 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Reinforcement Learning Based Design of Dynamic Locomotion Skills for Cassie
Paper and Code
Mar 22, 2019
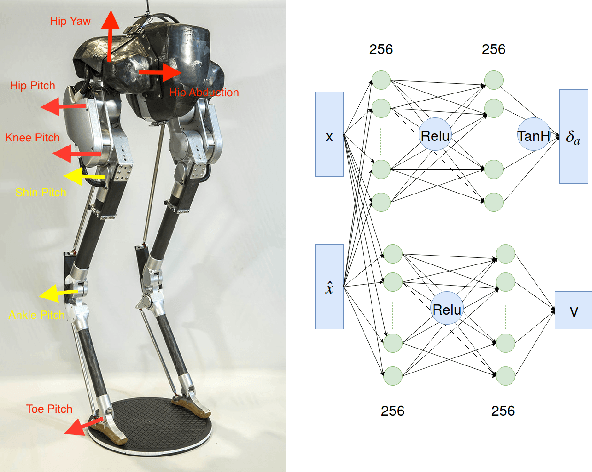
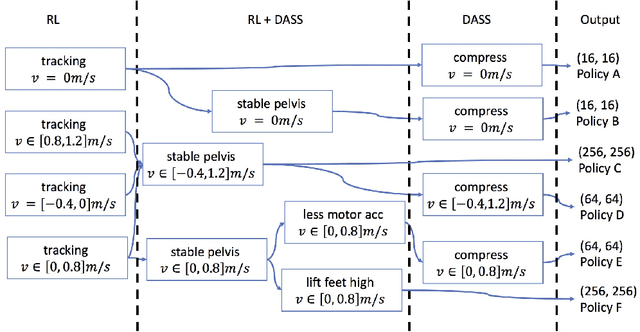
Deep reinforcement learning (DRL) is a promising approach for developing legged locomotion skills. However, the iterative design process that is inevitable in practice is poorly supported by the default methodology. It is difficult to predict the outcomes of changes made to the reward functions, policy architectures, and the set of tasks being trained on. In this paper, we propose a practical method that allows the reward function to be fully redefined on each successive design iteration while limiting the deviation from the previous iteration. We characterize policies via sets of Deterministic Action Stochastic State (DASS) tuples, which represent the deterministic policy state-action pairs as sampled from the states visited by the trained stochastic policy. New policies are trained using a policy gradient algorithm which then mixes RL-based policy gradients with gradient updates defined by the DASS tuples. The tuples also allow for robust policy distillation to new network architectures. We demonstrate the effectiveness of this iterative-design approach on the bipedal robot Cassie, achieving stable walking with different gait styles at various speeds. We demonstrate the successful transfer of policies learned in simulation to the physical robot without any dynamics randomization, and that variable-speed walking policies for the physical robot can be represented by a small dataset of 5-10k tuples.