 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGHaLIB: A Multilingual Framework for Hope Speech Detection in Low-Resource Languages
Dec 27, 2025Hope speech has been relatively underrepresented in Natural Language Processing (NLP). Current studies are largely focused on English, which has resulted in a lack of resources for low-resource languages such as Urdu. As a result, the creation of tools that facilitate positive online communication remains limited. Although transformer-based architectures have proven to be effective in detecting hate and offensive speech, little has been done to apply them to hope speech or, more generally, to test them across a variety of linguistic settings. This paper presents a multilingual framework for hope speech detection with a focus on Urdu. Using pretrained transformer models such as XLM-RoBERTa, mBERT, EuroBERT, and UrduBERT, we apply simple preprocessing and train classifiers for improved results. Evaluations on the PolyHope-M 2025 benchmark demonstrate strong performance, achieving F1-scores of 95.2% for Urdu binary classification and 65.2% for Urdu multi-class classification, with similarly competitive results in Spanish, German, and English. These results highlight the possibility of implementing existing multilingual models in low-resource environments, thus making it easier to identify hope speech and helping to build a more constructive digital discourse.
Linking Faces and Voices Across Languages: Insights from the FAME 2026 Challenge
Dec 23, 2025Over half of the world's population is bilingual and people often communicate under multilingual scenarios. The Face-Voice Association in Multilingual Environments (FAME) 2026 Challenge, held at ICASSP 2026, focuses on developing methods for face-voice association that are effective when the language at test-time is different than the training one. This report provides a brief summary of the challenge.
Boosting Few-Shot Detection with Large Language Models and Layout-to-Image Synthesis
Oct 09, 2024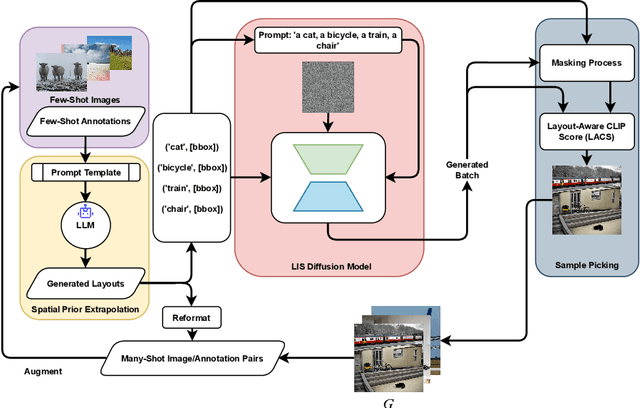

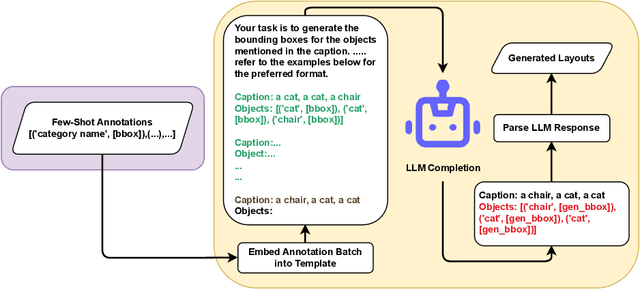

Recent advancements in diffusion models have enabled a wide range of works exploiting their ability to generate high-volume, high-quality data for use in various downstream tasks. One subclass of such models, dubbed Layout-to-Image Synthesis (LIS), learns to generate images conditioned on a spatial layout (bounding boxes, masks, poses, etc.) and has shown a promising ability to generate realistic images, albeit with limited layout-adherence. Moreover, the question of how to effectively transfer those models for scalable augmentation of few-shot detection data remains unanswered. Thus, we propose a collaborative framework employing a Large Language Model (LLM) and an LIS model for enhancing few-shot detection beyond state-of-the-art generative augmentation approaches. We leverage LLM's reasoning ability to extrapolate the spatial prior of the annotation space by generating new bounding boxes given only a few example annotations. Additionally, we introduce our novel layout-aware CLIP score for sample ranking, enabling tight coupling between generated layouts and images. Significant improvements on COCO few-shot benchmarks are observed. With our approach, a YOLOX-S baseline is boosted by more than 140%, 50%, 35% in mAP on the COCO 5-,10-, and 30-shot settings, respectively.
GenFormer -- Generated Images are All You Need to Improve Robustness of Transformers on Small Datasets
Aug 27, 2024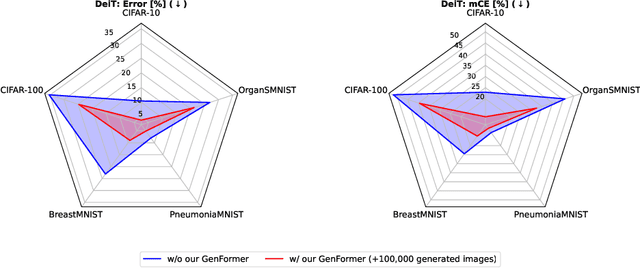
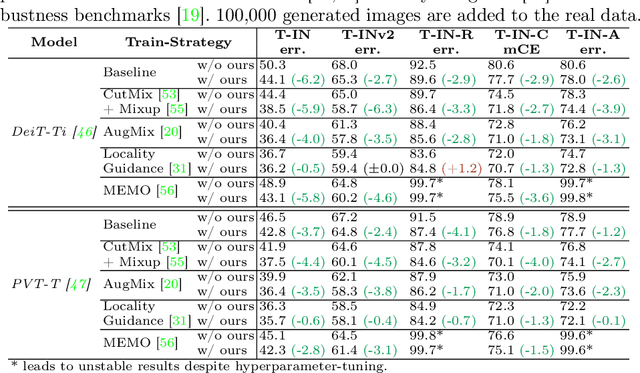
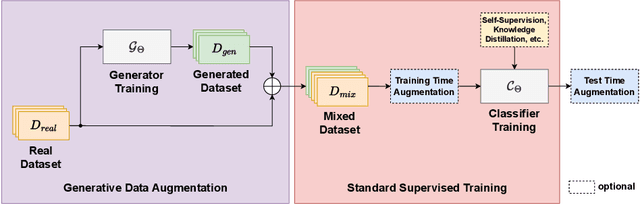
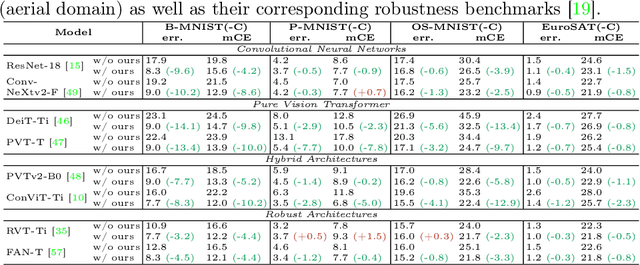
Recent studies showcase the competitive accuracy of Vision Transformers (ViTs) in relation to Convolutional Neural Networks (CNNs), along with their remarkable robustness. However, ViTs demand a large amount of data to achieve adequate performance, which makes their application to small datasets challenging, falling behind CNNs. To overcome this, we propose GenFormer, a data augmentation strategy utilizing generated images, thereby improving transformer accuracy and robustness on small-scale image classification tasks. In our comprehensive evaluation we propose Tiny ImageNetV2, -R, and -A as new test set variants of Tiny ImageNet by transferring established ImageNet generalization and robustness benchmarks to the small-scale data domain. Similarly, we introduce MedMNIST-C and EuroSAT-C as corrupted test set variants of established fine-grained datasets in the medical and aerial domain. Through a series of experiments conducted on small datasets of various domains, including Tiny ImageNet, CIFAR, EuroSAT and MedMNIST datasets, we demonstrate the synergistic power of our method, in particular when combined with common train and test time augmentations, knowledge distillation, and architectural design choices. Additionally, we prove the effectiveness of our approach under challenging conditions with limited training data, demonstrating significant improvements in both accuracy and robustness, bridging the gap between CNNs and ViTs in the small-scale dataset domain.