 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders
Paper and Code

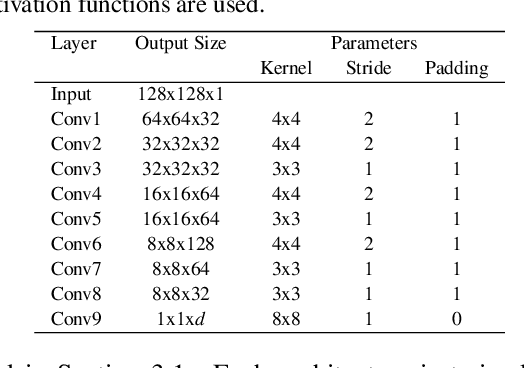
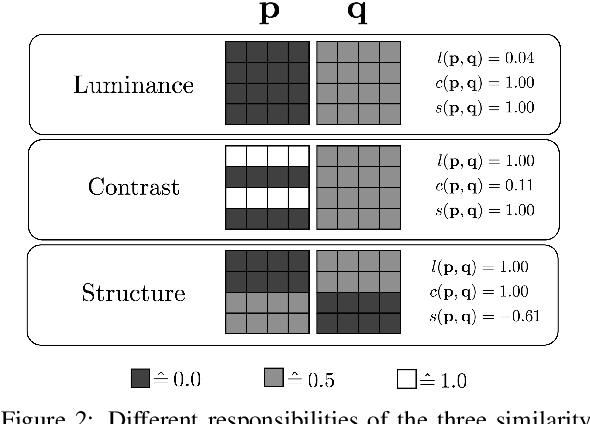

Convolutional autoencoders have emerged as popular methods for unsupervised defect segmentation on image data. Most commonly, this task is performed by thresholding a pixel-wise reconstruction error based on an $\ell^p$ distance. This procedure, however, leads to large residuals whenever the reconstruction encompasses slight localization inaccuracies around edges. It also fails to reveal defective regions that have been visually altered when intensity values stay roughly consistent. We show that these problems prevent these approaches from being applied to complex real-world scenarios and that it cannot be easily avoided by employing more elaborate architectures such as variational or feature matching autoencoders. We propose to use a perceptual loss function based on structural similarity which examines inter-dependencies between local image regions, taking into account luminance, contrast and structural information, instead of simply comparing single pixel values. It achieves significant performance gains on a challenging real-world dataset of nanofibrous materials and a novel dataset of two woven fabrics over the state of the art approaches for unsupervised defect segmentation that use pixel-wise reconstruction error metrics.