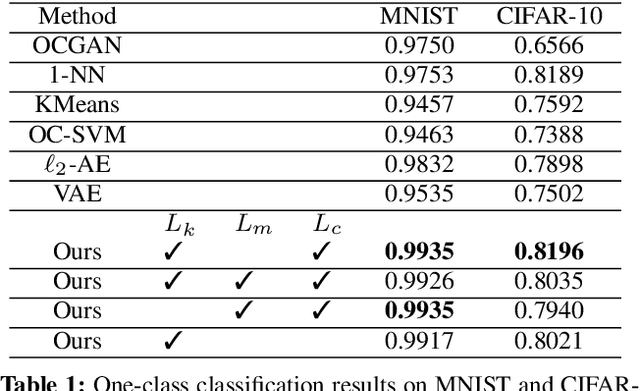

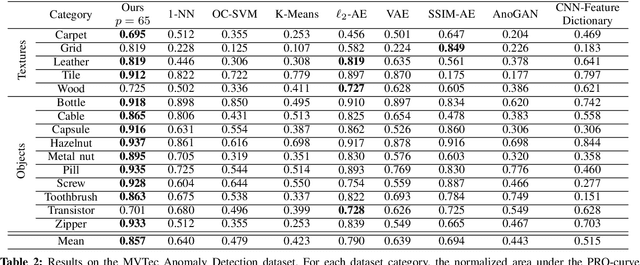
We introduce a simple, yet powerful student-teacher framework for the challenging problem of unsupervised anomaly detection and pixel-precise anomaly segmentation in high-resolution images. To circumvent the need for prior data labeling, student networks are trained to regress the output of a descriptive teacher network that was pretrained on a large dataset of patches from natural images. Anomalies are detected when the student networks fail to generalize outside the manifold of anomaly-free training data, i.e., when the output of the student networks differ from that of the teacher network. Additionally, the intrinsic uncertainty in the student networks can be used as a scoring function that indicates anomalies. We compare our method to a large number of existing deep-learning-based methods for unsupervised anomaly detection. Our experiments demonstrate improvements over state-of-the-art methods on a number of real-world datasets, including the recently introduced MVTec Anomaly Detection dataset that was specifically designed to benchmark anomaly segmentation algorithms.
Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders
Oct 20, 2018
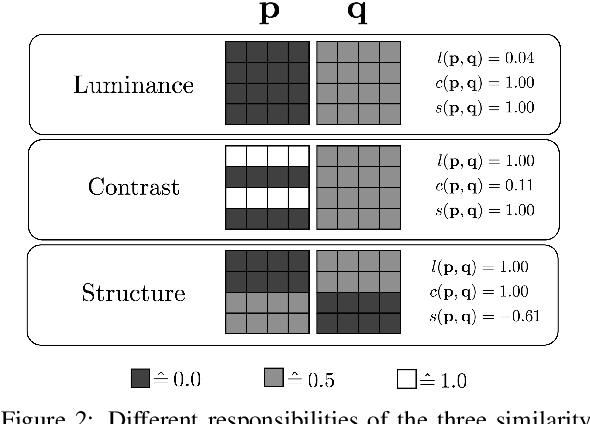

Convolutional autoencoders have emerged as popular methods for unsupervised defect segmentation on image data. Most commonly, this task is performed by thresholding a pixel-wise reconstruction error based on an $\ell^p$ distance. This procedure, however, leads to large residuals whenever the reconstruction encompasses slight localization inaccuracies around edges. It also fails to reveal defective regions that have been visually altered when intensity values stay roughly consistent. We show that these problems prevent these approaches from being applied to complex real-world scenarios and that it cannot be easily avoided by employing more elaborate architectures such as variational or feature matching autoencoders. We propose to use a perceptual loss function based on structural similarity which examines inter-dependencies between local image regions, taking into account luminance, contrast and structural information, instead of simply comparing single pixel values. It achieves significant performance gains on a challenging real-world dataset of nanofibrous materials and a novel dataset of two woven fabrics over the state of the art approaches for unsupervised defect segmentation that use pixel-wise reconstruction error metrics.
Online Photometric Calibration for Auto Exposure Video for Realtime Visual Odometry and SLAM
Oct 05, 2017
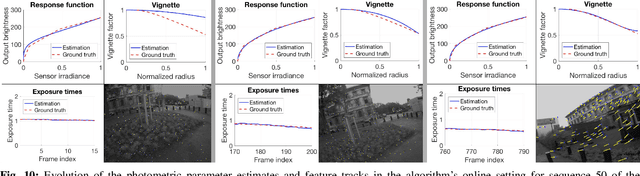


Recent direct visual odometry and SLAM algorithms have demonstrated impressive levels of precision. However, they require a photometric camera calibration in order to achieve competitive results. Hence, the respective algorithm cannot be directly applied to an off-the-shelf-camera or to a video sequence acquired with an unknown camera. In this work we propose a method for online photometric calibration which enables to process auto exposure videos with visual odometry precisions that are on par with those of photometrically calibrated videos. Our algorithm recovers the exposure times of consecutive frames, the camera response function, and the attenuation factors of the sensor irradiance due to vignetting. Gain robust KLT feature tracks are used to obtain scene point correspondences as input to a nonlinear optimization framework. We show that our approach can reliably calibrate arbitrary video sequences by evaluating it on datasets for which full photometric ground truth is available. We further show that our calibration can improve the performance of a state-of-the-art direct visual odometry method that works solely on pixel intensities, calibrating for photometric parameters in an online fashion in realtime.