 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOEM: Cross-Modal Embedding for MetaCell Identification
Jul 25, 2022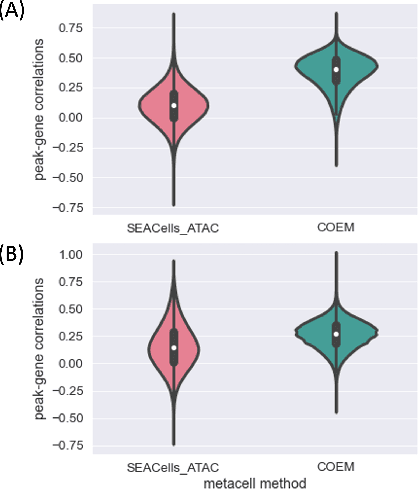

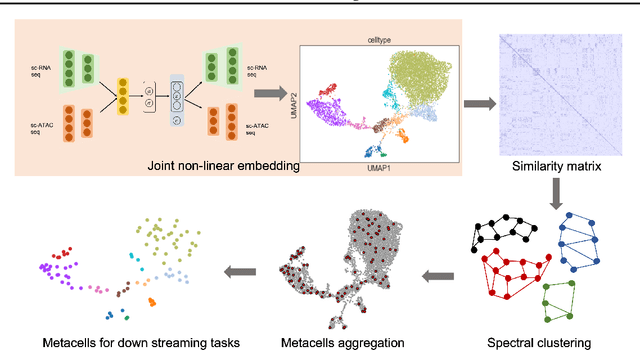
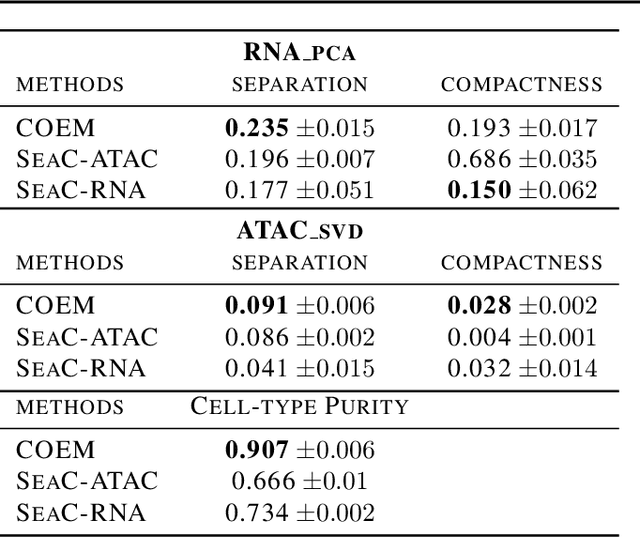
Metacells are disjoint and homogeneous groups of single-cell profiles, representing discrete and highly granular cell states. Existing metacell algorithms tend to use only one modality to infer metacells, even though single-cell multi-omics datasets profile multiple molecular modalities within the same cell. Here, we present \textbf{C}ross-M\textbf{O}dal \textbf{E}mbedding for \textbf{M}etaCell Identification (COEM), which utilizes an embedded space leveraging the information of both scATAC-seq and scRNA-seq to perform aggregation, balancing the trade-off between fine resolution and sufficient sequencing coverage. COEM outperforms the state-of-the-art method SEACells by efficiently identifying accurate and well-separated metacells across datasets with continuous and discrete cell types. Furthermore, COEM significantly improves peak-to-gene association analyses, and facilitates complex gene regulatory inference tasks.
A Pipeline for Integrated Theory and Data-Driven Modeling of Genomic and Clinical Data
May 05, 2020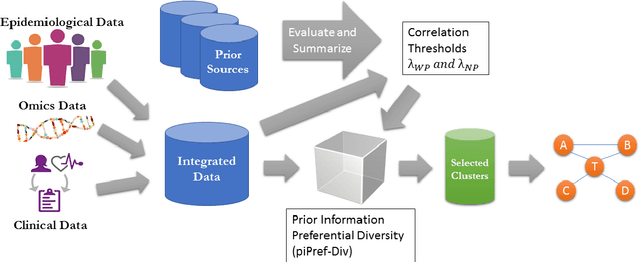
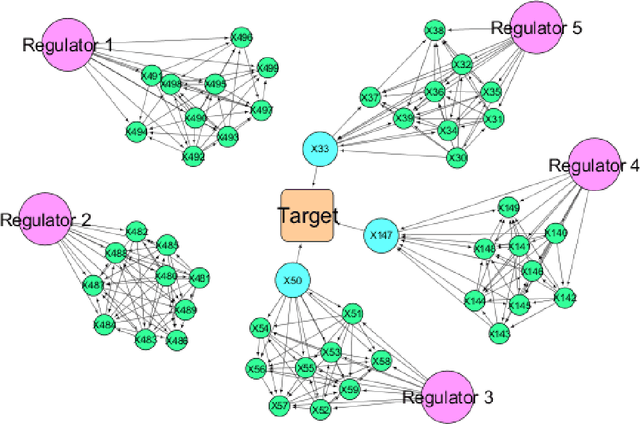
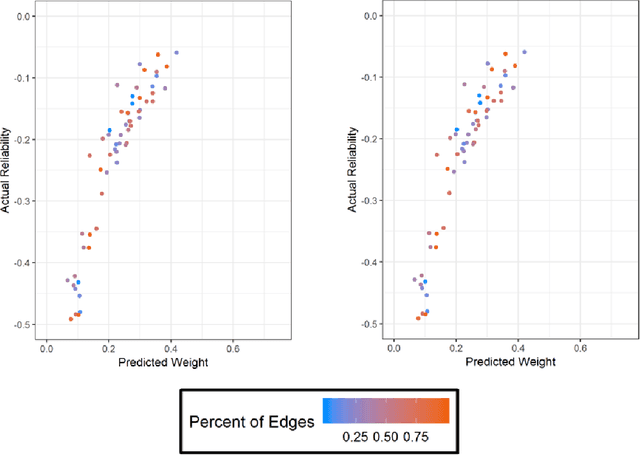
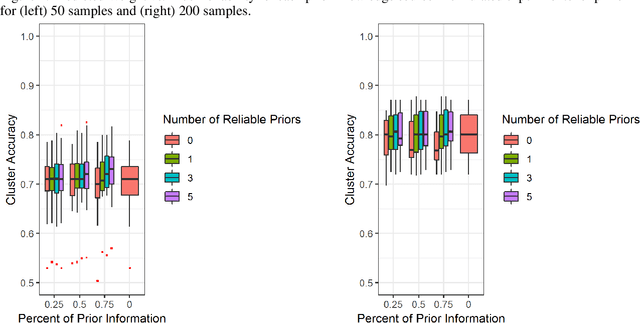
High throughput genome sequencing technologies such as RNA-Seq and Microarray have the potential to transform clinical decision making and biomedical research by enabling high-throughput measurements of the genome at a granular level. However, to truly understand causes of disease and the effects of medical interventions, this data must be integrated with phenotypic, environmental, and behavioral data from individuals. Further, effective knowledge discovery methods that can infer relationships between these data types are required. In this work, we propose a pipeline for knowledge discovery from integrated genomic and clinical data. The pipeline begins with a novel variable selection method, and uses a probabilistic graphical model to understand the relationships between features in the data. We demonstrate how this pipeline can improve breast cancer outcome prediction models, and can provide a biologically interpretable view of sequencing data.
Mixed Graphical Models for Causal Analysis of Multi-modal Variables
Apr 09, 2017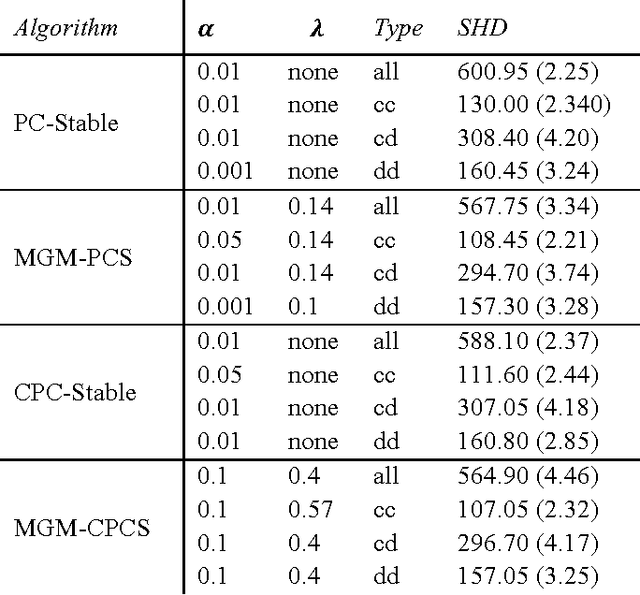
Graphical causal models are an important tool for knowledge discovery because they can represent both the causal relations between variables and the multivariate probability distributions over the data. Once learned, causal graphs can be used for classification, feature selection and hypothesis generation, while revealing the underlying causal network structure and thus allowing for arbitrary likelihood queries over the data. However, current algorithms for learning sparse directed graphs are generally designed to handle only one type of data (continuous-only or discrete-only), which limits their applicability to a large class of multi-modal biological datasets that include mixed type variables. To address this issue, we developed new methods that modify and combine existing methods for finding undirected graphs with methods for finding directed graphs. These hybrid methods are not only faster, but also perform better than the directed graph estimation methods alone for a variety of parameter settings and data set sizes. Here, we describe a new conditional independence test for learning directed graphs over mixed data types and we compare performances of different graph learning strategies on synthetic data.