 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial self-supervised Peak Learning and correlation-based Evaluation of peak picking in Mass Spectrometry Imaging
Mar 11, 2026Mass spectrometry imaging (MSI) enables label-free visualization of molecular distributions across tissue samples but generates large and complex datasets that require effective peak picking to reduce data size while preserving meaningful biological information. Existing peak picking approaches perform inconsistently across heterogeneous datasets, and their evaluation is often limited to synthetic data or manually selected ion images that do not fully represent real-world challenges in MSI. To address these limitations, we propose an autoencoder-based spatial self-supervised peak learning neural network that selects spatially structured peaks by learning an attention mask leveraging both spatial and spectral information. We further introduce an evaluation procedure based on expert-annotated segmentation masks, allowing a more representative and spatially grounded assessment of peak picking performance. We evaluate our approach on four diverse public MSI datasets using our proposed evaluation procedure. Our approach consistently outperforms state-of-the-art peak picking methods by selecting spatially structured peaks, thus demonstrating its efficacy. These results highlight the value of our spatial self-supervised network in comparison to contemporary state-of-the-art methods. The evaluation procedure can be readily applied to new MSI datasets, thereby providing a consistent and robust framework for the comparison of spatially structured peak picking methods across different datasets.
D-PLS: Decoupled Semantic Segmentation for 4D-Panoptic-LiDAR-Segmentation
Jan 27, 2025



This paper introduces a novel approach to 4D Panoptic LiDAR Segmentation that decouples semantic and instance segmentation, leveraging single-scan semantic predictions as prior information for instance segmentation. Our method D-PLS first performs single-scan semantic segmentation and aggregates the results over time, using them to guide instance segmentation. The modular design of D-PLS allows for seamless integration on top of any semantic segmentation architecture, without requiring architectural changes or retraining. We evaluate our approach on the SemanticKITTI dataset, where it demonstrates significant improvements over the baseline in both classification and association tasks, as measured by the LiDAR Segmentation and Tracking Quality (LSTQ) metric. Furthermore, we show that our decoupled architecture not only enhances instance prediction but also surpasses the baseline due to advancements in single-scan semantic segmentation.
Classifier Ensemble for Efficient Uncertainty Calibration of Deep Neural Networks for Image Classification
Jan 17, 2025



This paper investigates novel classifier ensemble techniques for uncertainty calibration applied to various deep neural networks for image classification. We evaluate both accuracy and calibration metrics, focusing on Expected Calibration Error (ECE) and Maximum Calibration Error (MCE). Our work compares different methods for building simple yet efficient classifier ensembles, including majority voting and several metamodel-based approaches. Our evaluation reveals that while state-of-the-art deep neural networks for image classification achieve high accuracy on standard datasets, they frequently suffer from significant calibration errors. Basic ensemble techniques like majority voting provide modest improvements, while metamodel-based ensembles consistently reduce ECE and MCE across all architectures. Notably, the largest of our compared metamodels demonstrate the most substantial calibration improvements, with minimal impact on accuracy. Moreover, classifier ensembles with metamodels outperform traditional model ensembles in calibration performance, while requiring significantly fewer parameters. In comparison to traditional post-hoc calibration methods, our approach removes the need for a separate calibration dataset. These findings underscore the potential of our proposed metamodel-based classifier ensembles as an efficient and effective approach to improving model calibration, thereby contributing to more reliable deep learning systems.
Boosting Few-Shot Detection with Large Language Models and Layout-to-Image Synthesis
Oct 09, 2024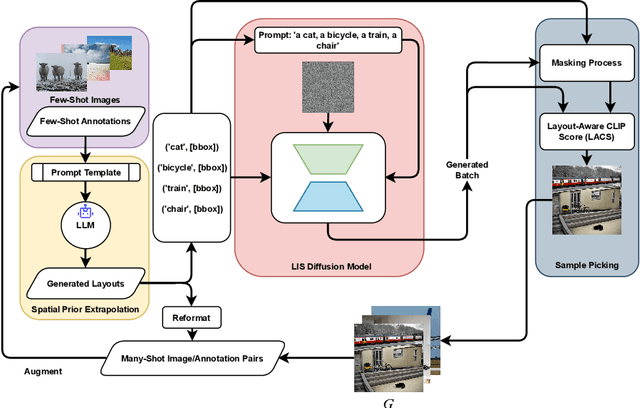

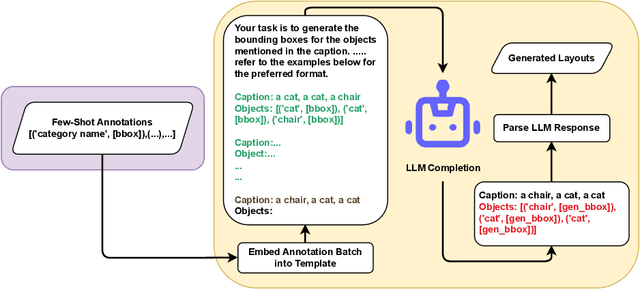

Recent advancements in diffusion models have enabled a wide range of works exploiting their ability to generate high-volume, high-quality data for use in various downstream tasks. One subclass of such models, dubbed Layout-to-Image Synthesis (LIS), learns to generate images conditioned on a spatial layout (bounding boxes, masks, poses, etc.) and has shown a promising ability to generate realistic images, albeit with limited layout-adherence. Moreover, the question of how to effectively transfer those models for scalable augmentation of few-shot detection data remains unanswered. Thus, we propose a collaborative framework employing a Large Language Model (LLM) and an LIS model for enhancing few-shot detection beyond state-of-the-art generative augmentation approaches. We leverage LLM's reasoning ability to extrapolate the spatial prior of the annotation space by generating new bounding boxes given only a few example annotations. Additionally, we introduce our novel layout-aware CLIP score for sample ranking, enabling tight coupling between generated layouts and images. Significant improvements on COCO few-shot benchmarks are observed. With our approach, a YOLOX-S baseline is boosted by more than 140%, 50%, 35% in mAP on the COCO 5-,10-, and 30-shot settings, respectively.
GenFormer -- Generated Images are All You Need to Improve Robustness of Transformers on Small Datasets
Aug 27, 2024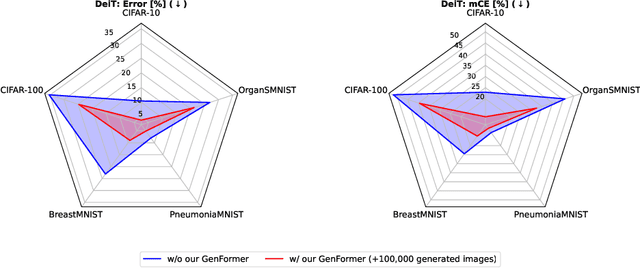
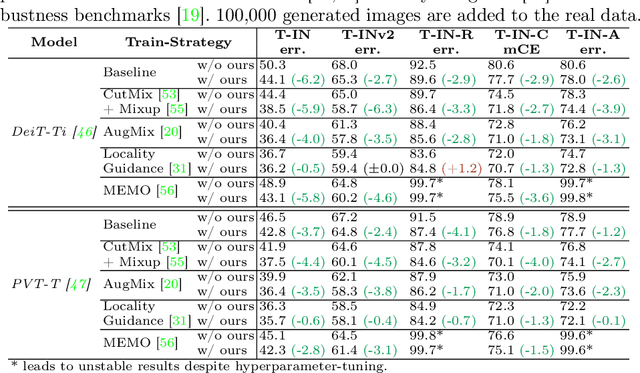
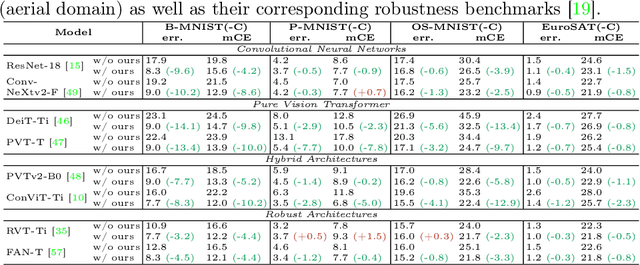
Recent studies showcase the competitive accuracy of Vision Transformers (ViTs) in relation to Convolutional Neural Networks (CNNs), along with their remarkable robustness. However, ViTs demand a large amount of data to achieve adequate performance, which makes their application to small datasets challenging, falling behind CNNs. To overcome this, we propose GenFormer, a data augmentation strategy utilizing generated images, thereby improving transformer accuracy and robustness on small-scale image classification tasks. In our comprehensive evaluation we propose Tiny ImageNetV2, -R, and -A as new test set variants of Tiny ImageNet by transferring established ImageNet generalization and robustness benchmarks to the small-scale data domain. Similarly, we introduce MedMNIST-C and EuroSAT-C as corrupted test set variants of established fine-grained datasets in the medical and aerial domain. Through a series of experiments conducted on small datasets of various domains, including Tiny ImageNet, CIFAR, EuroSAT and MedMNIST datasets, we demonstrate the synergistic power of our method, in particular when combined with common train and test time augmentations, knowledge distillation, and architectural design choices. Additionally, we prove the effectiveness of our approach under challenging conditions with limited training data, demonstrating significant improvements in both accuracy and robustness, bridging the gap between CNNs and ViTs in the small-scale dataset domain.
360$^\circ$ from a Single Camera: A Few-Shot Approach for LiDAR Segmentation
Sep 12, 2023



Deep learning applications on LiDAR data suffer from a strong domain gap when applied to different sensors or tasks. In order for these methods to obtain similar accuracy on different data in comparison to values reported on public benchmarks, a large scale annotated dataset is necessary. However, in practical applications labeled data is costly and time consuming to obtain. Such factors have triggered various research in label-efficient methods, but a large gap remains to their fully-supervised counterparts. Thus, we propose ImageTo360, an effective and streamlined few-shot approach to label-efficient LiDAR segmentation. Our method utilizes an image teacher network to generate semantic predictions for LiDAR data within a single camera view. The teacher is used to pretrain the LiDAR segmentation student network, prior to optional fine-tuning on 360$^\circ$ data. Our method is implemented in a modular manner on the point level and as such is generalizable to different architectures. We improve over the current state-of-the-art results for label-efficient methods and even surpass some traditional fully-supervised segmentation networks.
Transformer-based Detection of Microorganisms on High-Resolution Petri Dish Images
Aug 21, 2023



Many medical or pharmaceutical processes have strict guidelines regarding continuous hygiene monitoring. This often involves the labor-intensive task of manually counting microorganisms in Petri dishes by trained personnel. Automation attempts often struggle due to major challenges: significant scaling differences, low separation, low contrast, etc. To address these challenges, we introduce AttnPAFPN, a high-resolution detection pipeline that leverages a novel transformer variation, the efficient-global self-attention mechanism. Our streamlined approach can be easily integrated in almost any multi-scale object detection pipeline. In a comprehensive evaluation on the publicly available AGAR dataset, we demonstrate the superior accuracy of our network over the current state-of-the-art. In order to demonstrate the task-independent performance of our approach, we perform further experiments on COCO and LIVECell datasets.
Light-Weight Vision Transformer with Parallel Local and Global Self-Attention
Jul 18, 2023



While transformer architectures have dominated computer vision in recent years, these models cannot easily be deployed on hardware with limited resources for autonomous driving tasks that require real-time-performance. Their computational complexity and memory requirements limits their use, especially for applications with high-resolution inputs. In our work, we redesign the powerful state-of-the-art Vision Transformer PLG-ViT to a much more compact and efficient architecture that is suitable for such tasks. We identify computationally expensive blocks in the original PLG-ViT architecture and propose several redesigns aimed at reducing the number of parameters and floating-point operations. As a result of our redesign, we are able to reduce PLG-ViT in size by a factor of 5, with a moderate drop in performance. We propose two variants, optimized for the best trade-off between parameter count to runtime as well as parameter count to accuracy. With only 5 million parameters, we achieve 79.5$\%$ top-1 accuracy on the ImageNet-1K classification benchmark. Our networks demonstrate great performance on general vision benchmarks like COCO instance segmentation. In addition, we conduct a series of experiments, demonstrating the potential of our approach in solving various tasks specifically tailored to the challenges of autonomous driving and transportation.
Multitask Network for Joint Object Detection, Semantic Segmentation and Human Pose Estimation in Vehicle Occupancy Monitoring
May 03, 2022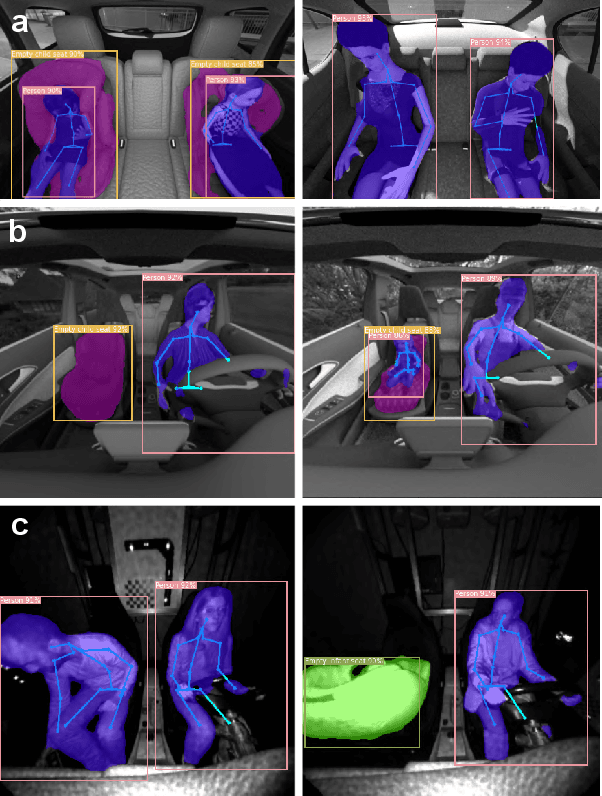
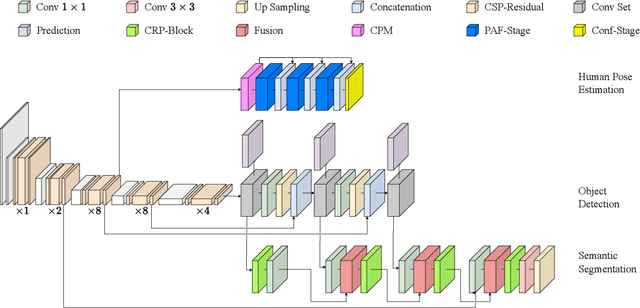


In order to ensure safe autonomous driving, precise information about the conditions in and around the vehicle must be available. Accordingly, the monitoring of occupants and objects inside the vehicle is crucial. In the state-of-the-art, single or multiple deep neural networks are used for either object recognition, semantic segmentation, or human pose estimation. In contrast, we propose our Multitask Detection, Segmentation and Pose Estimation Network (MDSP) -- the first multitask network solving all these three tasks jointly in the area of occupancy monitoring. Due to the shared architecture, memory and computing costs can be saved while achieving higher accuracy. Furthermore, our architecture allows a flexible combination of the three mentioned tasks during a simple end-to-end training. We perform comprehensive evaluations on the public datasets SVIRO and TiCaM in order to demonstrate the superior performance.