 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Few-Shot Detection with Large Language Models and Layout-to-Image Synthesis
Paper and Code
Oct 09, 2024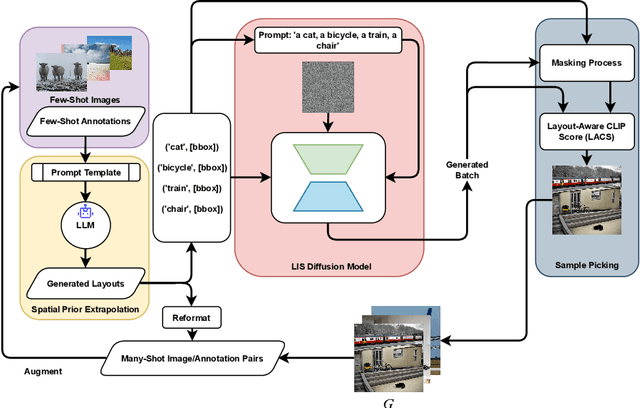

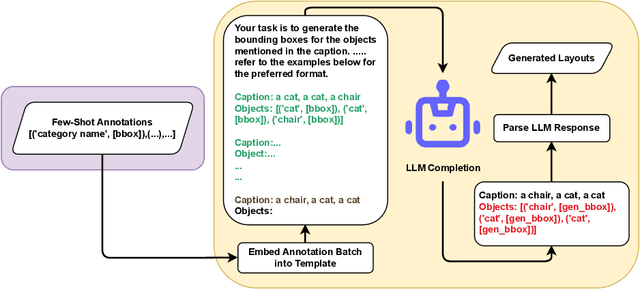

Recent advancements in diffusion models have enabled a wide range of works exploiting their ability to generate high-volume, high-quality data for use in various downstream tasks. One subclass of such models, dubbed Layout-to-Image Synthesis (LIS), learns to generate images conditioned on a spatial layout (bounding boxes, masks, poses, etc.) and has shown a promising ability to generate realistic images, albeit with limited layout-adherence. Moreover, the question of how to effectively transfer those models for scalable augmentation of few-shot detection data remains unanswered. Thus, we propose a collaborative framework employing a Large Language Model (LLM) and an LIS model for enhancing few-shot detection beyond state-of-the-art generative augmentation approaches. We leverage LLM's reasoning ability to extrapolate the spatial prior of the annotation space by generating new bounding boxes given only a few example annotations. Additionally, we introduce our novel layout-aware CLIP score for sample ranking, enabling tight coupling between generated layouts and images. Significant improvements on COCO few-shot benchmarks are observed. With our approach, a YOLOX-S baseline is boosted by more than 140%, 50%, 35% in mAP on the COCO 5-,10-, and 30-shot settings, respectively.