 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenFormer -- Generated Images are All You Need to Improve Robustness of Transformers on Small Datasets
Aug 27, 2024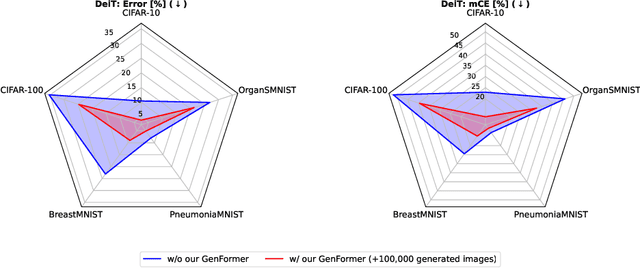
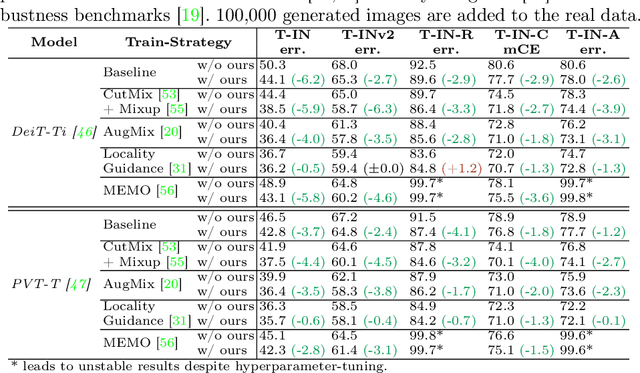
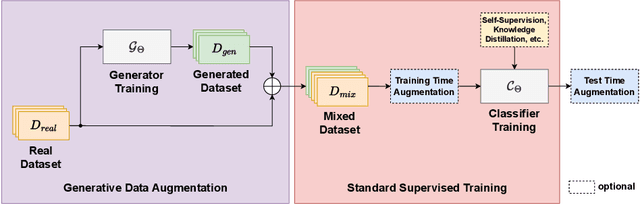
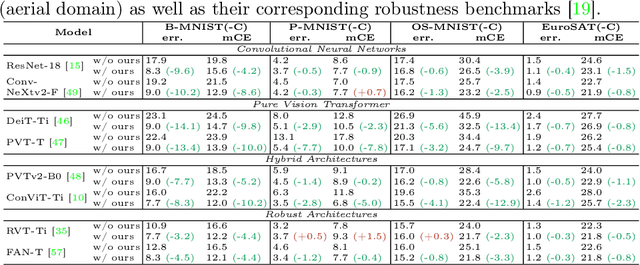
Recent studies showcase the competitive accuracy of Vision Transformers (ViTs) in relation to Convolutional Neural Networks (CNNs), along with their remarkable robustness. However, ViTs demand a large amount of data to achieve adequate performance, which makes their application to small datasets challenging, falling behind CNNs. To overcome this, we propose GenFormer, a data augmentation strategy utilizing generated images, thereby improving transformer accuracy and robustness on small-scale image classification tasks. In our comprehensive evaluation we propose Tiny ImageNetV2, -R, and -A as new test set variants of Tiny ImageNet by transferring established ImageNet generalization and robustness benchmarks to the small-scale data domain. Similarly, we introduce MedMNIST-C and EuroSAT-C as corrupted test set variants of established fine-grained datasets in the medical and aerial domain. Through a series of experiments conducted on small datasets of various domains, including Tiny ImageNet, CIFAR, EuroSAT and MedMNIST datasets, we demonstrate the synergistic power of our method, in particular when combined with common train and test time augmentations, knowledge distillation, and architectural design choices. Additionally, we prove the effectiveness of our approach under challenging conditions with limited training data, demonstrating significant improvements in both accuracy and robustness, bridging the gap between CNNs and ViTs in the small-scale dataset domain.