 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pipeline for Integrated Theory and Data-Driven Modeling of Genomic and Clinical Data
Paper and Code
May 05, 2020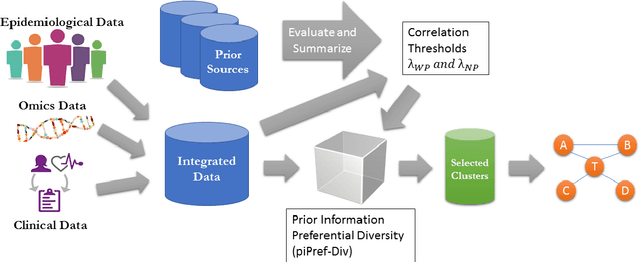
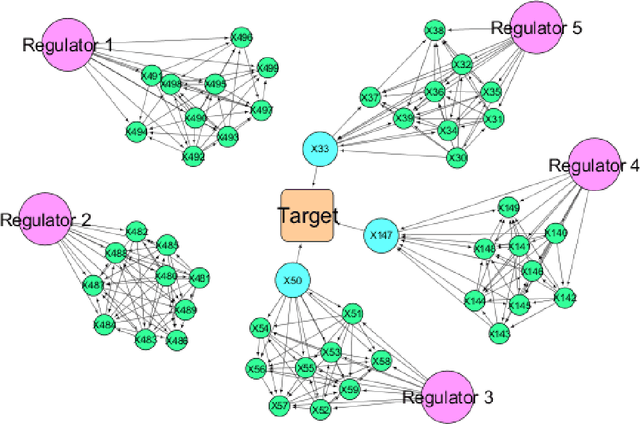
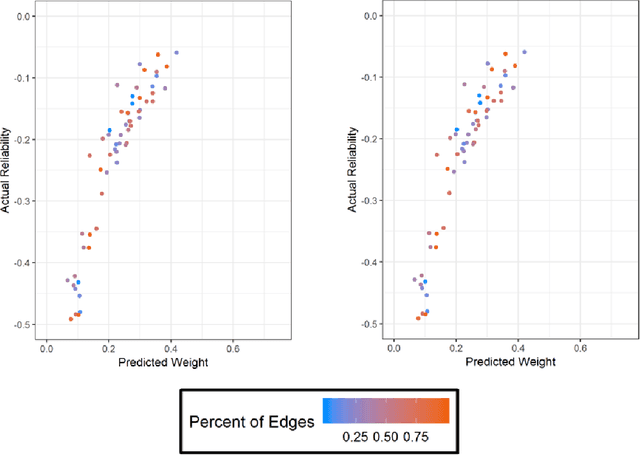
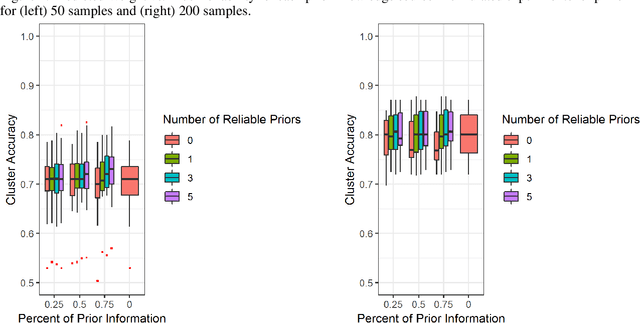
High throughput genome sequencing technologies such as RNA-Seq and Microarray have the potential to transform clinical decision making and biomedical research by enabling high-throughput measurements of the genome at a granular level. However, to truly understand causes of disease and the effects of medical interventions, this data must be integrated with phenotypic, environmental, and behavioral data from individuals. Further, effective knowledge discovery methods that can infer relationships between these data types are required. In this work, we propose a pipeline for knowledge discovery from integrated genomic and clinical data. The pipeline begins with a novel variable selection method, and uses a probabilistic graphical model to understand the relationships between features in the data. We demonstrate how this pipeline can improve breast cancer outcome prediction models, and can provide a biologically interpretable view of sequencing data.