 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch strategy in a complex and dynamic environment: the MH370 case
Apr 29, 2020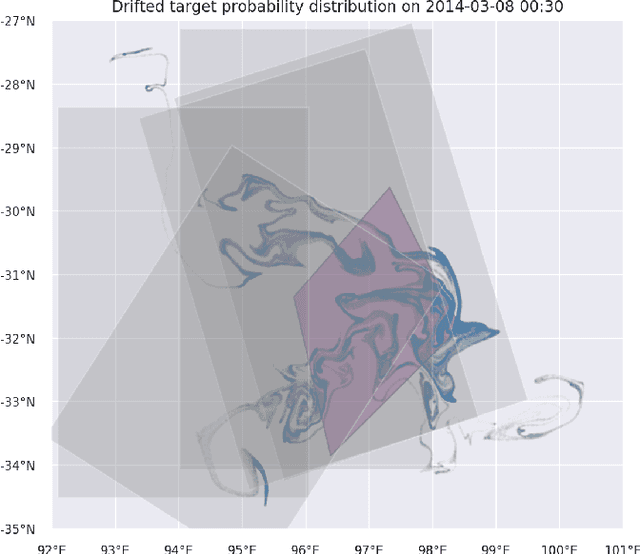
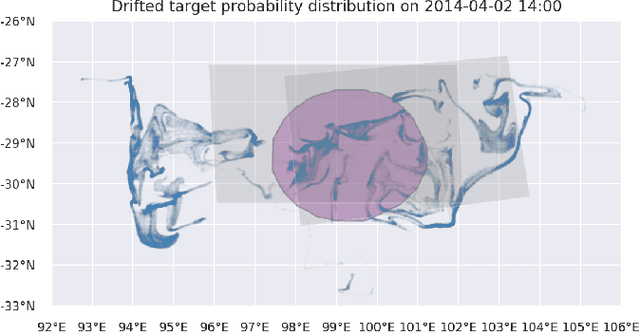
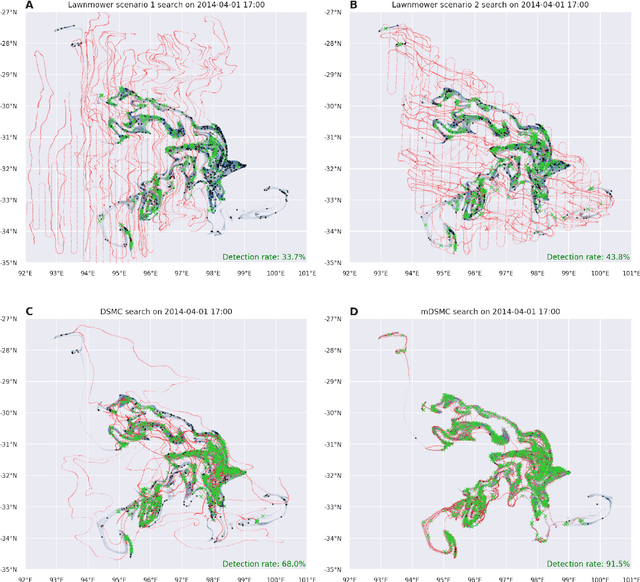
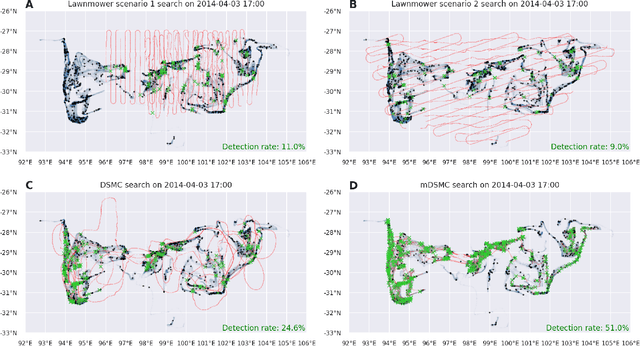
Search and detection of objects on the ocean surface is a challenging task due to the complexity of the drift dynamics and lack of known optimal solutions for the path of the search agents. This challenge was highlighted by the unsuccessful search for Malaysian Flight 370 (MH370) which disappeared on March 8, 2014. In this paper, we propose an improvement of a search algorithm rooted in the ergodic theory of dynamical systems which can accommodate complex geometries and uncertainties of the drifting search areas on the ocean surface. We illustrate the effectiveness of this algorithm in a computational replication of the conducted search for MH370. In comparison to conventional search methods, the proposed algorithm leads to an order of magnitude improvement in success rate over the time period of the actual search operation. Simulations of the proposed search control also indicate that the initial success rate of finding debris increases in the event of delayed search commencement. This is due to the existence of convergence zones in the search area which leads to local aggregation of debris in those zones and hence reduction of the effective size of the area to be searched.
Iterative Reinforcement Learning Based Design of Dynamic Locomotion Skills for Cassie
Mar 22, 2019
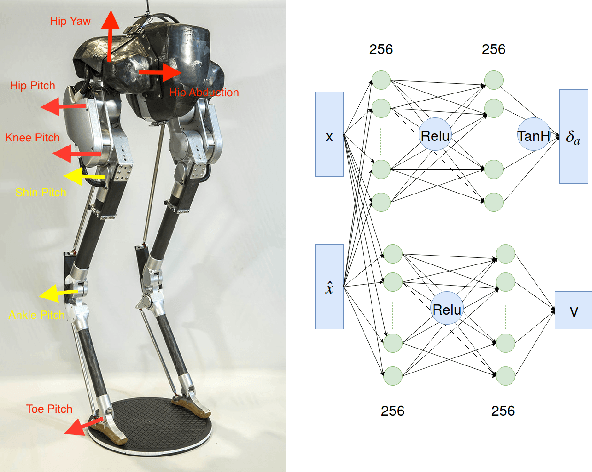
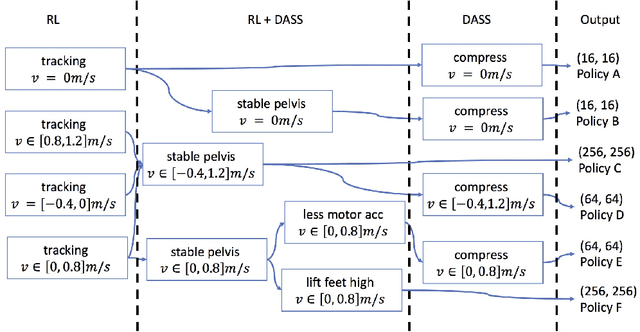
Deep reinforcement learning (DRL) is a promising approach for developing legged locomotion skills. However, the iterative design process that is inevitable in practice is poorly supported by the default methodology. It is difficult to predict the outcomes of changes made to the reward functions, policy architectures, and the set of tasks being trained on. In this paper, we propose a practical method that allows the reward function to be fully redefined on each successive design iteration while limiting the deviation from the previous iteration. We characterize policies via sets of Deterministic Action Stochastic State (DASS) tuples, which represent the deterministic policy state-action pairs as sampled from the states visited by the trained stochastic policy. New policies are trained using a policy gradient algorithm which then mixes RL-based policy gradients with gradient updates defined by the DASS tuples. The tuples also allow for robust policy distillation to new network architectures. We demonstrate the effectiveness of this iterative-design approach on the bipedal robot Cassie, achieving stable walking with different gait styles at various speeds. We demonstrate the successful transfer of policies learned in simulation to the physical robot without any dynamics randomization, and that variable-speed walking policies for the physical robot can be represented by a small dataset of 5-10k tuples.
Feedback Control For Cassie With Deep Reinforcement Learning
Jul 27, 2018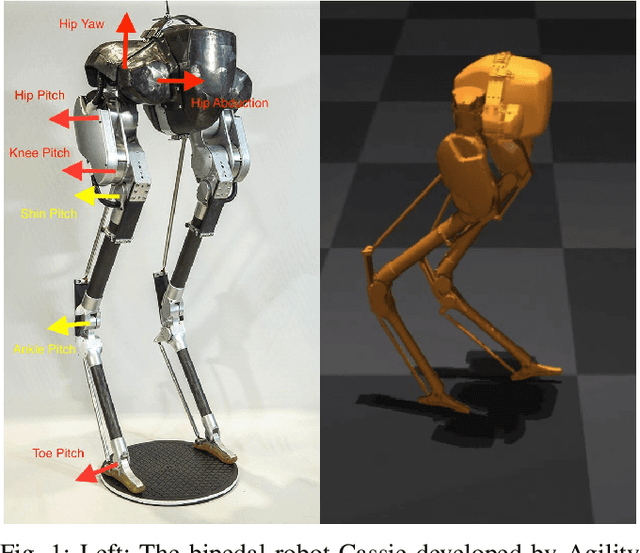
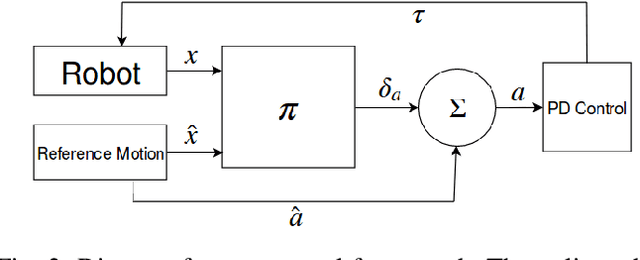
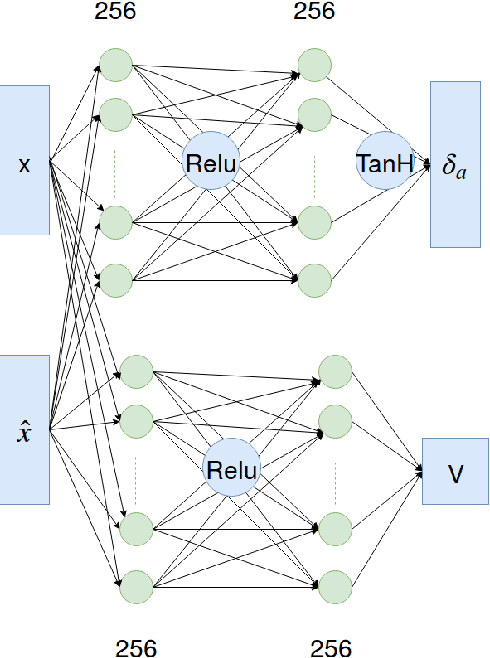
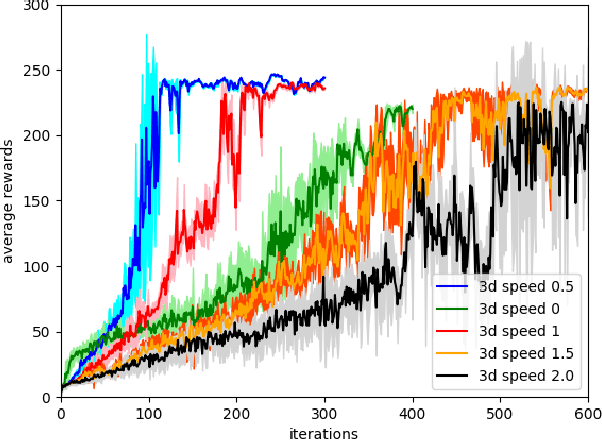
Bipedal locomotion skills are challenging to develop. Control strategies often use local linearization of the dynamics in conjunction with reduced-order abstractions to yield tractable solutions. In these model-based control strategies, the controller is often not fully aware of many details, including torque limits, joint limits, and other non-linearities that are necessarily excluded from the control computations for simplicity. Deep reinforcement learning (DRL) offers a promising model-free approach for controlling bipedal locomotion which can more fully exploit the dynamics. However, current results in the machine learning literature are often based on ad-hoc simulation models that are not based on corresponding hardware. Thus it remains unclear how well DRL will succeed on realizable bipedal robots. In this paper, we demonstrate the effectiveness of DRL using a realistic model of Cassie, a bipedal robot. By formulating a feedback control problem as finding the optimal policy for a Markov Decision Process, we are able to learn robust walking controllers that imitate a reference motion with DRL. Controllers for different walking speeds are learned by imitating simple time-scaled versions of the original reference motion. Controller robustness is demonstrated through several challenging tests, including sensory delay, walking blindly on irregular terrain and unexpected pushes at the pelvis. We also show we can interpolate between individual policies and that robustness can be improved with an interpolated policy.