 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Size and Microscope Feature Extraction and Classification in Oral Cancer: Enhanced Convolution Neural Network
Aug 06, 2022Background and Aim: Over-fitting issue has been the reason behind deep learning technology not being successfully implemented in oral cancer images classification. The aims of this research were reducing overfitting for accurately producing the required dimension reduction feature map through Deep Learning algorithm using Convolutional Neural Network. Methodology: The proposed system consists of Enhanced Convolutional Neural Network that uses an autoencoder technique to increase the efficiency of the feature extraction process and compresses information. In this technique, unpooling and deconvolution is done to generate the input data to minimize the difference between input and output data. Moreover, it extracts characteristic features from the input data set to regenerate input data from those features by learning a network to reduce overfitting. Results: Different accuracy and processing time value is achieved while using different sample image group of Confocal Laser Endomicroscopy (CLE) images. The results showed that the proposed solution is better than the current system. Moreover, the proposed system has improved the classification accuracy by 5~ 5.5% on average and reduced the average processing time by 20 ~ 30 milliseconds. Conclusion: The proposed system focuses on the accurate classification of oral cancer cells of different anatomical locations from the CLE images. Finally, this study enhances the accuracy and processing time using the autoencoder method that solves the overfitting problem.
* 21 pages
Deep Learning Neural Network for Lung Cancer Classification: Enhanced Optimization Function
Aug 05, 2022Background and Purpose: Convolutional neural network is widely used for image recognition in the medical area at nowadays. However, overall accuracy in predicting lung tumor is low and the processing time is high as the error occurred while reconstructing the CT image. The aim of this work is to increase the overall prediction accuracy along with reducing processing time by using multispace image in pooling layer of convolution neural network. Methodology: The proposed method has the autoencoder system to improve the overall accuracy, and to predict lung cancer by using multispace image in pooling layer of convolution neural network and Adam Algorithm for optimization. First, the CT images were pre-processed by feeding image to the convolution filter and down sampled by using max pooling. Then, features are extracted using the autoencoder model based on convolutional neural network and multispace image reconstruction technique is used to reduce error while reconstructing the image which then results improved accuracy to predict lung nodule. Finally, the reconstructed images are taken as input for SoftMax classifier to classify the CT images. Results: The state-of-art and proposed solutions were processed in Python Tensor Flow and It provides significant increase in accuracy in classification of lung cancer to 99.5 from 98.9 and decrease in processing time from 10 frames/second to 12 seconds/second. Conclusion: The proposed solution provides high classification accuracy along with less processing time compared to the state of art. For future research, large dataset can be implemented, and low pixel image can be processed to evaluate the classification
* 22pages
A novel solution of deep learning for enhanced support vector machine for predicting the onset of type 2 diabetes
Aug 05, 2022Type 2 Diabetes is one of the most major and fatal diseases known to human beings, where thousands of people are subjected to the onset of Type 2 Diabetes every year. However, the diagnosis and prevention of Type 2 Diabetes are relatively costly in today's scenario; hence, the use of machine learning and deep learning techniques is gaining momentum for predicting the onset of Type 2 Diabetes. This research aims to increase the accuracy and Area Under the Curve (AUC) metric while improving the processing time for predicting the onset of Type 2 Diabetes. The proposed system consists of a deep learning technique that uses the Support Vector Machine (SVM) algorithm along with the Radial Base Function (RBF) along with the Long Short-term Memory Layer (LSTM) for prediction of onset of Type 2 Diabetes. The proposed solution provides an average accuracy of 86.31 % and an average AUC value of 0.8270 or 82.70 %, with an improvement of 3.8 milliseconds in the processing. Radial Base Function (RBF) kernel and the LSTM layer enhance the prediction accuracy and AUC metric from the current industry standard, making it more feasible for practical use without compromising the processing time.
* 18 pages
A Novel Enhanced Convolution Neural Network with Extreme Learning Machine: Facial Emotional Recognition in Psychology Practices
Aug 05, 2022Facial emotional recognition is one of the essential tools used by recognition psychology to diagnose patients. Face and facial emotional recognition are areas where machine learning is excelling. Facial Emotion Recognition in an unconstrained environment is an open challenge for digital image processing due to different environments, such as lighting conditions, pose variation, yaw motion, and occlusions. Deep learning approaches have shown significant improvements in image recognition. However, accuracy and time still need improvements. This research aims to improve facial emotion recognition accuracy during the training session and reduce processing time using a modified Convolution Neural Network Enhanced with Extreme Learning Machine (CNNEELM). The system entails (CNNEELM) improving the accuracy in image registration during the training session. Furthermore, the system recognizes six facial emotions happy, sad, disgust, fear, surprise, and neutral with the proposed CNNEELM model. The study shows that the overall facial emotion recognition accuracy is improved by 2% than the state of art solutions with a modified Stochastic Gradient Descent (SGD) technique. With the Extreme Learning Machine (ELM) classifier, the processing time is brought down to 65ms from 113ms, which can smoothly classify each frame from a video clip at 20fps. With the pre-trained InceptionV3 model, the proposed CNNEELM model is trained with JAFFE, CK+, and FER2013 expression datasets. The simulation results show significant improvements in accuracy and processing time, making the model suitable for the video analysis process. Besides, the study solves the issue of the large processing time required to process the facial images.
* 19 pages
Deep Learning Neural Networks for Emotion Classification from Text: Enhanced Leaky Rectified Linear Unit Activation and Weighted Loss
Mar 04, 2022
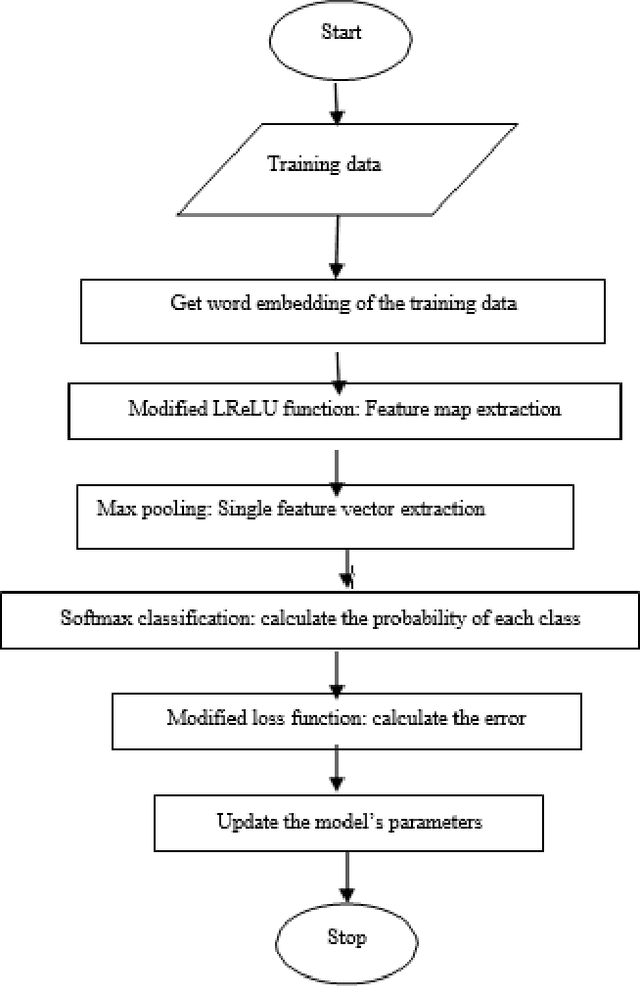
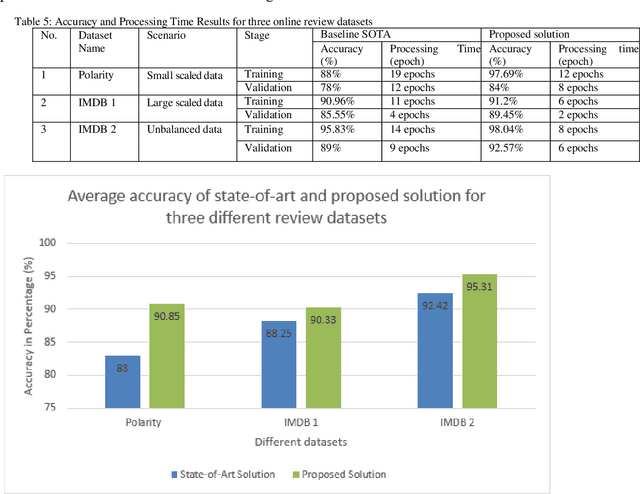
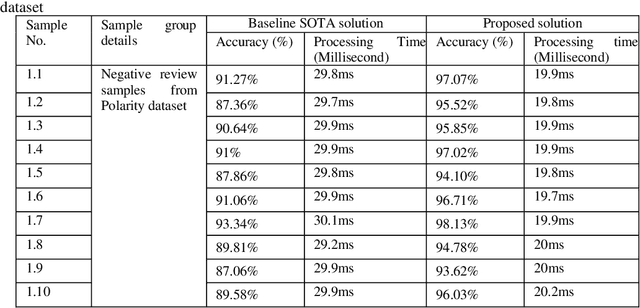
Accurate emotion classification for online reviews is vital for business organizations to gain deeper insights into markets. Although deep learning has been successfully implemented in this area, accuracy and processing time are still major problems preventing it from reaching its full potential. This paper proposes an Enhanced Leaky Rectified Linear Unit activation and Weighted Loss (ELReLUWL) algorithm for enhanced text emotion classification and faster parameter convergence speed. This algorithm includes the definition of the inflection point and the slope for inputs on the left side of the inflection point to avoid gradient saturation. It also considers the weight of samples belonging to each class to compensate for the influence of data imbalance. Convolutional Neural Network (CNN) combined with the proposed algorithm to increase the classification accuracy and decrease the processing time by eliminating the gradient saturation problem and minimizing the negative effect of data imbalance, demonstrated on a binary sentiment problem. The results show that the proposed solution achieves better classification performance in different data scenarios and different review types. The proposed model takes less convergence time to achieve model optimization with seven epochs against the current convergence time of 11.5 epochs on average. The proposed solution improves accuracy and reduces the processing time of text emotion classification. The solution provides an average class accuracy of 96.63% against a current average accuracy of 91.56%. It also provides a processing time of 23.3 milliseconds compared to the current average processing time of 33.2 milliseconds. Finally, this study solves the issues of gradient saturation and data imbalance. It enhances overall average class accuracy and decreases processing time.
* 28 pages
Deep Learning for Sleep Stages Classification: Modified Rectified Linear Unit Activation Function and Modified Orthogonal Weight Initialisation
Feb 18, 2022

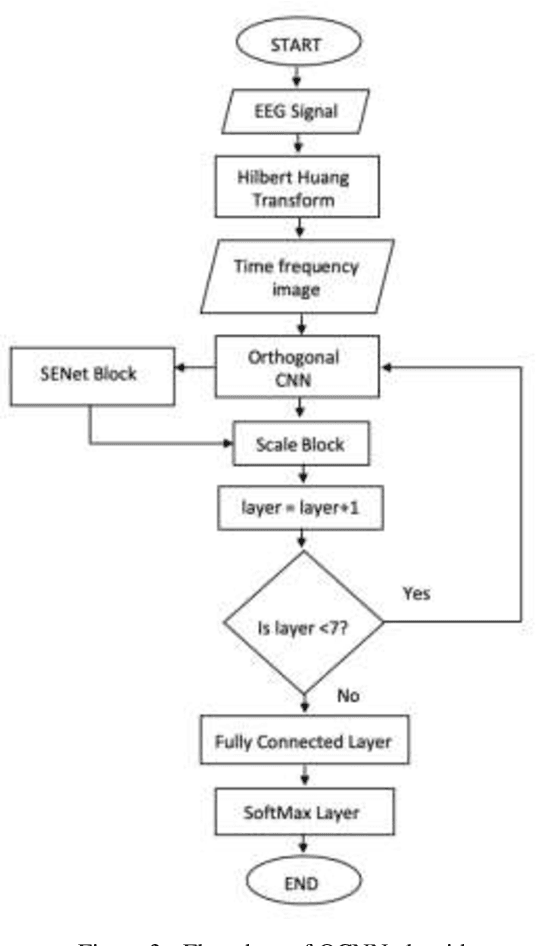

Background and Aim: Each stage of sleep can affect human health, and not getting enough sleep at any stage may lead to sleep disorder like parasomnia, apnea, insomnia, etc. Sleep-related diseases could be diagnosed using Convolutional Neural Network Classifier. However, this classifier has not been successfully implemented into sleep stage classification systems due to high complexity and low accuracy of classification. The aim of this research is to increase the accuracy and reduce the learning time of Convolutional Neural Network Classifier. Methodology: The proposed system used a modified Orthogonal Convolutional Neural Network and a modified Adam optimisation technique to improve the sleep stage classification accuracy and reduce the gradient saturation problem that occurs due to sigmoid activation function. The proposed system uses Leaky Rectified Linear Unit (ReLU) instead of sigmoid activation function as an activation function. Results: The proposed system called Enhanced Sleep Stage Classification system (ESSC) used six different databases for training and testing the proposed model on the different sleep stages. These databases are University College Dublin database (UCD), Beth Israel Deaconess Medical Center MIT database (MIT-BIH), Sleep European Data Format (EDF), Sleep EDF Extended, Montreal Archive of Sleep Studies (MASS), and Sleep Heart Health Study (SHHS). Our results show that the gradient saturation problem does not exist anymore. The modified Adam optimiser helps to reduce the noise which in turn result in faster convergence time. Conclusion: The convergence speed of ESSC is increased along with better classification accuracy compared to the state of art solution.
* 20 pages
Generative Adversarial Network (GAN) and Enhanced Root Mean Square Error (ERMSE): Deep Learning for Stock Price Movement Prediction
Nov 30, 2021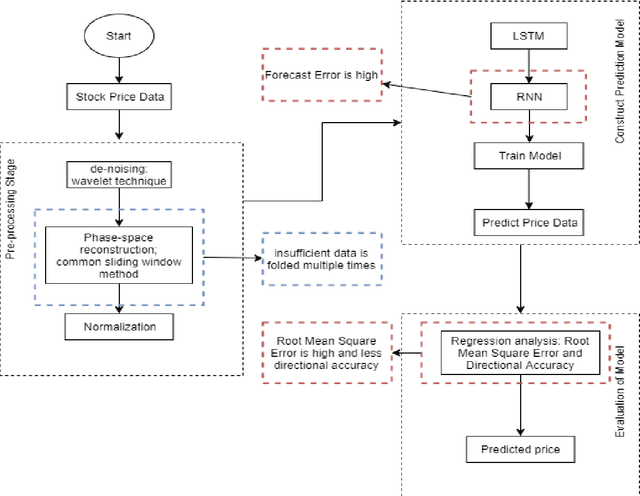
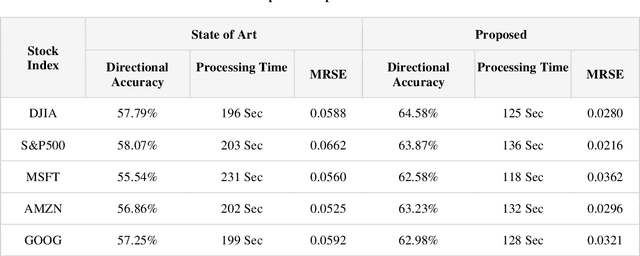
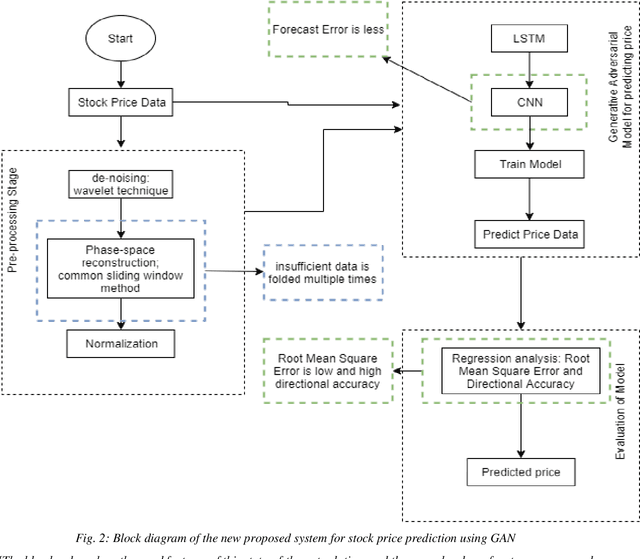

The prediction of stock price movement direction is significant in financial circles and academic. Stock price contains complex, incomplete, and fuzzy information which makes it an extremely difficult task to predict its development trend. Predicting and analysing financial data is a nonlinear, time-dependent problem. With rapid development in machine learning and deep learning, this task can be performed more effectively by a purposely designed network. This paper aims to improve prediction accuracy and minimizing forecasting error loss through deep learning architecture by using Generative Adversarial Networks. It was proposed a generic model consisting of Phase-space Reconstruction (PSR) method for reconstructing price series and Generative Adversarial Network (GAN) which is a combination of two neural networks which are Long Short-Term Memory (LSTM) as Generative model and Convolutional Neural Network (CNN) as Discriminative model for adversarial training to forecast the stock market. LSTM will generate new instances based on historical basic indicators information and then CNN will estimate whether the data is predicted by LSTM or is real. It was found that the Generative Adversarial Network (GAN) has performed well on the enhanced root mean square error to LSTM, as it was 4.35% more accurate in predicting the direction and reduced processing time and RMSE by 78 secs and 0.029, respectively. This study provides a better result in the accuracy of the stock index. It seems that the proposed system concentrates on minimizing the root mean square error and processing time and improving the direction prediction accuracy, and provides a better result in the accuracy of the stock index.
A Novel Solution of an Elastic Net Regularization for Dementia Knowledge Discovery using Deep Learning
Aug 21, 2021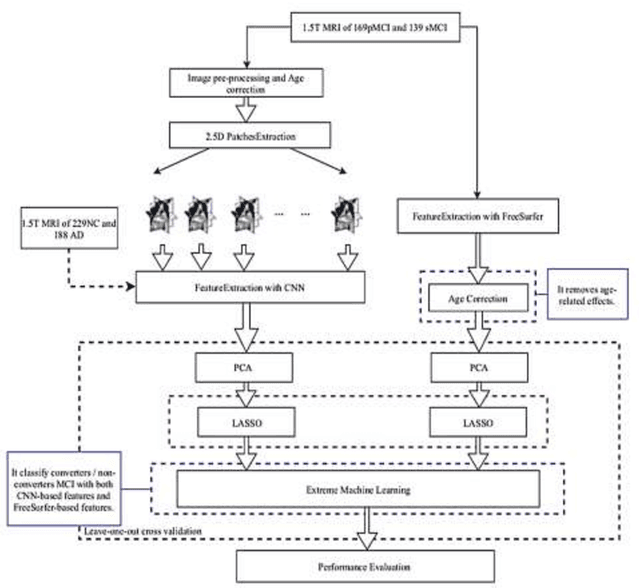

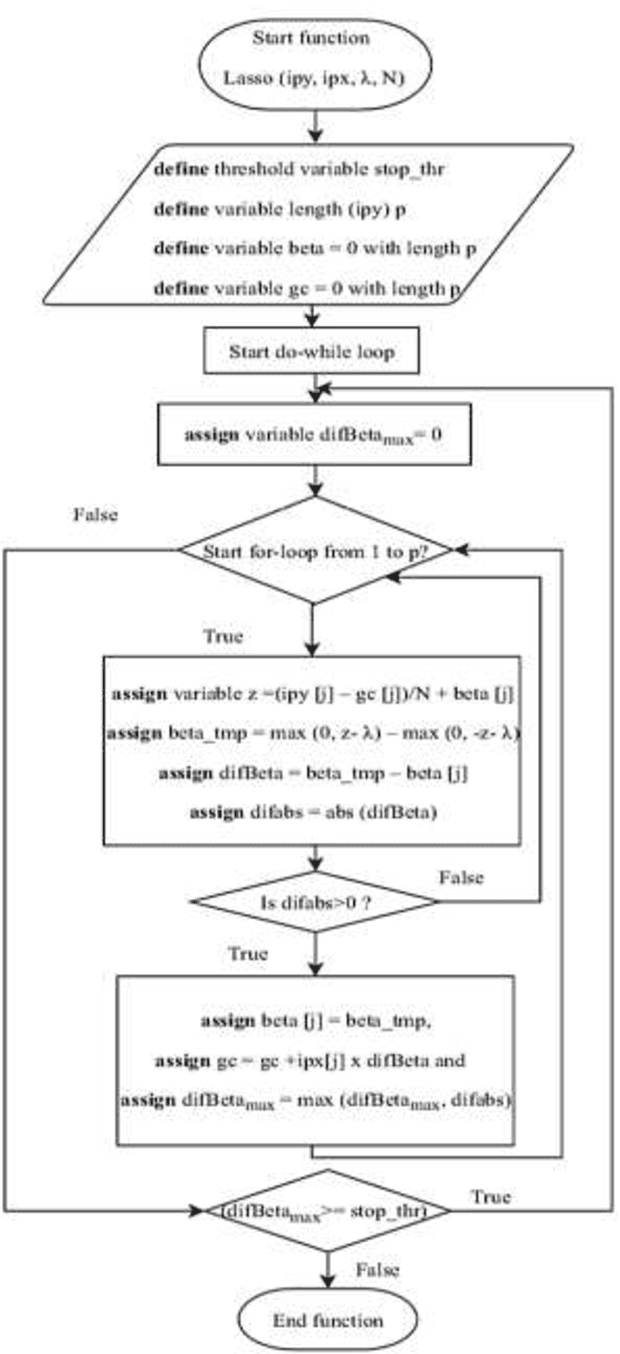
Background and Aim: Accurate classification of Magnetic Resonance Images (MRI) is essential to accurately predict Mild Cognitive Impairment (MCI) to Alzheimer's Disease (AD) conversion. Meanwhile, deep learning has been successfully implemented to classify and predict dementia disease. However, the accuracy of MRI image classification is low. This paper aims to increase the accuracy and reduce the processing time of classification through Deep Learning Architecture by using Elastic Net Regularization in Feature Selection. Methodology: The proposed system consists of Convolutional Neural Network (CNN) to enhance the accuracy of classification and prediction by using Elastic Net Regularization. Initially, the MRI images are fed into CNN for features extraction through convolutional layers alternate with pooling layers, and then through a fully connected layer. After that, the features extracted are subjected to Principle Component Analysis (PCA) and Elastic Net Regularization for feature selection. Finally, the selected features are used as an input to Extreme Machine Learning (EML) for the classification of MRI images. Results: The result shows that the accuracy of the proposed solution is better than the current system. In addition to that, the proposed method has improved the classification accuracy by 5% on average and reduced the processing time by 30 ~ 40 seconds on average. Conclusion: The proposed system is focused on improving the accuracy and processing time of MCI converters/non-converters classification. It consists of features extraction, feature selection, and classification using CNN, FreeSurfer, PCA, Elastic Net, Extreme Machine Learning. Finally, this study enhances the accuracy and the processing time by using Elastic Net Regularization, which provides important selected features for classification.
* 20 pages
A Review-based Taxonomy for Secure Health Care Monitoring: Wireless Smart Cameras
Jul 05, 2021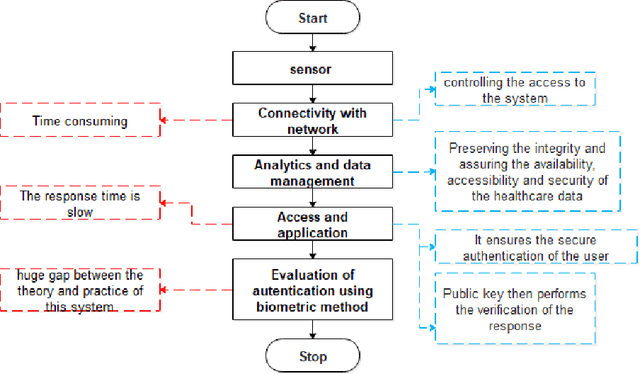
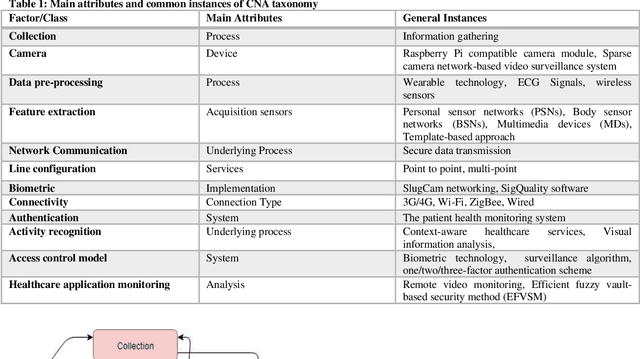
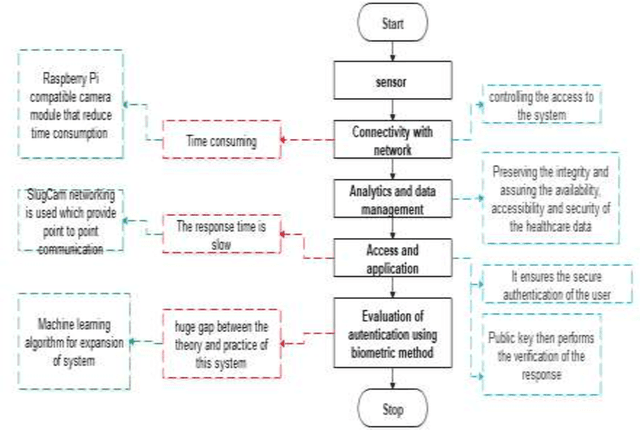
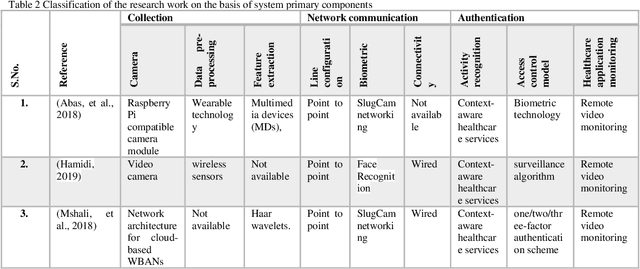
Health records data security is one of the main challenges in e-health systems. Authentication is one of the essential security services to support the stored data confidentiality, integrity, and availability. This research focuses on the secure storage of patient and medical records in the healthcare sector where data security and unauthorized access is an ongoing issue. A potential solution comes from biometrics, although their use may be time-consuming and can slow down data retrieval. This research aims to overcome these challenges and enhance data access control in the healthcare sector through the addition of biometrics in the form of fingerprints. The proposed model for application in the healthcare sector consists of Collection, Network communication, and Authentication (CNA) using biometrics, which replaces an existing password-based access control method. A sensor then collects data and by using a network (wireless or Zig-bee), a connection is established, after connectivity analytics and data management work which processes and aggregate the data. Subsequently, access is granted to authenticated users of the application. This IoT-based biometric authentication system facilitates effective recognition and ensures confidentiality, integrity, and reliability of patients, records and other sensitive data. The proposed solution provides reliable access to healthcare data and enables secure access through the process of user and device authentication. The proposed model has been developed for access control to data through the authentication of users in healthcare to reduce data manipulation or theft.
* 29 pages
Deep Learning for Vision-Based Fall Detection System: Enhanced Optical Dynamic Flow
Mar 18, 2021Accurate fall detection for the assistance of older people is crucial to reduce incidents of deaths or injuries due to falls. Meanwhile, a vision-based fall detection system has shown some significant results to detect falls. Still, numerous challenges need to be resolved. The impact of deep learning has changed the landscape of the vision-based system, such as action recognition. The deep learning technique has not been successfully implemented in vision-based fall detection systems due to the requirement of a large amount of computation power and the requirement of a large amount of sample training data. This research aims to propose a vision-based fall detection system that improves the accuracy of fall detection in some complex environments such as the change of light condition in the room. Also, this research aims to increase the performance of the pre-processing of video images. The proposed system consists of the Enhanced Dynamic Optical Flow technique that encodes the temporal data of optical flow videos by the method of rank pooling, which thereby improves the processing time of fall detection and improves the classification accuracy in dynamic lighting conditions. The experimental results showed that the classification accuracy of the fall detection improved by around 3% and the processing time by 40 to 50ms. The proposed system concentrates on decreasing the processing time of fall detection and improving classification accuracy. Meanwhile, it provides a mechanism for summarizing a video into a single image by using a dynamic optical flow technique, which helps to increase the performance of image pre-processing steps.
* 16 pages